Apache Iceberg
The definitive open table format for the data lakehouse, enabling ACID transactions, hidden partitioning, and schema evolution at massive scale.
The Hive Bottleneck and the Birth of Iceberg
Before the advent of modern open table formats, the data engineering industry relied heavily on the Apache Hive table layout to impose structure onto data lakes. Hive was revolutionary when it was introduced, as it provided a SQL-like interface over Hadoop Distributed File System (HDFS) and later cloud object storage. It established a standard for organizing massive volumes of raw data files into logical tables. However, the architectural design of Hive was fundamentally incompatible with the extreme scale and performance requirements of the modern cloud era.
The primary flaw of the Hive architecture is its reliance on directory-based tracking. In a Hive table, partitions are represented as physical folders in the file system (e.g., year=2026/month=05/day=17/). When a compute engine, such as Apache Spark or Presto, needed to query a specific partition, it was forced to execute an O(N) directory listing operation to discover all the underlying data files inside that folder. On local HDFS, this directory listing was relatively fast. However, when the industry migrated to cloud object storage like Amazon S3 or Google Cloud Storage, this architecture collapsed. Cloud object stores are not true hierarchical file systems; they are flat namespaces that simulate folders. Executing an API call to list thousands of objects across hundreds of pseudo-directories is an incredibly slow and expensive network operation. A query execution plan that should take milliseconds often spent several minutes simply listing files before reading a single byte of actual data.
Furthermore, Hive lacked any mechanism for safe, concurrent writes. Because the catalog only tracked data at the directory level, if two data pipelines attempted to write files to the same partition simultaneously, they risked catastrophic data corruption. A downstream reader might see a partial file, or one process might silently overwrite the files of another. To avoid this, data engineers were forced to orchestrate complex, rigid job schedules to ensure that no two processes ever touched the same table at the same time. The Hive layout was slow, brittle, and incapable of supporting true ACID transactions.
It was within this context of crippling performance bottlenecks that Apache Iceberg was born. Originally engineered at Netflix to solve the massive scalability issues they were experiencing with their petabyte-scale data lakes, Iceberg was designed from the ground up to operate on cloud object storage. Netflix donated the project to the Apache Software Foundation, where it rapidly evolved into the definitive open standard for the data lakehouse.
The fundamental philosophical shift introduced by Apache Iceberg is the move from directory-based tracking to file-level tracking. Iceberg completely abandons the concept of using physical folders to define table partitions. Instead, it maintains a strict, hierarchical metadata tree that explicitly tracks the exact path, size, and statistics of every single data file that belongs to the table. By shifting the responsibility of table definition from the physical file system to a structured metadata layer, Iceberg decoupled the logical table from its physical storage, unlocking unprecedented performance, reliability, and flexibility.
The Core Architecture of Apache Iceberg
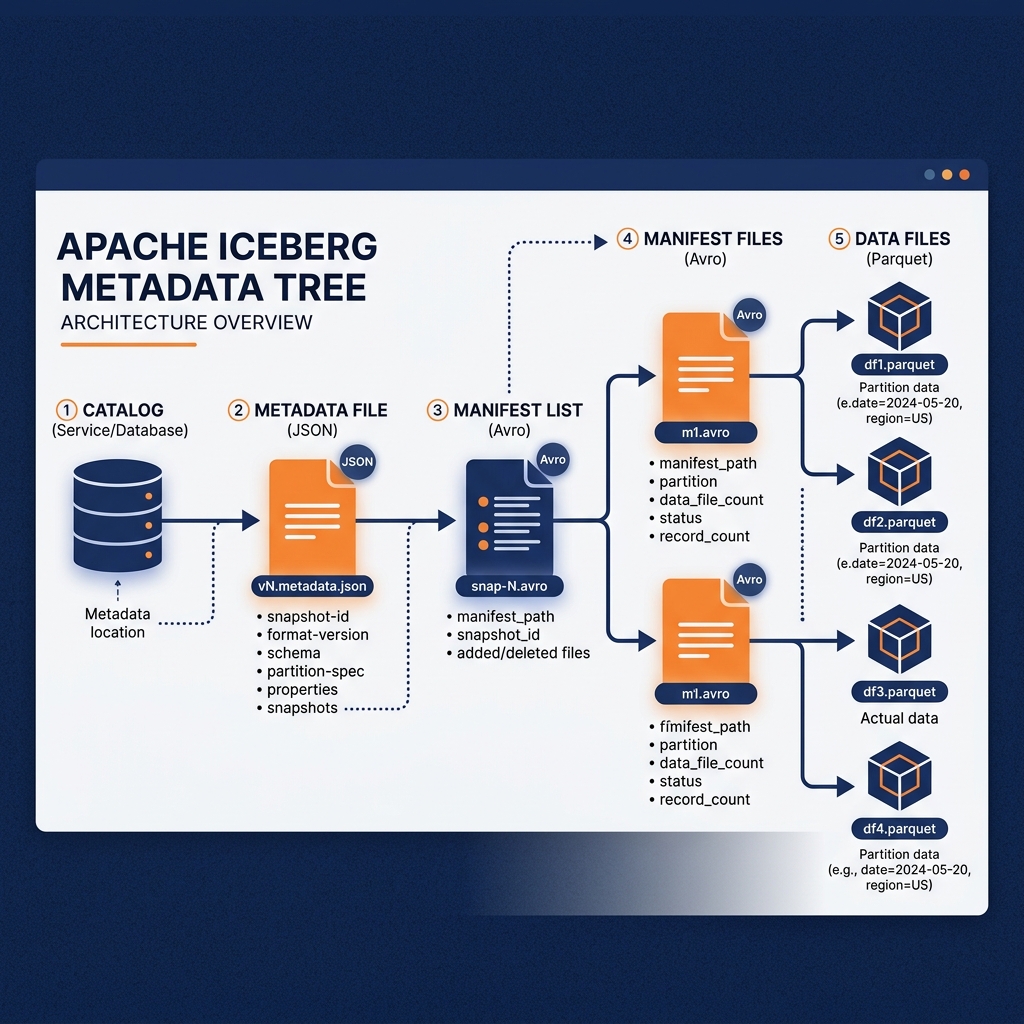
To understand why Apache Iceberg is capable of delivering data warehouse performance on raw object storage, one must examine its elegant, tiered metadata architecture. An Iceberg table is not a single file, but rather a structured hierarchy consisting of the catalog, metadata files, manifest lists, manifest files, and finally, the actual data files.
The Metadata Tree
At the absolute root of the architecture is the Catalog. The catalog acts as the central registry. When a compute engine wants to read an Iceberg table, it asks the catalog for the location of the table’s current metadata file.
The Metadata File (typically stored in JSON format) is the definitive source of truth for the table’s state at a specific point in time. It defines the table’s schema (the names, types, and IDs of every column), the partitioning specification, and a list of historical snapshots. Most importantly, it contains a pointer to the current snapshot.
A Snapshot represents the complete, immutable state of the table at the exact millisecond a transaction occurred. Every time a user executes an INSERT, UPDATE, or DELETE, Iceberg generates a brand new snapshot. The snapshot points directly to a Manifest List.
The Manifest List (stored in Avro format) is an index of manifest files. It tracks which manifest files belong to the current snapshot and contains high-level statistics about those manifests, such as the range of partition values they contain. This allows the query engine to immediately discard entire manifest files if they do not match the query filters.
Finally, the Manifest File (also stored in Avro) is the lowest level of the metadata tree. It contains the exact physical paths to the underlying data files (typically Parquet, ORC, or Avro). Crucially, the manifest file also stores extremely granular, column-level statistics for every single data file it references. It tracks the minimum value, maximum value, null count, and total record count for every column within the physical data file.
Metadata-Driven File Pruning
This complex metadata hierarchy exists for one singular purpose: aggressive file pruning. In the legacy Hive architecture, a query engine had to list directories and often open individual Parquet files just to read the footers and determine if the file contained relevant data.
With Apache Iceberg, the query engine performs all of its filtering on the metadata tree before it ever touches a data file. If a user runs a SQL query requesting all transactions where the purchase_amount > 1000, the engine reads the Manifest File. It examines the minimum and maximum statistics for the purchase_amount column for every listed data file. If a data file’s maximum value is 500, the engine instantly knows the file cannot possibly contain relevant records. The engine prunes that file from its execution plan entirely.
Because the metadata files are significantly smaller than the actual data files, this evaluation occurs in milliseconds. By the time the engine actually reaches out to the cloud object storage, it has surgical precision, downloading only the exact Parquet files that contain the required records. This metadata-first approach eliminates the O(N) directory listing bottleneck entirely, allowing Iceberg to maintain sub-second query performance even when a table scales to millions of individual data files.
Beyond its performance benefits, Apache Iceberg solves two of the most notorious operational nightmares in data engineering: managing partitions and evolving table schemas over time. In legacy architectures, these operations were complex, error-prone, and often required massive, multi-day data rewrites. Iceberg transforms them into seamless, instantaneous metadata operations.
Hidden Partitioning
Partitioning is the practice of grouping similar rows together to speed up queries. If a table contains ten years of sales data, partitioning the table by year allows a query looking for 2026 data to ignore the preceding nine years. However, in traditional systems like Hive, partitioning was explicit and brittle.
If a data engineer wanted to partition a timestamp column by month, they had to create a brand new, physical column (e.g., event_month) and extract the month string from the timestamp during the ETL process. The fatal flaw of this approach was that the end-user (the analyst writing the SQL query) had to know that this artificial event_month column existed. If the analyst queried the original timestamp column without explicitly filtering on the event_month column, the database would fail to recognize the partition strategy and would execute a catastrophic, full-table scan, crashing the cluster.
Apache Iceberg introduces the concept of Hidden Partitioning. In Iceberg, the data engineer defines a partition transformation rule directly at the table level (e.g., “partition the event_timestamp column by month”). The engineer does not create a new column, and the ETL pipeline does not need to extract values. Iceberg handles the partition routing automatically under the hood.
When an analyst runs a query filtering on the raw event_timestamp (e.g., WHERE event_timestamp >= '2026-05-01'), the Iceberg metadata layer automatically translates that filter into the appropriate partition boundary and prunes the irrelevant files. The partitioning strategy is completely hidden from the consumer. This ensures that queries are always highly optimized, regardless of whether the analyst understands the physical layout of the data. Furthermore, Iceberg allows partition evolution. An engineer can change the partition strategy from monthly to daily as data volume grows, and Iceberg will seamlessly query both the old monthly files and the new daily files without requiring a rewrite of historical data.
Schema Evolution
Data is never static. Business requirements constantly evolve, necessitating the addition of new columns, the renaming of existing fields, and the alteration of data types. In a traditional data warehouse, executing a schema migration on a billion-row table is a terrifying prospect. Dropping a column or changing a data type often requires locking the table, creating a new table with the updated schema, and copying all one billion rows over, a process that can take hours or days of downtime.
Iceberg makes schema evolution a safe, instantaneous operation by decoupling the logical column name from the physical data. When a column is created in an Iceberg table, it is assigned a unique, immutable integer ID (e.g., column_id: 4). The physical Parquet files store the data tagged with this integer ID, while the Iceberg metadata file maps the human-readable name (e.g., customer_email) to the ID.
If a data engineer decides to rename customer_email to contact_email, Iceberg simply updates the JSON metadata file to map the new name to column_id: 4. The underlying Parquet files are completely untouched. If the engineer drops the column, Iceberg simply stops mapping the name to the ID in the metadata, rendering the data invisible to future queries. If they later add a new column named customer_email, Iceberg assigns it a brand new ID (e.g., column_id: 12). This prevents the dangerous “zombie data” problem where a dropped column’s old data suddenly reappears when a new column with the exact same name is created. With Iceberg, data engineers can add, drop, rename, and reorder columns instantly, with absolute confidence and zero downtime.
Concurrency, ACID Transactions, and Time Travel
The primary requirement for upgrading a data lake into a data lakehouse is the ability to guarantee transactional consistency. A system cannot serve as a reliable foundation for business intelligence if concurrent reads and writes result in data corruption. Apache Iceberg solves this by introducing robust ACID (Atomicity, Consistency, Isolation, Durability) transactions directly onto immutable object storage.
Optimistic Concurrency Control (OCC)
Iceberg ensures transactional safety through a mechanism known as Optimistic Concurrency Control. In a traditional database, if two transactions attempt to modify the same row simultaneously, the database places a pessimistic lock on the row, forcing one transaction to wait. Because Iceberg operates on distributed object storage where granular row-level locking is impossible, it assumes that conflicts will be rare (optimistic) and resolves them at the catalog level during the commit phase.
When a compute engine, such as Apache Flink or Spark, wants to write data to an Iceberg table, it begins by reading the current metadata file to establish a baseline snapshot. It then writes its new Parquet data files and generates a new manifest file. Finally, it attempts to commit a new metadata file to the catalog.
If two processes attempt to commit at the exact same millisecond, the catalog steps in. The catalog enforces a strict, atomic swap operation. It allows the first process to successfully update the catalog pointer to its new metadata file. The second process will see that the baseline snapshot it started with is no longer the current snapshot. The catalog rejects the second commit. The second process must then read the new metadata file, verify that its changes do not logically conflict with the first process’s changes, and retry the commit. This OCC mechanism guarantees that no two processes can ever silently overwrite each other’s data, ensuring absolute consistency even in massive, high-velocity streaming environments.
The Power of Time Travel
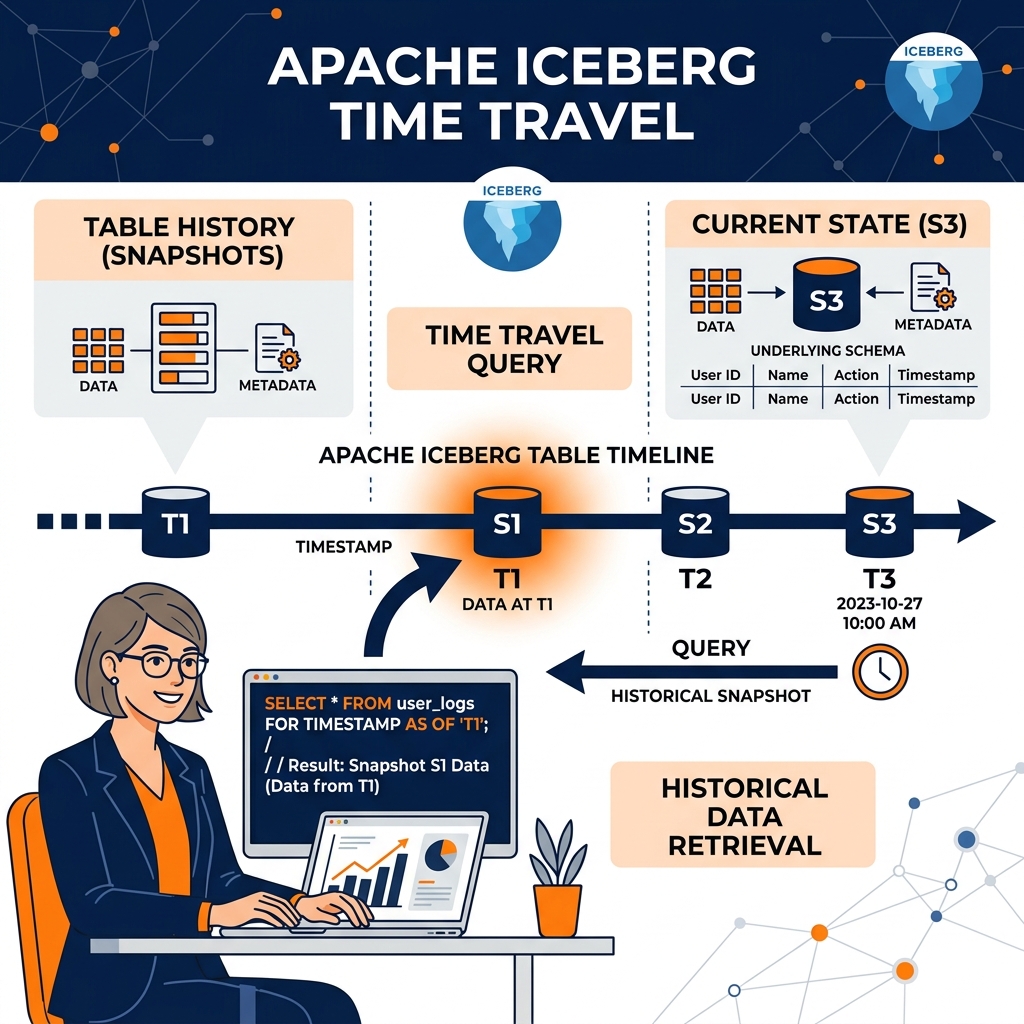
Because Iceberg uses a snapshot-based architecture where data files are never overwritten in place (they are simply dereferenced from the current metadata tree), it inherently maintains a full historical record of the table’s state. This enables one of Iceberg’s most powerful features: Time Travel.
Time Travel allows an analyst or a machine learning model to query the exact state of a table as it existed at any specific point in the past. If a financial auditor needs to understand why a quarterly report generated on March 1st displayed a specific revenue figure, they do not need to rely on outdated, static CSV exports. They simply append FOR SYSTEM_TIME AS OF '2026-03-01' to their SQL query. The Iceberg engine navigates the metadata tree, locates the snapshot that was active on that exact date, and reads only the data files that belonged to that snapshot.
This capability is revolutionary for data science. Machine learning models require absolute reproducibility. If a data scientist trains a model on a dataset that is constantly receiving live updates, they will never be able to reproduce their training results a week later. With Iceberg time travel, the data scientist can pin their training job to a specific snapshot ID, ensuring that their model training pipeline will execute against the exact same bytes of data every single time, regardless of how much new data has been ingested into the table. Time Travel also provides the ultimate safety net for data engineering; if a pipeline accidentally corrupts a table, engineers can simply execute a rollback command, reverting the catalog pointer to the previous, healthy snapshot in a matter of milliseconds.
While the Iceberg metadata tree defines the structure of an individual table, the Catalog is the critical component that manages the entire ecosystem. The catalog is the arbiter of concurrency, the enforcer of security, and the central discovery mechanism for compute engines. As Iceberg adoption surged, the industry realized that the choice of catalog profoundly impacts the capabilities of the lakehouse.
Multi-Table Transactions with Project Nessie
While standard Iceberg catalogs ensure ACID compliance for a single table, many data engineering workflows require modifications across multiple tables simultaneously. If a pipeline updates a Customers table and an Orders table, and a failure occurs halfway through, the lakehouse could be left in an inconsistent state where the orders reflect the new data, but the customer records do not.
Project Nessie was developed to bring Git-like version control semantics to the data lakehouse. Nessie operates as an advanced Iceberg catalog that supports branching and tagging across the entire catalog level. A data engineer can create a branch of the production data, just as a software developer creates a branch of code. They can execute massive, multi-table transformations on the branch in complete isolation. Analysts querying the main branch will remain completely unaffected by the experimental changes. Once the data quality is verified, the engineer can merge the branch back into main via a single, atomic operation. This multi-table transactional guarantee ensures that downstream dashboards always see a perfectly synchronized view of the enterprise data.
Unified Governance with Apache Polaris
The primary danger of the rapidly expanding Iceberg ecosystem was catalog fragmentation. Different query engines (Spark, Trino, Snowflake) often preferred their own proprietary catalog implementations. If an organization used multiple catalogs, they lost the ability to enforce consistent security policies, and tables became siloed.
Apache Polaris was introduced to solve this fragmentation by establishing an open, vendor-neutral standard for the Iceberg Catalog layer. Polaris implements the official Iceberg REST API, guaranteeing that any compliant compute engine can seamlessly connect and query the data. More importantly, Polaris centralizes Role-Based Access Control (RBAC). Security administrators can define a policy in Polaris dictating that a specific data science team is only allowed to read the Sales table and is prohibited from viewing the HR table. Because Polaris acts as the universal gatekeeper, this security policy is strictly enforced regardless of whether the data scientist attempts to access the data using a Python script, an Apache Spark cluster, or a Dremio dashboard. Polaris ensures that the open lakehouse remains secure, governed, and completely free from vendor lock-in.
Dremio and the Agentic Lakehouse Ecosystem
Apache Iceberg provides the structural foundation for the data lakehouse, but to unlock its full potential, organizations require a compute engine capable of executing interactive analytics and complex autonomous workflows directly against the metadata. Dremio is specifically architected to serve as the unified query engine and semantic layer for the Iceberg ecosystem.
Accelerating Iceberg with Data Reflections
While Iceberg’s metadata pruning drastically reduces the amount of data scanned from object storage, executing complex SQL joins and aggregations on massive datasets still requires substantial compute resources. Dremio bridges the gap between the open lakehouse and sub-second BI performance through its integration with Iceberg and its proprietary Data Reflections.
When Dremio connects to an Iceberg catalog, it natively understands the metadata tree. It leverages Iceberg’s column-level statistics to aggressively prune files during query planning. Furthermore, Dremio allows data engineers to build virtual datasets within its semantic layer that abstract away the physical complexity of the Iceberg tables. When a Data Reflection (an intelligent, pre-computed materialization) is enabled on a virtual dataset, Dremio automatically manages that Reflection as a hidden Iceberg table under the hood. The Dremio optimizer algebraically matches incoming queries to the Reflection, delivering data warehouse speeds directly on top of the open Iceberg standard. Because Dremio operates on a Zero-ETL philosophy, data is never locked into a proprietary format; it remains accessible to the entire organization.
The Foundation for Agentic Analytics
The convergence of Apache Iceberg and Dremio’s semantic layer is the critical prerequisite for Agentic AI. As organizations deploy autonomous AI agents to reason over their data, these agents require a unified, governed, and blazingly fast access plane.
An AI agent cannot function if it must navigate the chaos of a traditional data swamp, nor can it operate efficiently if it is blocked by the closed APIs of a proprietary data warehouse. By standardizing on Apache Iceberg, organizations create a single, immutable source of truth with a full historical record (Time Travel) that AI agents can trust. By querying through Dremio, the AI agents interact with a logical semantic layer that provides clean, business-ready metrics rather than cryptic physical schemas.
The Iceberg format guarantees that the AI agent’s access is transactionally safe and highly performant, while Dremio ensures the data is governed and easily interpretable. Together, they transform the passive data lakehouse into an active, intelligent data fabric, empowering the next generation of Agentic Analytics to operate autonomously, securely, and at unlimited scale.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.