Apache Spark
A comprehensive guide to Apache Spark, the distributed computing engine that transformed large-scale data processing with its unified API for batch, streaming, SQL, ML, and graph analytics.
Why Spark Displaced MapReduce
Apache Hadoop’s MapReduce was the first practical framework for distributed large-scale batch processing on commodity hardware. But MapReduce had a fundamental performance limitation: every intermediate result between processing stages was written to disk. A multi-stage data processing job that required chaining ten MapReduce steps would read from disk and write to disk ten times. For iterative algorithms like machine learning model training (which might require hundreds of iterations over the same dataset), this disk I/O overhead made MapReduce impractically slow.
Apache Spark was developed at the AMPLab at UC Berkeley starting in 2009 as a direct response to MapReduce’s disk I/O bottleneck. Spark’s core insight was that intermediate results could be cached in distributed memory (RAM) across the cluster rather than being written to disk after every stage. For iterative workloads over the same data, in-memory processing delivered performance improvements of ten to one hundred times over MapReduce.
Spark became an Apache project in 2013 and quickly displaced MapReduce as the dominant distributed processing engine for large-scale data engineering. Its elegant programming model, rich API, and unified support for batch processing, SQL queries, streaming, machine learning, and graph analytics made it the Swiss Army knife of the big data ecosystem.
Resilient Distributed Datasets and DataFrames
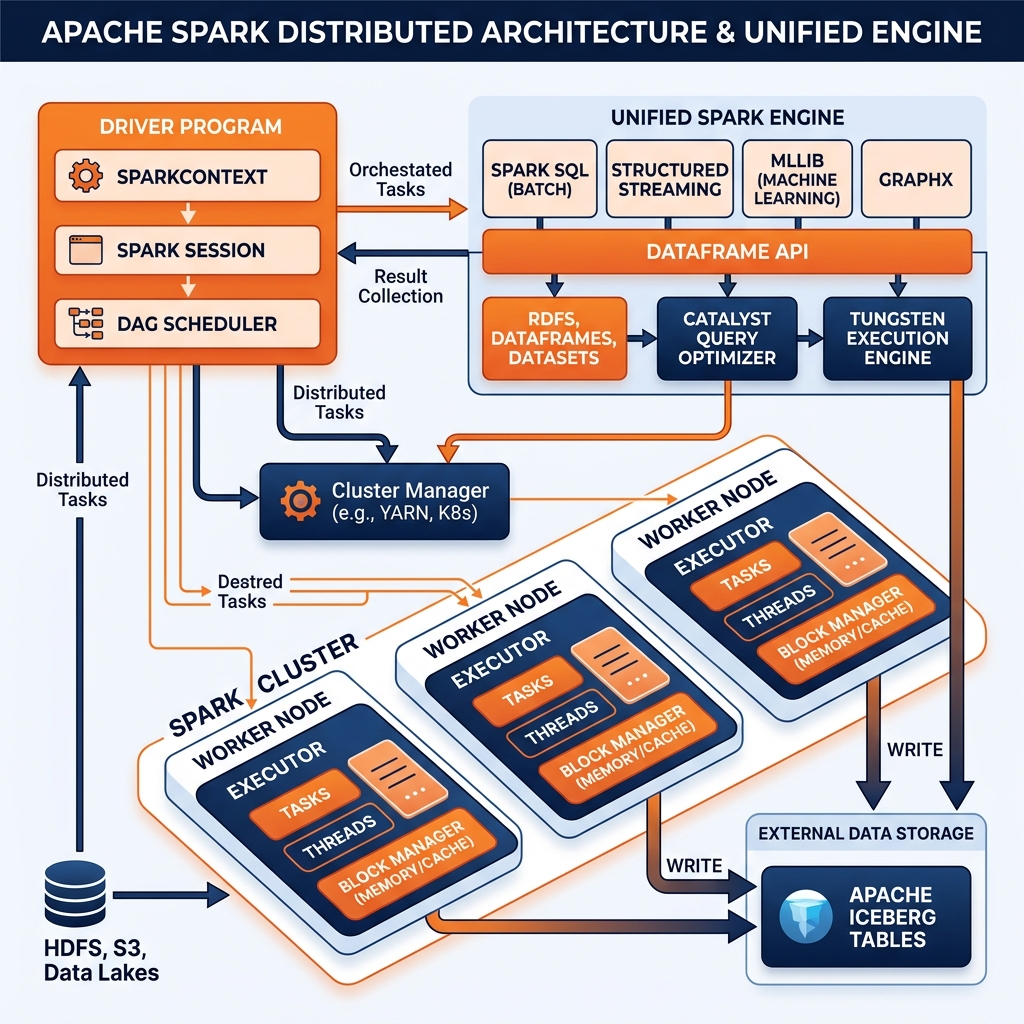
Spark’s original programming model was built around the Resilient Distributed Dataset (RDD), an immutable, distributed collection of objects that could be transformed through functional operations (map, filter, reduce, join) and cached in memory across the cluster. RDDs provided fault tolerance through lineage: if a partition of an RDD was lost due to node failure, Spark could recompute it by replaying the transformation lineage from the last available checkpoint.
Spark SQL and the DataFrame API, introduced in Spark 1.3 and significantly enhanced in Spark 2.0, provided a higher-level abstraction that organized data into named columns with declared types, directly analogous to a relational table. The DataFrame API allowed engineers to write transformations using familiar SQL semantics (select, filter, groupBy, join) rather than functional RDD operations, making Spark accessible to engineers with SQL backgrounds rather than only Scala and Java developers.
Spark SQL’s Catalyst query optimizer applies the same logical query optimization techniques used in relational databases (predicate pushdown, join reordering, constant folding) to Spark DataFrame queries, improving performance without requiring manual optimization from the engineer.
Structured Streaming
Spark Structured Streaming extends the batch DataFrame API to streaming workloads through a unified programming model. Engineers write their streaming transformation logic as if they were processing a static DataFrame; Spark internally translates this into a continuous incremental processing engine that processes micro-batches of streaming data as they arrive.
This unified API is a significant productivity advantage: the same transformation code that processes historical batch data can be deployed against a live Kafka stream with minimal modification. Engineers do not need to learn a separate streaming API or maintain separate batch and streaming implementations of the same business logic.
Structured Streaming integrates natively with Apache Iceberg through the Iceberg Flink and Spark connectors, enabling streaming writes to Iceberg tables with ACID guarantees. Each micro-batch write to an Iceberg table commits as an atomic Iceberg snapshot, maintaining consistency even when the streaming job fails and restarts mid-batch.
Spark and the Iceberg Lakehouse
Apache Spark is the most widely used compute engine for writing to Apache Iceberg tables. The Iceberg Spark connector provides a complete implementation of Spark’s DataSource v2 API for Iceberg, supporting all DML operations: INSERT INTO for append operations, MERGE INTO for upserts (critical for CDC-based ingestion), DELETE FROM for GDPR right-to-deletion implementation, and UPDATE for corrective transformations.
Spark’s Iceberg integration also supports reading from multiple Iceberg catalogs simultaneously, enabling cross-catalog joins. A Spark job can join Iceberg tables registered in Apache Polaris with tables registered in AWS Glue in a single query, federating data across catalog boundaries that would require complex manual data movement in traditional architectures.
The typical enterprise lakehouse pipeline uses Spark for the bulk processing needs of the Bronze-to-Silver and Silver-to-Gold transformation steps in the Medallion Architecture, writing the transformation results as ACID-committed Iceberg snapshots. Dremio then serves as the governance and performance layer on top of these Iceberg tables, providing governed analytical access through its Semantic Layer and delivering interactive query performance through Data Reflections and Arrow-based query execution.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.