Object Storage
A guide to object storage, the massively scalable, low-cost storage architecture that underlies modern data lakehouses, and how it differs fundamentally from block and file storage systems.
The Storage Foundation of the Lakehouse
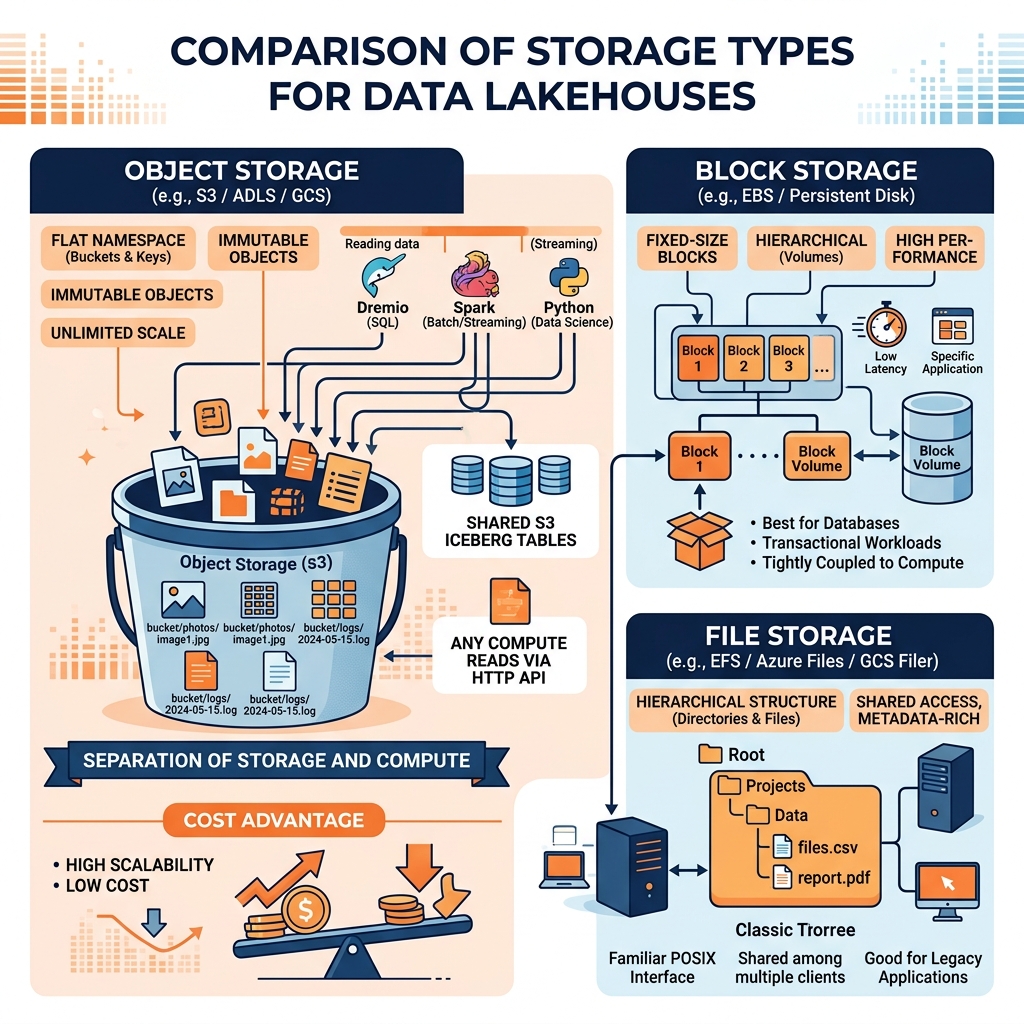
Object storage is the storage architecture that makes the data lakehouse economically viable. Amazon S3, Azure Data Lake Storage (ADLS), and Google Cloud Storage (GCS) are object storage systems that store data as immutable, versioned objects identified by unique keys (paths) rather than as blocks in a block storage device or files in a hierarchical file system.
Understanding the architectural differences between object storage, file storage, and block storage is essential for understanding why the data lakehouse emerged as a viable alternative to the data warehouse and why open table formats like Apache Iceberg were necessary to build ACID semantics on top of it.
Block storage (AWS EBS, Azure Managed Disks) divides storage into fixed-size blocks and presents a raw block device interface to the operating system. The OS manages the file system on top of the block device. Block storage provides low-latency, high-IOPS access patterns suitable for databases and operating system volumes, but it is expensive, limited in scale, and must be attached to specific compute instances.
File storage (NFS, AWS EFS) provides a POSIX-compatible hierarchical file system interface with directory trees, file metadata, and atomic file operations. File storage is more flexible than block storage for shared access patterns but is still expensive at scale and limited in global throughput.
Object storage provides a flat namespace of objects, each identified by a bucket name and an object key (path). Objects are immutable once written; to update an object, a new version is written. Objects can be any size from bytes to terabytes. Object storage is designed for massive horizontal scalability: S3 regularly handles millions of requests per second globally at costs orders of magnitude lower than block or file storage.
Object Storage Characteristics That Shape Lakehouse Design
Several fundamental characteristics of object storage directly shape how data lakehouses are architected and why open table formats like Iceberg exist.
Immutability: Object storage objects are immutable. You cannot modify 100 bytes in the middle of a 1GB Parquet file stored in S3. You can only write a new object with the updated content. This immutability is why Iceberg uses append-only writes and a metadata layer to track the current state of the table: the underlying Parquet files are always immutable, with the Iceberg metadata layer managing which files represent the current table view.
Eventual consistency (historical): Historically, S3’s PUT-then-GET operations were eventually consistent, meaning a newly written object might not be immediately visible to all readers. This required careful engineering in table formats to avoid reading incomplete data. AWS made S3 strongly consistent in December 2020, resolving this issue for new deployments, though the historical consistency challenges motivated much of Iceberg’s metadata design.
High throughput, higher latency: Object storage provides very high aggregate read throughput when reading many objects in parallel but has higher per-object latency than local block storage or NFS. This characteristic motivates partitioning and file sizing strategies that minimize the number of objects that must be read per query: reading 10 large Parquet files is more efficient than reading 10,000 small ones, which is why compaction is an important lakehouse maintenance operation.
Unlimited scalability: Object storage has no practical capacity limit. A lakehouse can grow from gigabytes to exabytes without any storage provisioning changes. S3’s pricing model (pay per GB stored plus per GB retrieved) makes this growth economically linear, unlike proprietary data warehouses where compute and storage are coupled and scale together.
Object Storage and the Separation of Storage and Compute
The most architecturally significant property of object storage for data engineering is its complete separation from compute. Any compute system that can authenticate to S3 (or ADLS or GCS) can read any object in any bucket it is authorized to access, regardless of where the compute is physically located or what cloud provider it runs on.
This separation enables the multi-engine lakehouse architecture. Dremio reads the same Iceberg tables in S3 that Apache Spark writes, and Apache Flink streams into. No data movement between engines is required; all engines share the same physical objects in object storage with coordination managed through the Iceberg catalog. This contrasts with proprietary data warehouses where storage is internal and inaccessible to external engines.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.