PyIceberg
A guide to PyIceberg, the official Python library for Apache Iceberg that enables Python developers and data scientists to interact with Iceberg tables directly without requiring a JVM-based engine like Spark.
Iceberg Without the JVM
Apache Iceberg was originally designed and implemented for JVM-based compute engines: Apache Spark, Apache Flink, Trino, and Dremio. For years, working with Iceberg tables from Python required launching a Spark session, which meant JVM startup overhead, cluster configuration, and the full weight of Spark’s distributed execution framework even for simple catalog operations or small data reads.
PyIceberg is the official Apache Iceberg Python library that eliminates the JVM requirement for Python-based Iceberg interactions. It implements the complete Iceberg table spec in native Python, allowing Python applications to load Iceberg table metadata, read data files directly, manage schemas, and perform catalog operations without any JVM dependency.
PyIceberg is particularly valuable for data science workflows where analysts prefer to work in Python notebooks with pandas or Polars DataFrames, and for lightweight catalog management scripts that need to perform operations like creating tables, adding partitions, or running snapshot expiration without the overhead of a Spark cluster.
Core PyIceberg Capabilities
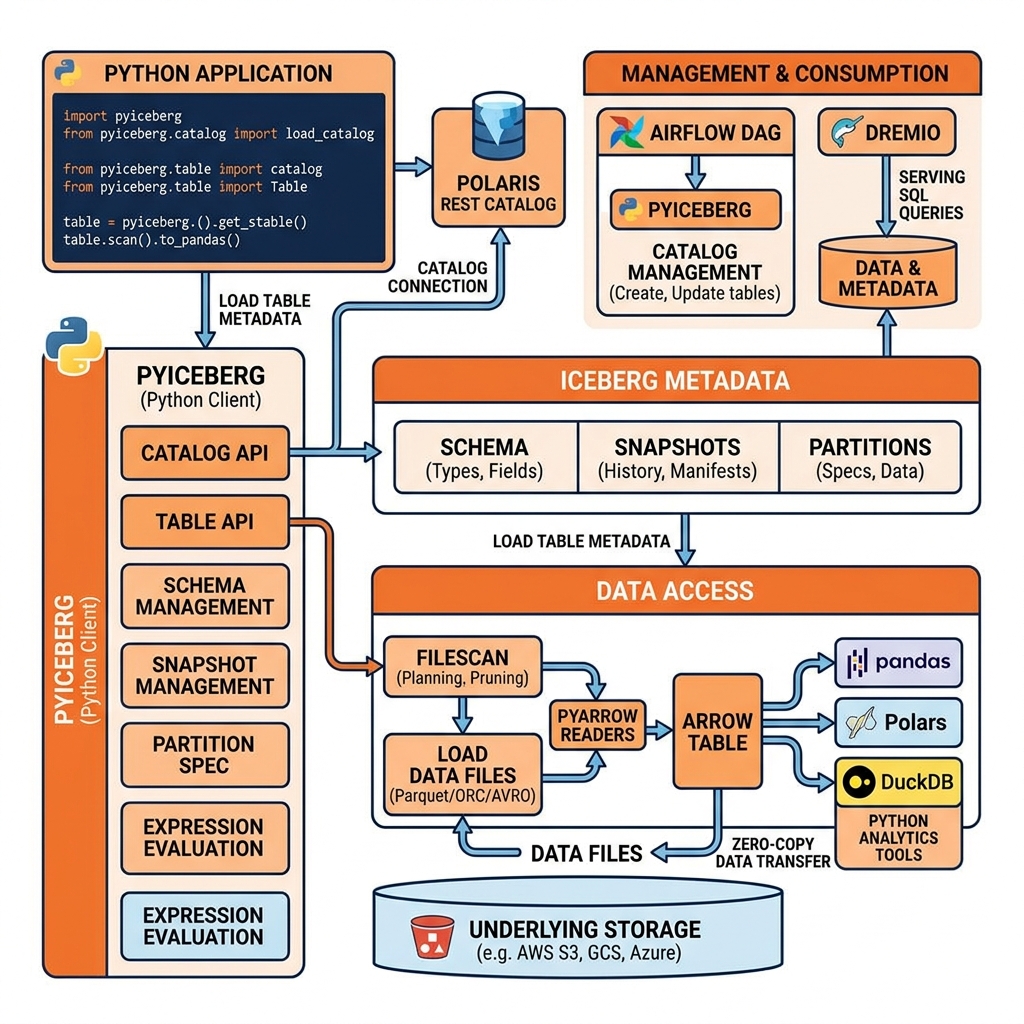
Catalog integration: PyIceberg connects to any Iceberg catalog through its catalog API. REST catalogs (Polaris, Gravitino, Unity Catalog via REST), Hive Metastore catalogs, Glue catalogs, and filesystem catalogs are all supported through catalog implementations that share a common Python interface. Connecting to a Polaris catalog requires only a few lines of configuration: the catalog URL, the OAuth2 credentials, and the catalog name.
Table metadata access: Once connected to a catalog, PyIceberg loads table metadata directly from the metadata JSON files. Schema, partition spec, snapshots, and properties are all accessible as Python objects. An analyst can inspect the current schema, browse the snapshot history, check partition spec evolution, and read file statistics without executing a single SQL query.
Data reading with Arrow: PyIceberg’s table scan API reads Parquet data files using the pyarrow Parquet reader and returns results as Apache Arrow Tables. The scan API supports filter predicates, column selection, and snapshot selection for time travel. Arrow Tables integrate directly with pandas, Polars, DuckDB, and other Python analytical libraries with zero data copying.
Write support: PyIceberg 0.7+ includes write support for appending data to Iceberg tables. Python applications can write pandas DataFrames or Arrow Tables directly to Iceberg tables through PyIceberg’s append API, which writes Parquet files and commits a new snapshot to the catalog.
PyIceberg with DuckDB and Dremio
A powerful pattern for lightweight analytics combines PyIceberg’s table scan capabilities with DuckDB’s SQL engine. PyIceberg loads the Iceberg table scan result as an Arrow Table in memory, and DuckDB queries the Arrow Table using SQL. This combination provides SQL analytical capabilities on Iceberg data without Spark or Dremio, making it ideal for data scientists who prefer local Python environments for exploratory analysis.
For production lakehouse interactions, PyIceberg complements Dremio by handling catalog management operations in Python scripts and Airflow DAGs. Dremio handles the high-performance SQL querying of the resulting Iceberg tables through Arrow Flight. Python scripts use PyIceberg to create new tables, run snapshot expiration on completed batch partitions, and query table metadata programmatically, while Dremio serves as the governed SQL query interface for analysts and BI tools.
The combination of PyIceberg for catalog management, DuckDB for local Python analytics, and Dremio for production governed SQL access represents the complete Python-friendly Iceberg lakehouse stack.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.