Dremio
A comprehensive guide to Dremio, the Intelligent Lakehouse Platform that provides a unified semantic layer, high-performance SQL query engine, and governed access layer for Apache Iceberg-based data lakehouses.
The Lakehouse Platform Built for the Open Ecosystem
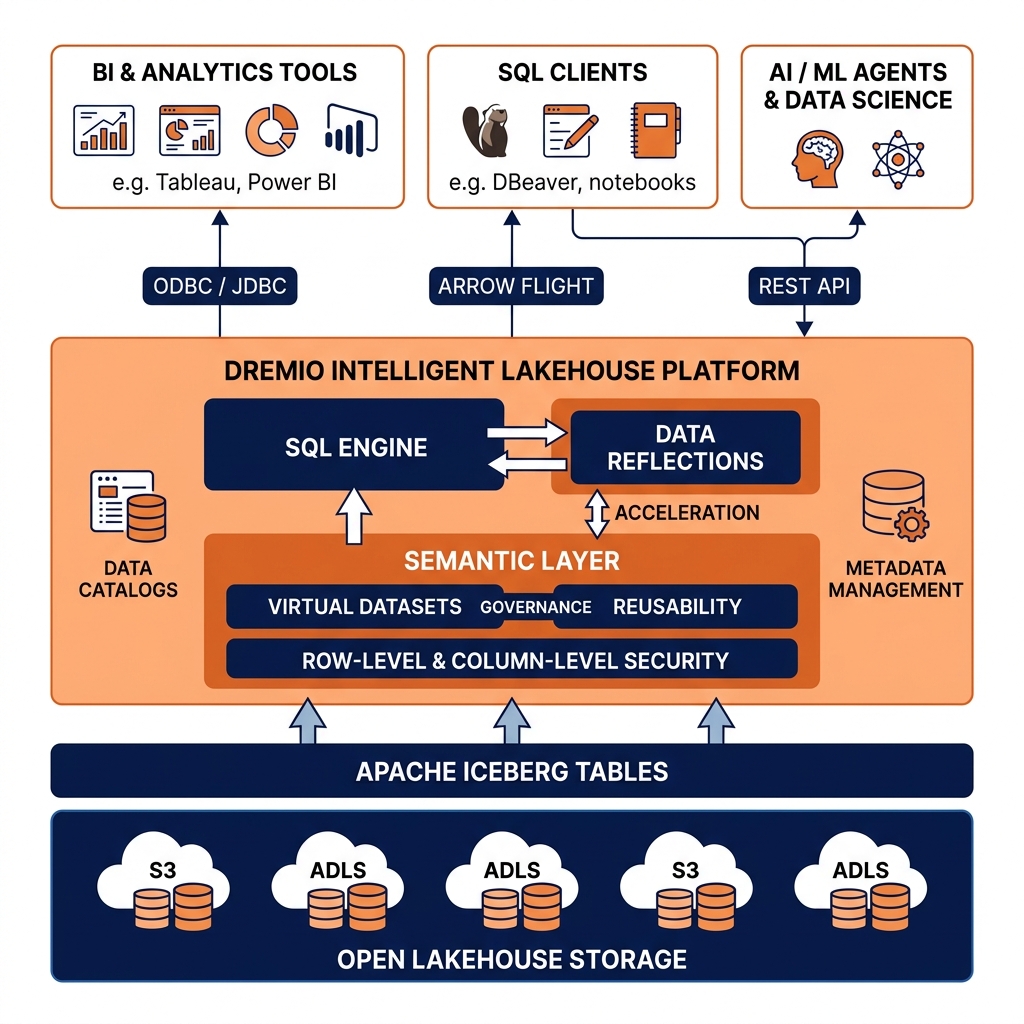
Dremio is an enterprise data lakehouse platform built natively around open standards: Apache Iceberg for table format, Apache Arrow for in-memory processing, Apache Parquet for storage, and the Iceberg REST Catalog API for catalog integration. Unlike traditional data warehouse platforms that couple storage and compute into proprietary systems, Dremio operates as a pure compute and semantic layer above open object storage, enabling organizations to query, govern, and optimize their data without vendor lock-in to a proprietary storage format.
Dremio’s core capabilities span four primary functions in the modern lakehouse architecture: a high-performance distributed SQL query engine, a business-ready Semantic Layer for governed data access, an intelligent query acceleration mechanism through Data Reflections, and integrated Iceberg table management for data lifecycle operations.
The Dremio SQL Query Engine
Dremio’s SQL query engine is built on Apache Arrow’s columnar in-memory format and designed for maximum analytical query performance against data stored in cloud object storage. The engine implements a Massively Parallel Processing (MPP) architecture that distributes query execution across multiple worker nodes, each reading and processing Parquet data files in parallel using Arrow’s vectorized execution model.
When a query is submitted to Dremio, the query planner reads the Apache Iceberg metadata for the relevant tables, applies metadata-level pruning (using Iceberg’s partition statistics and file-level column statistics) to eliminate irrelevant data files before a single byte of actual data is read, and generates an optimized distributed execution plan. The plan is distributed to multiple executor nodes, each of which reads its assigned Parquet files from object storage directly (without moving data through a central coordinator), decodes the columnar Parquet data into Arrow buffers, and applies local filter, projection, and aggregation operations in parallel. Partial results are shuffled and merged to produce the final query result.
This architecture delivers interactive query performance (sub-second to low-second latency for typical BI queries) against petabyte-scale Iceberg tables stored in commodity cloud object storage, without the cost overhead of loading data into a proprietary managed warehouse format.
The Semantic Layer: Business-Ready Data Views
Dremio’s Semantic Layer allows data engineers to build Virtual Datasets on top of physical Iceberg tables. A Virtual Dataset is a named, versioned SQL view that can join multiple physical tables, apply business logic transformations, define calculated metrics, rename columns to business-friendly names, and apply security policies.
Unlike traditional database views, Dremio’s Virtual Datasets are first-class governed assets that appear in Dremio’s catalog alongside physical Iceberg tables. They can be discovered, documented, and governed through the same mechanisms as physical tables. BI tools connecting to Dremio through ODBC or JDBC see Virtual Datasets as regular tables and can build reports against them without knowing the underlying physical table structure.
Row-Level Security policies on Virtual Datasets restrict which rows each user or role can see. Column Masking policies automatically replace PII column values with masked versions for users without elevated access. These policies are evaluated at query time by Dremio’s engine, enforced consistently regardless of which BI tool, SQL client, or API the user employs.
Data Reflections: Intelligent Query Acceleration
Dremio Data Reflections are pre-computed aggregations and materializations managed automatically by Dremio to accelerate queries against Virtual Datasets and physical Iceberg tables. When a Reflection is defined for a Virtual Dataset, Dremio computes the materialized result of the Reflection query and stores it as an optimized Apache Iceberg table in the data lakehouse. Subsequent queries that can be answered from the Reflection are automatically routed to the Reflection rather than the original source, delivering near-instant query performance regardless of source data size.
Critically, Reflections are transparent to query authors. Users query the original Virtual Dataset or physical table; Dremio’s query planner determines whether a Reflection can satisfy the query and rewrites the execution plan to use the Reflection without any user awareness or intervention. This differs from traditional materialized views, which require users to explicitly query the view rather than the source table.
Reflections can be configured as raw Reflections (materializing a filtered and projected subset of the source data), aggregation Reflections (pre-computing GROUP BY aggregations), or sort order Reflections (pre-sorting the data for faster range filter evaluation). Multiple Reflections can exist for the same source, with Dremio’s optimizer selecting the most efficient one for each query.
Iceberg Table Management
Dremio includes integrated Iceberg table management capabilities, including table creation and schema management through standard SQL DDL, data compaction (automatically merging small Parquet files to improve query performance), snapshot expiration (removing old snapshots while respecting retention policies), and statistics collection (computing and updating column-level statistics used by Dremio’s query planner).
This integrated management reduces the operational overhead of running a production Iceberg lakehouse. Rather than maintaining separate Spark jobs for compaction and maintenance, data engineering teams can manage these lifecycle operations directly through Dremio’s SQL interface or through its automated table maintenance scheduling.
Dremio Cloud, the managed SaaS version of Dremio, provides additional operational benefits including elastic compute scaling, automatic software updates, built-in Project Nessie-based catalog branching through Arctic, and integrated connector management for popular data sources.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.