Data Lake
An in-depth exploration of the data lake, from its origins in the Hadoop ecosystem to its role in modern cloud object storage, and its evolution into the governed data lakehouse.
The Emergence of the Data Lake
To comprehend the fundamental architecture of the modern data landscape, one must investigate the origins of the data lake. For decades, the relational data warehouse reigned supreme as the undisputed center of enterprise analytics. However, as the digital age accelerated into the late 2000s and early 2010s, organizations encountered a structural crisis commonly referred to as the era of “Big Data.” The sheer volume, velocity, and variety of data being generated by web applications, social media platforms, mobile devices, and IoT sensors began to eclipse the processing capabilities of traditional, on-premises relational databases.
The primary bottleneck of the data warehouse was its strict adherence to schema-on-write. Every byte of incoming telemetry had to be cleansed, normalized, and forced into a highly structured dimensional model before it could be committed to disk. When organizations attempted to ingest massive streams of unstructured JSON logs or raw text data, their ETL pipelines collapsed under the computational weight. Furthermore, the storage components of traditional data warehouses were incredibly expensive. Storing petabytes of raw, historical web logs on premium, proprietary block storage appliances was a financial impossibility for most enterprises. The industry required a radical architectural departure that prioritized infinite scalability, low-cost persistence, and schema flexibility.
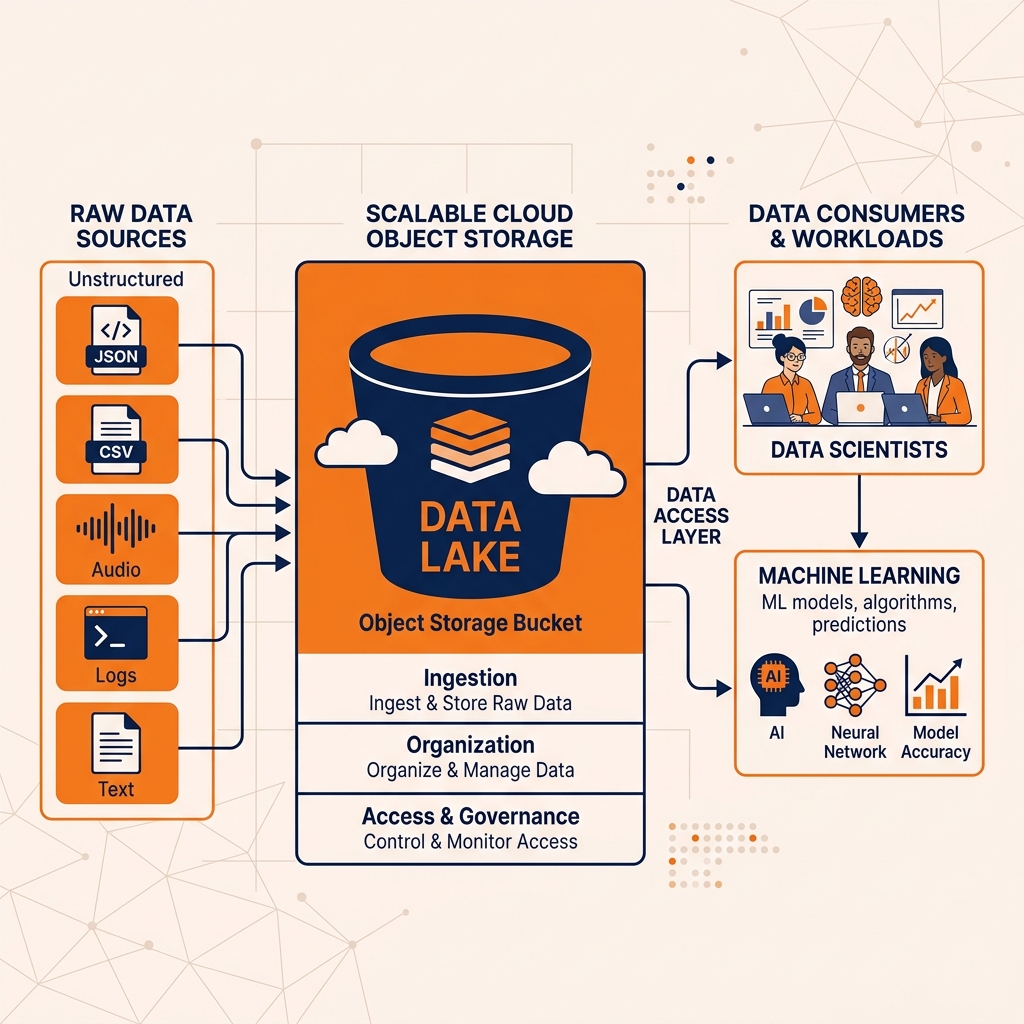
The data lake emerged as the definitive answer to the Big Data crisis. Conceptually, a data lake is a vast, centralized repository designed to store all organizational data in its exact, native, and raw format. Whether the data consists of structured CSV files, semi-structured JSON payloads, or completely unstructured media files, it is simply dumped into the lake without any prior transformation or modeling.
This architectural shift introduced the concept of schema-on-read. Instead of forcing data engineers to define the structure of the data before writing it to disk, the data lake defers the responsibility of structuring the data to the exact moment it is queried by a downstream consumer. When a data scientist or analyst needs to extract value from a specific dataset, they apply their own custom parser, schema, or projection to the raw files at read time. This paradigm decouples data ingestion from data consumption. Data engineering teams are freed from the grueling task of maintaining brittle ETL pipelines just to capture telemetry. They can simply ingest everything as fast as it is generated, ensuring that no historical data is ever discarded due to a lack of immediate analytical utility.
The earliest, most widespread implementation of the data lake was built upon the Apache Hadoop ecosystem, specifically the Hadoop Distributed File System (HDFS). HDFS allowed organizations to construct massive, decentralized storage clusters using commodity hardware. By distributing the storage layer across thousands of cheap, off-the-shelf servers, Hadoop drove the cost of data persistence down to a fraction of what traditional data warehouses charged. HDFS became synonymous with the early data lake, establishing a new baseline for enterprise analytics where the default behavior was to store everything indefinitely and figure out how to analyze it later.
Architecture and Storage Paradigms
While the Hadoop ecosystem successfully democratized Big Data, the architecture of the early data lake was fundamentally flawed. HDFS relied on a tightly coupled cluster architecture where the physical storage layer (the hard drives on the commodity servers) and the compute layer (the MapReduce or YARN processing jobs) existed on the exact same physical hardware.
This tight coupling created profound scaling inefficiencies. If an organization accumulated petabytes of raw telemetry but only executed a handful of analytical queries per day, they were still forced to purchase, rack, and maintain massive numbers of physical servers just to hold the hard drives. They were paying for vast amounts of CPU and RAM that sat completely idle. Conversely, if they needed a sudden burst of computational power to train a machine learning model, they could not add compute nodes without simultaneously triggering a massive, disruptive rebalancing of the physical data blocks across the new servers. The overhead of maintaining on-premises Hadoop clusters eventually became an unbearable operational burden for data engineering teams.
The Shift to Cloud Object Storage
The true architectural maturity of the data lake arrived with the mass migration to the public cloud. Cloud providers introduced object storage services like Amazon Simple Storage Service (S3), Google Cloud Storage (GCS), and Azure Data Lake Storage (ADLS). Cloud object storage replaced HDFS as the undisputed foundation of the modern data lake, fundamentally altering the economics of data engineering.
Object storage abandons the traditional hierarchical file system structure found on local hard drives. Instead, it operates on a flat namespace where data is stored as immutable binary large objects (BLOBs), each identified by a unique cryptographic key. Object storage is engineered for extreme durability (often boasting eleven nines of reliability), global replication, and practically limitless capacity.
The Separation of Compute and Storage
The defining architectural victory of the cloud object storage data lake is the absolute separation of compute and storage. Because the object storage layer is managed entirely by the cloud provider, organizations can store exabytes of historical data for fractions of a cent per gigabyte without provisioning a single CPU core.
When a data engineering team or a data scientist needs to process or query that data, they dynamically provision ephemeral, stateless compute clusters. These compute clusters (whether running Apache Spark, Presto, or Dremio) retrieve the necessary objects from the central storage bucket over a high-bandwidth network, execute the required analytical aggregations in memory, and then immediately shut down when the job concludes. Organizations only pay for the precise seconds of compute time they consume, while their massive data footprint remains safely persisted at rest in the storage bucket. This elasticity resolved the core economic failure of the Hadoop era and solidified the data lake as the permanent, centralized landing zone for all enterprise data.
The Data Swamp Dilemma
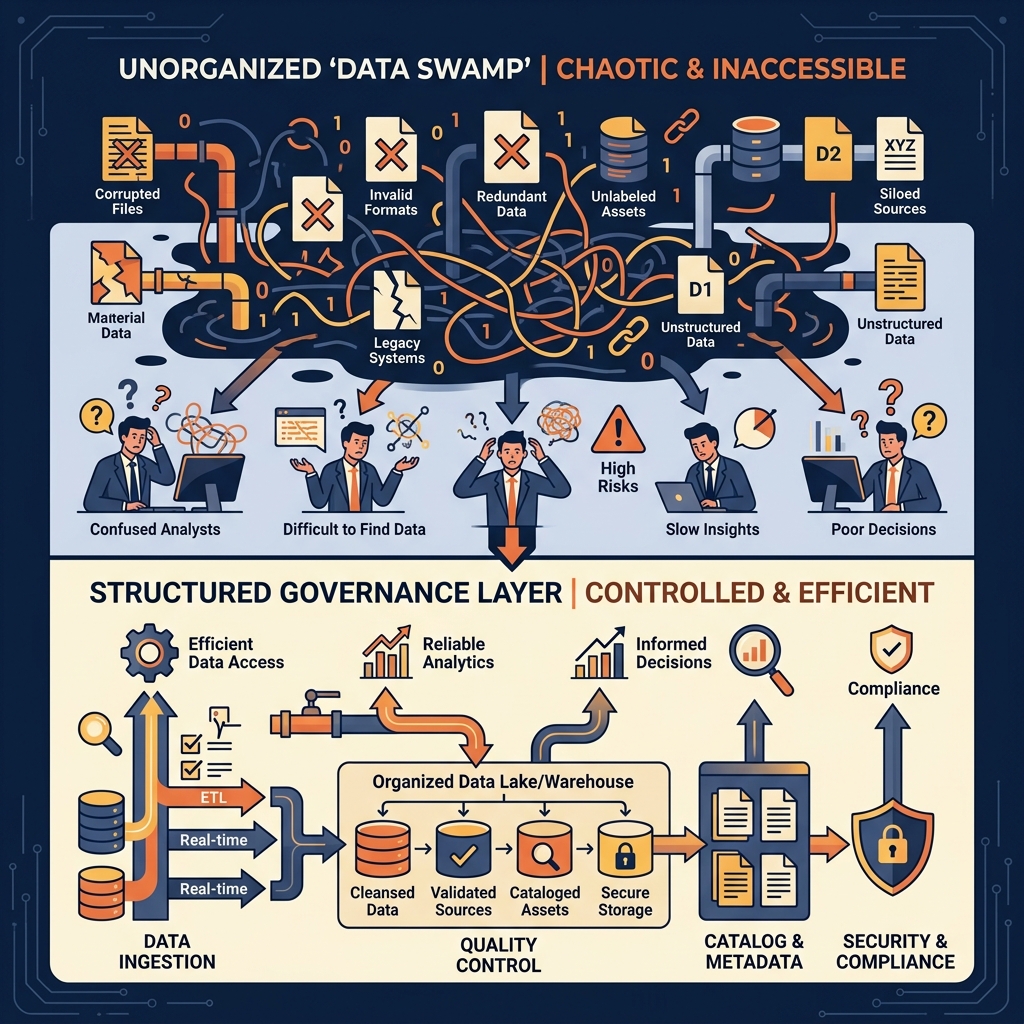
Despite its unparalleled scalability and cost-efficiency, the data lake quickly developed a notorious reputation for organizational chaos. The very flexibility that made the schema-on-read paradigm so attractive, the ability to dump raw data without predefined models, became the source of its most catastrophic failures. Without the rigorous enforcement mechanisms of a relational database, data lakes rapidly degenerated into unmanageable, opaque repositories known as “data swamps.”
The Absence of ACID Transactions
The most significant technical limitation of the raw data lake is the complete absence of ACID (Atomicity, Consistency, Isolation, Durability) guarantees. Cloud object storage systems like Amazon S3 were designed as eventual-consistency blob stores, not transactional databases. They lack native support for atomic operations, record-level locking, or transaction isolation.
In a traditional relational database, if a user attempts to update a record while another user is reading it, the database engine enforces strict isolation levels to ensure the reader sees a consistent, valid state. If a multi-step ETL job fails halfway through, the database automatically rolls back the entire transaction, leaving no trace of the partial failure. The raw data lake possesses none of these protections.
If a data engineering pipeline fails while writing a massive batch of Parquet files to an S3 bucket, the half-written, corrupted files remain in the bucket indefinitely. Any downstream analyst who queries that specific directory will unknowingly incorporate those corrupted files into their business intelligence dashboard, completely destroying the accuracy of their reports. Furthermore, because cloud object storage does not support in-place updates, executing regulatory compliance mandates, such as deleting a specific user’s record to comply with GDPR or CCPA, requires a data engineer to manually read the entire massive object, filter out the specific row, rewrite the entire object back to storage, and delete the original. If another process attempts to read the table while this massive rewrite is occurring, they will encounter read inconsistencies, file-not-found errors, and silent data corruption.
The Collapse of Governance and Discoverability
Beyond the transactional failures, the data swamp is characterized by a complete breakdown of data governance and discoverability. Because data can be ingested in any format by any team, the data lake quickly fills with millions of obscure, undocumented files.
Data engineers frequently struggle to identify which directories contain production-ready telemetry versus which directories are filled with abandoned sandbox experiments left behind by data scientists. Without a centralized catalog enforcing strict metadata requirements, there is no way for an analyst to determine the schema of a file without downloading it and manually inspecting the contents. Column names are often cryptic, data types change unpredictably from one month to the next, and there is no reliable lineage tracking to explain how a specific dataset was generated.
This lack of governance effectively renders the data lake useless for traditional business intelligence workloads. Executive stakeholders cannot rely on financial dashboards powered by a system that routinely suffers from schema drift, missing partitions, and corrupted writes. Consequently, organizations were forced to construct complex two-tier architectures, utilizing the data lake solely as a raw landing zone and spending millions of dollars building brittle ETL pipelines to move a curated subset of that data into a reliable, structured data warehouse for actual BI consumption.
Advanced Analytics and Data Science
While the data swamp dilemma made the data lake entirely unsuitable for traditional business intelligence reporting, it remained the absolute preferred architecture for data science, machine learning, and advanced analytics. Data scientists fundamentally require a different environment than financial analysts. Where a financial analyst requires heavily curated, normalized, and pre-aggregated dimensional models to guarantee precision, a data scientist requires access to the rawest, highest-fidelity data possible to train accurate predictive models.
The Value of Unaltered Telemetry
When data is forced through an ETL pipeline into a traditional data warehouse, it inherently loses fidelity. Data engineers routinely drop columns that seem irrelevant, trim high-precision timestamps to the nearest day to save storage space, and convert unstructured text fields into simple categorical flags. This aggregation is necessary for BI performance, but it destroys the subtle signals and hidden correlations that machine learning algorithms rely upon to generate accurate predictions.
The data lake preserves this fidelity. By storing the raw, unaltered payloads in cheap object storage, organizations ensure that their data science teams always have access to the ground truth. If a machine learning engineer develops a novel natural language processing technique, they can apply it to years of raw customer support chat transcripts stored in the lake, an operation that would be completely impossible if the engineering team had previously truncated those transcripts to fit the rigid schema of a data warehouse.
The Evolution of Distributed Compute
The ability of data scientists to extract value from the raw data lake has improved exponentially due to the evolution of distributed compute engines. In the early Hadoop era, processing data on HDFS required writing complex, low-level Java MapReduce jobs. This was a highly specialized engineering task that severely bottlenecked analytical productivity.
The introduction of Apache Spark revolutionized data science on the data lake. Spark replaced the slow, disk-bound architecture of MapReduce with a highly optimized, in-memory processing framework. Data scientists could now interact with massive datasets on object storage using intuitive DataFrame APIs in Python, Scala, or R. Spark enabled the rapid prototyping of machine learning pipelines, complex feature engineering, and massive-scale data transformations without requiring analysts to understand the underlying complexities of distributed systems.
As machine learning has evolved toward generative AI and Large Language Models (LLMs), the data lake has become the primary source for proprietary training and tuning data. Vast repositories of internal documentation, codebases, and unstructured text stored in the lake are tokenized and processed by these distributed compute engines to build custom organizational intelligence. The raw data lake remains the undisputed engine room for advanced analytical innovation.
The Dremio Approach to the Data Lake
For years, organizations were trapped in a paradigm where they had to choose between the reliability of the data warehouse for BI and the flexibility of the data lake for data science. Dremio was architected specifically to shatter this dichotomy. Dremio operates on the fundamental conviction that data should not be endlessly copied, moved, and duplicated across disparate systems. Instead, organizations should be able to execute high-performance business intelligence directly against the raw data lake.
Zero-ETL and Direct Query Execution
Dremio acts as a distributed, high-performance SQL execution engine that sits directly on top of the data lake. It utilizes a Zero-ETL approach. Rather than forcing data engineers to build fragile pipelines to extract data from Amazon S3, transform it on a separate server, and load it into a proprietary data warehouse cube, Dremio simply queries the Parquet or JSON files directly where they reside in the object storage bucket.
By querying the data in place, Dremio dramatically reduces data engineering overhead and infrastructure costs. Analysts gain immediate access to the freshest possible data without waiting for overnight batch jobs to complete. The Dremio engine achieves interactive query speeds on object storage by heavily leveraging Apache Arrow, an open-source columnar memory format that allows the execution engine to perform massive vectorized aggregations in RAM without the overhead of serialization.
Implementing the Universal Semantic Layer
The primary challenge of querying a raw data lake is that the underlying files lack the curated structure required by business intelligence tools. A Tableau or Power BI user cannot easily decipher the cryptic column names of raw JSON telemetry. To solve this, Dremio introduces a powerful, centralized Semantic Layer.
The semantic layer acts as a logical translation engine between the raw physical files in the data lake and the clean, business-ready models expected by analysts. Data engineers use standard SQL to define virtual datasets within the semantic layer. They can rename cryptic columns, join raw telemetry files with dimensional lookup tables, and embed complex business logic, such as standardized revenue calculations. Crucially, these virtual datasets do not require creating physical copies of the data. When an analyst connects their BI tool to Dremio and queries a clean virtual dataset, the Dremio optimizer automatically translates that request on the fly into an efficient physical execution plan against the raw object storage. This semantic abstraction effectively brings the governed, structured experience of a traditional data warehouse directly to the chaotic data lake.
Accelerating the Lake with Data Reflections
To guarantee that massive aggregations against object storage return in milliseconds, Dremio employs a proprietary acceleration technology called Data Reflections. Data Reflections are intelligent, invisible materializations of the data. When an engineer identifies a slow-running query or a heavily utilized virtual dataset, they can enable a Reflection. Dremio automatically pre-computes the aggregation, sorts the data, and stores the highly optimized Parquet files back in the data lake.
When a subsequent query is issued against the semantic layer, the Dremio optimizer algebraically matches the query to the available Data Reflections. If a Reflection can satisfy the query more efficiently than scanning the raw files, the optimizer transparently rewrites the execution plan to use the Reflection. The end user remains completely unaware of the underlying mechanics; they simply experience blazing-fast dashboard performance on data that technically still resides in the data lake.
The Transition to the Lakehouse
While engines like Dremio drastically improved the performance and accessibility of the data lake, the fundamental issues of data corruption and lack of transactional isolation remained tied to the underlying limitations of object storage. To finally eradicate the data swamp, the industry required a mechanism to enforce true database semantics on raw files. This requirement led directly to the creation of open table formats and the birth of the data lakehouse architecture.
The Role of Open Table Formats
The transition from a data lake to a data lakehouse is defined entirely by the adoption of open table formats, most notably Apache Iceberg. Apache Iceberg acts as a dedicated metadata layer that sits between the compute engines (like Spark or Dremio) and the physical Parquet files in the object storage bucket.
Instead of relying on the slow and inconsistent directory listing operations of Amazon S3 to determine which files belong to a table, a query engine simply reads the Iceberg metadata tree. This tree definitively tracks the exact list of files that make up the current state of the table. By managing this metadata precisely, Iceberg brings full ACID compliance to the data lake. If a write job fails, the metadata pointer is never updated, and the failed files remain completely invisible to downstream readers. Multiple engines can read and write to the same lakehouse table concurrently without any risk of data corruption, finally resolving the chaos that plagued early data lakes.
Best Practices for Modernization
Modernizing a legacy data lake into a high-performance data lakehouse requires a deliberate engineering strategy. The most critical step is standardizing on open formats. Organizations must actively migrate their raw, unstructured data into optimized, columnar Parquet files and register those files as Apache Iceberg tables. This migration immediately unlocks ACID transactions, schema evolution, and time travel capabilities.
Furthermore, organizations must deploy a centralized, open catalog, such as Apache Polaris, to track these Iceberg tables and enforce Role-Based Access Control globally. By combining the cost-effective scalability of cloud object storage, the transactional reliability of Apache Iceberg, the open interoperability of Apache Polaris, and the high-performance semantic abstraction of Dremio, organizations successfully transform their stagnant data lakes into dynamic, governed, and lightning-fast data lakehouses. This unified architecture is the definitive foundation for the future of enterprise data engineering and Agentic AI.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.