Compaction
A guide to compaction in Apache Iceberg and data lakehouses, the critical table maintenance operation that merges small files into optimally sized Parquet files to restore query performance degraded by high-frequency writes.
The Small File Problem
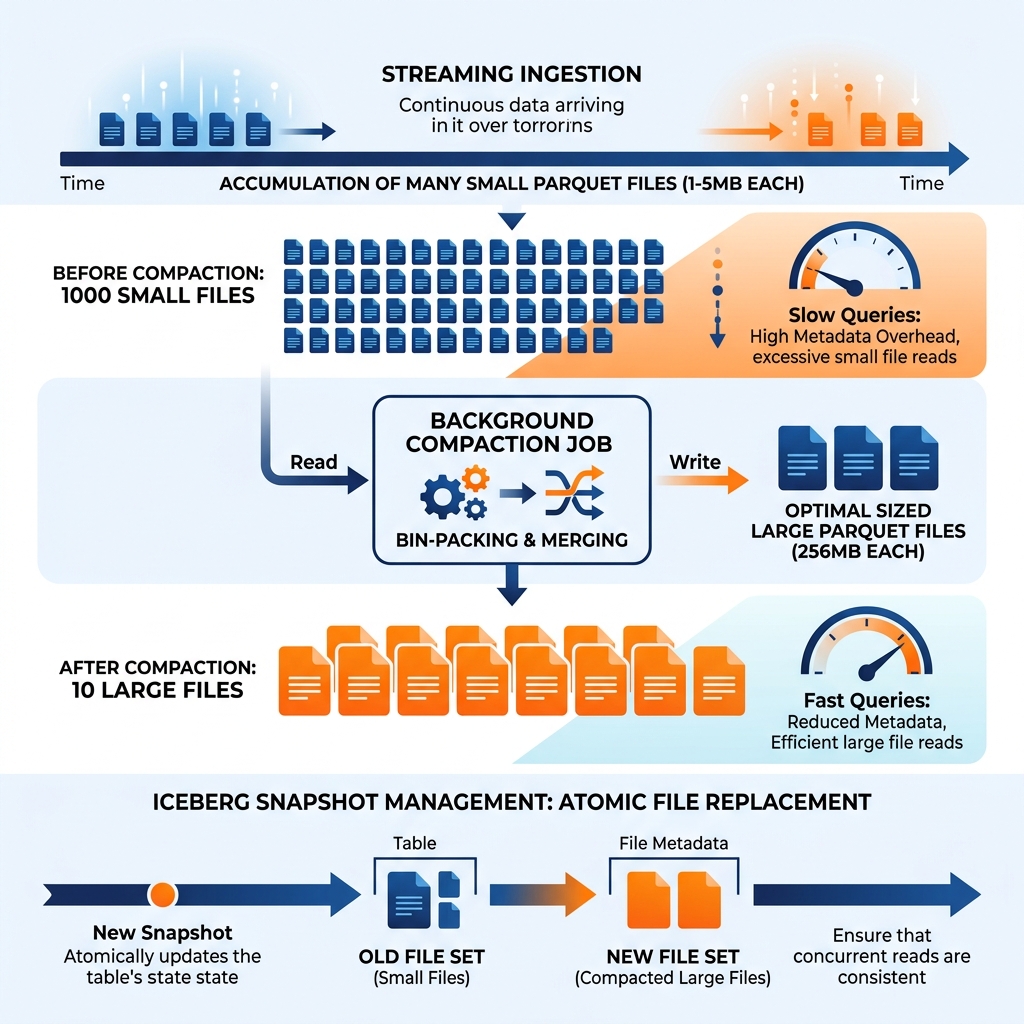
Cloud object storage imposes a per-request overhead on every read operation regardless of the object’s size. Reading 1,000 small 1MB Parquet files requires 1,000 separate object storage API calls, each with its own authentication, DNS lookup, TCP connection, and TLS handshake overhead. Reading 10 files of 100MB each for the equivalent 1GB total data requires only 10 API calls. The 1,000-file scenario is dramatically slower than the 10-file scenario even when the total data volume is identical.
Streaming ingestion pipelines naturally produce small files. Apache Flink writing Kafka events to an Iceberg table commits a new snapshot every 5 minutes, producing a batch of small Parquet files per commit interval. A table receiving events from 20 Flink jobs simultaneously accumulates 20 small files per commit interval, amounting to 5,760 small files per day. After weeks of streaming ingestion without compaction, a table might contain hundreds of thousands of files, each a few megabytes in size. Query performance against such a table degrades dramatically: a full table scan requires hundreds of thousands of API calls, and even filtered queries that use partition pruning still hit thousands of small files within each partition.
Compaction is the maintenance operation that resolves this small file accumulation. A compaction job reads groups of small Parquet files belonging to the same table, merges their records into new, optimally sized Parquet files (typically 128MB to 1GB depending on the use case), and commits the new file set as a new Iceberg snapshot. The original small files are removed from the active snapshot (though retained for historical snapshots until they expire). After compaction, the table’s file count is dramatically reduced and query performance is restored.
Iceberg Compaction API
Apache Iceberg provides the rewrite_data_files stored procedure for compaction, available through Spark SQL and other engines. The procedure reads all data files in the target table (or a specified subset filtered by partition), rewrites them as new optimally sized files, and commits the result as a new snapshot in a single atomic operation. If the compaction job fails partway through, the partially written new files are simply abandoned and the original files remain active in the snapshot, providing crash safety.
The rewrite_data_files procedure accepts configuration for target file size, minimum and maximum file sizes to include in the rewrite, and the rewrite strategy (binpack for simple size optimization, sort for sort-order-preserving rewrites, or z-order for multi-dimensional clustering). Binpack compaction is the most common choice for addressing the small file problem without sorting overhead.
Spark’s rewrite_data_files can process a table in parallel across multiple Spark executors, compacting different partitions simultaneously. For tables with many partitions, this parallel compaction completes significantly faster than serial partition-by-partition compaction.
Scheduling Compaction
Compaction should run on a regular schedule for tables receiving continuous streaming writes. The appropriate compaction frequency depends on the write rate and the acceptable query performance degradation between compaction runs.
For high-frequency streaming tables, Apache Airflow DAGs typically schedule compaction every few hours using the SparkSubmitOperator to launch a Spark compaction job. Alternatively, Spark Structured Streaming’s built-in compaction trigger can run compaction in the background during streaming job idle periods.
Dremio Cloud provides integrated table optimization operations (combining compaction with statistics collection) that can be scheduled through Dremio’s SQL interface with a simple OPTIMIZE TABLE command. This integration eliminates the need for a separate Spark cluster to run compaction, simplifying operations for Dremio-centric lakehouse architectures.
After compaction, old snapshot files accumulate in the Iceberg metadata layer, tracking the complete history of the table through its compaction events. These historical snapshots enable time travel but consume storage. Snapshot expiration (vacuuming old snapshots) is the complementary maintenance operation that cleans up the historical metadata and data files that are no longer needed.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.