Apache Polaris
A comprehensive guide to Apache Polaris, the open-source, vendor-neutral Iceberg REST catalog that provides unified table governance across multiple compute engines and cloud environments.
The Catalog Problem in the Open Lakehouse
Apache Iceberg’s table format specification defines how metadata and data files are organized in object storage. But a table format alone is not enough to build a production data platform. You also need a catalog: a service that tracks which tables exist, where their metadata files are located, and controls access to them.
The catalog is the directory of the data platform. Without it, compute engines have no way to discover available tables by name, no mechanism to perform atomic table creation or renaming operations, and no central point for enforcing access controls. In a multi-engine environment where Apache Spark, Apache Flink, Dremio, Trino, and Python scripts all need to read and write the same Iceberg tables, the catalog must be a shared, neutral service that all engines can communicate with.
Apache Polaris (incubating) was created at Snowflake, open-sourced in 2024, and donated to the Apache Software Foundation to address a critical gap in the open lakehouse ecosystem: the absence of a fully open, vendor-neutral, production-grade Iceberg catalog with enterprise-grade access control.
Before Polaris, the primary Iceberg catalog options were the Hive Metastore (which requires a running Hive infrastructure and lacks native Iceberg-specific capabilities), AWS Glue (which is AWS-specific and introduces vendor lock-in), and Project Nessie (which adds Git-like branching but has a different governance model). Polaris was designed to fill the need for a catalog that implements the full Iceberg REST Catalog specification, supports fine-grained RBAC, and can federate access across multiple storage locations and cloud providers.
The Iceberg REST Catalog Specification
Polaris is an implementation of the Apache Iceberg REST Catalog API specification. This specification defines a standard HTTP REST interface through which compute engines interact with a catalog: creating namespaces and tables, loading table metadata, committing new table versions, and listing available tables.
The REST Catalog specification is engine-agnostic and language-agnostic. Any compute engine that implements the Iceberg REST client can connect to any REST Catalog implementation, including Polaris, without engine-specific configuration. This means that an organization running Polaris as its central catalog can connect Apache Spark, Apache Flink, Dremio, DuckDB, Trino, and PyIceberg to the same catalog through the same REST interface. Table metadata changes committed by a Spark job are immediately visible to Dremio queries and Flink streaming jobs, all working against a single, consistent catalog state.
This standardization is what makes Polaris a foundational piece of the open lakehouse interoperability story. The alternative, configuring each compute engine with its own private catalog instance, creates data silos where tables written by one engine are invisible to others and metadata becomes fragmented across multiple catalog instances.
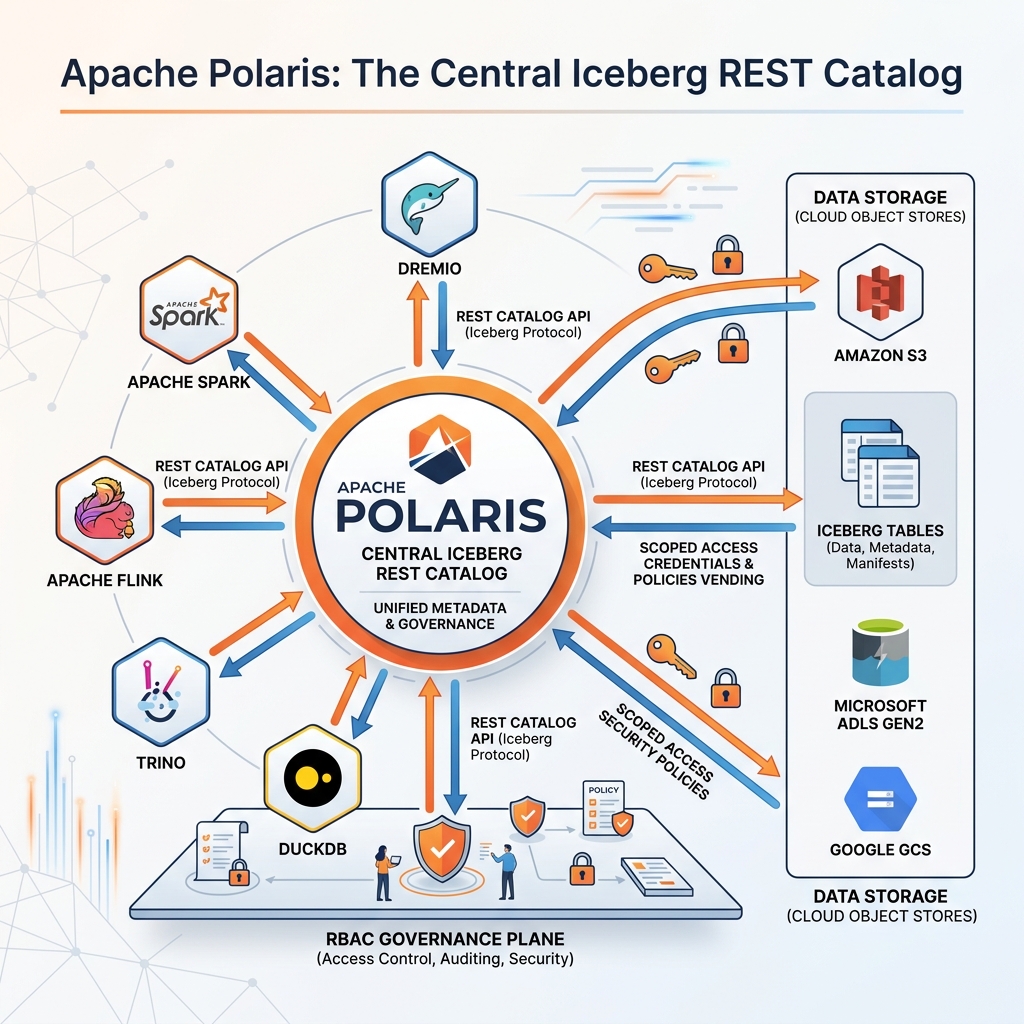
Credential Vending and Secure Storage Access
One of Polaris’s most important enterprise features is credential vending. In a multi-engine lakehouse, all compute engines need to read data files stored in object storage (S3, ADLS, GCS). The naive approach is to distribute broad storage credentials (AWS access keys, Azure service principal credentials) to every compute engine, but this creates serious security problems: any compromised engine or credential immediately exposes the entire data lake.
Polaris implements credential vending to solve this. When a compute engine requests to read or write a specific Iceberg table, Polaris issues a scoped, time-limited credential specifically for the storage paths associated with that table. The engine uses this vended credential to access only the files it is authorized to read or write, and the credential expires after a configurable duration (typically minutes to hours). The engine never holds permanent storage credentials; it re-requests scoped credentials from Polaris each time it needs to access data.
This vended credential architecture provides several security guarantees. A compromised compute engine can only access data from the tables it was specifically authorized to read in that session, limited to the credential’s expiration window. Revoking a principal’s access in Polaris immediately prevents new credential vending, even if the engine is currently running. Security auditors can trace exactly which tables each engine accessed and when, through Polaris’s audit log.
Multi-Catalog Federation
Polaris supports the concept of External Catalogs: read-only references to tables managed by external systems, including AWS Glue catalogs, other Iceberg REST catalogs, and even Hive Metastore-managed tables. This federation capability allows Polaris to serve as a unified metadata plane that aggregates tables from multiple catalog backends into a single queryable namespace.
Organizations migrating from fragmented per-engine catalog configurations to a centralized Polaris deployment can use external catalogs to make existing tables from legacy systems visible through Polaris without requiring immediate data migration. Downstream engines query Polaris for all tables, and Polaris transparently proxies access to the appropriate underlying catalog for legacy tables while serving Polaris-native tables directly.
Dremio and Apache Polaris
Dremio natively integrates with Apache Polaris as an Iceberg REST catalog source. When Polaris is configured as a Dremio source, Dremio discovers all Iceberg tables registered in Polaris through the REST Catalog API. Dremio respects Polaris’s RBAC policies, and Polaris’s credential vending provides the scoped storage credentials that Dremio uses to read the actual Parquet data files. This integration means that Polaris serves as the single governance control plane for the lakehouse, with Dremio, Spark, Flink, and other engines all receiving data access through Polaris’s governed credential vending.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.