Apache Flink
A guide to Apache Flink, the open-source distributed stream processing engine that provides low-latency, stateful event processing for real-time analytical and operational pipelines.
The Primacy of Streaming
Apache Kafka established that enterprise data is fundamentally a stream of events. Apache Flink was built on the insight that stream processing should be the primary computing paradigm, not an afterthought bolted onto a batch framework. Where Apache Spark treats streaming as a sequence of micro-batches (batch processing applied to small windows of data), Flink treats every event as a first-class citizen that flows through a processing pipeline continuously, with batch processing being a special case of bounded stream processing.
This architectural distinction has practical consequences. Spark Structured Streaming’s micro-batch model introduces inherent latency equal to the micro-batch interval (typically seconds). Flink’s true streaming model processes each event with sub-millisecond latency, making it suitable for use cases that require genuine real-time responsiveness: fraud detection (detecting and blocking a suspicious transaction before it completes), real-time bidding (computing ad auction bids within the 100ms response window), and live operational monitoring (alerting on system anomalies within seconds of their occurrence).
Stateful Stream Processing
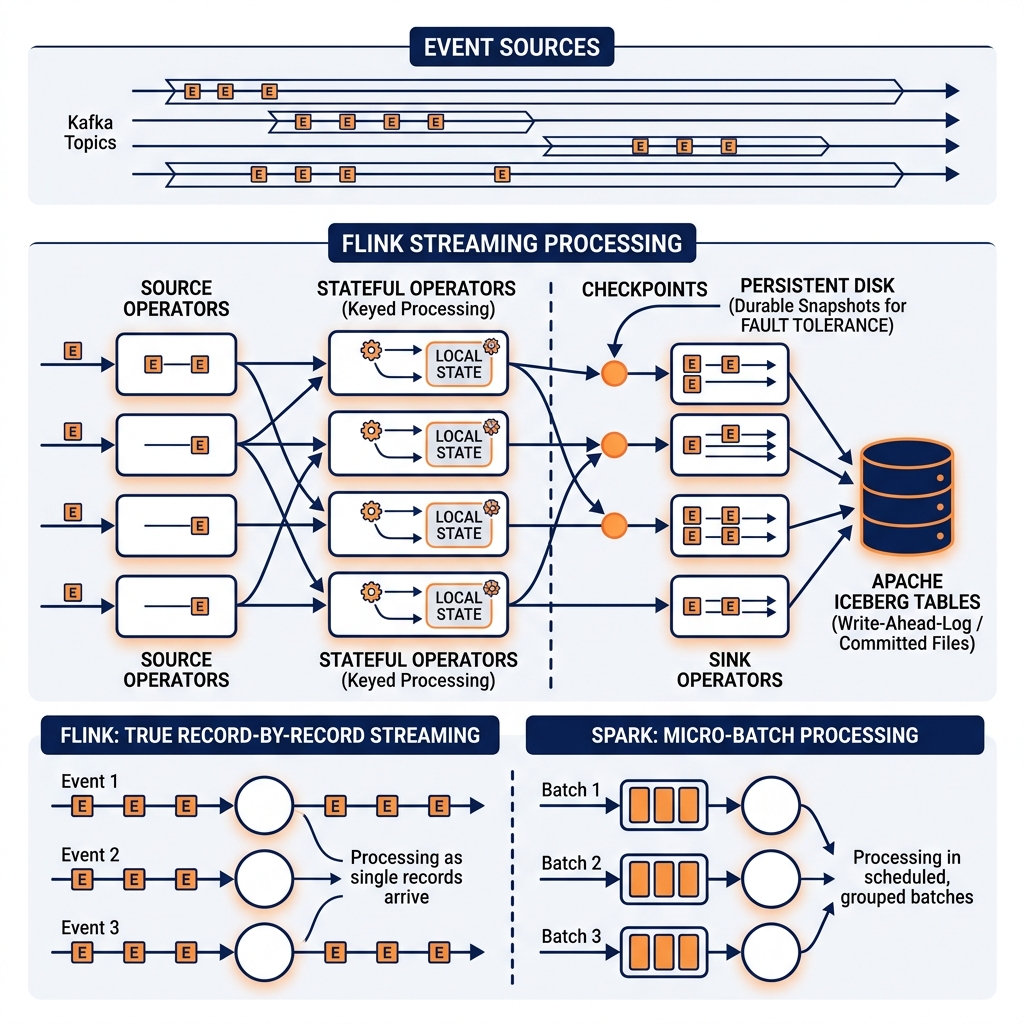
The fundamental challenge of stream processing is maintaining state across an unbounded stream of events. A fraud detection system needs to track the spending pattern for each customer across the last 30 days of transactions to detect anomalous spikes. A session analytics pipeline needs to group web page events into user sessions separated by 30-minute inactivity gaps. These computations require maintaining and updating state as new events arrive, while ensuring that this state is consistent and recoverable if the processing node fails.
Flink’s keyed state model is the core mechanism for stateful stream processing. Events are routed to processing instances by a key (customer ID, session ID, device ID), ensuring that all events for the same key are processed by the same Flink task instance and share access to the same state. Flink supports multiple state types: ValueState (single value per key), MapState (a key-value map per key), ListState (a list per key), and AggregatingState (incrementally computed aggregations per key).
Flink’s state backend (either heap-based or RocksDB-based for very large state) persists the state durably, enabling recovery from node failures. Flink’s checkpoint mechanism periodically takes a consistent snapshot of all state across all parallel instances through the Chandy-Lamport distributed snapshot algorithm, without pausing event processing. If a processing node fails, Flink restores the most recent checkpoint and replays any events processed since the checkpoint, providing exactly-once processing semantics.
Flink and Apache Iceberg
Apache Flink is the primary engine for streaming writes to Apache Iceberg tables in real-time lakehouse pipelines. The Flink Iceberg connector supports both append (for high-throughput streaming ingestion) and upsert (for CDC-based streaming maintenance) write modes.
In streaming ingestion mode, Flink accumulates events in memory for a configurable interval and then commits a batch of new Parquet data files to the Iceberg table as an atomic snapshot. This checkpoint-aligned commit model ensures that Iceberg snapshots are always complete and consistent: each snapshot corresponds to exactly a checkpoint boundary, making exactly-once semantics achievable end-to-end.
The combination of Flink’s CDC source connectors (reading from Debezium events in Kafka) and the Flink Iceberg sink connector creates the near-real-time operational lakehouse pattern. Operational database changes captured by Debezium flow through Flink’s stateful processing (where deduplication, key routing, and upsert state management occur) and land in the Iceberg table within seconds. Dremio then serves the near-real-time Iceberg data to analysts through its Semantic Layer, providing governed interactive access to data that is continuously synchronized with the operational source.
Flink SQL and Table API
Flink SQL extends SQL semantics to streaming computations, allowing engineers to write streaming pipelines using standard SQL syntax with Flink-specific extensions for temporal operations. A Flink SQL query can compute a rolling 30-minute window aggregate over a Kafka event stream, join a streaming fact stream against a slowly changing Iceberg dimension table (temporal joins), and write the output to a new Iceberg table, all expressed in pure SQL.
This SQL-first approach dramatically lowers the barrier to stream processing. Engineers who understand SQL can build production streaming pipelines without learning Flink’s Java or Python DataStream API, making stream processing accessible to a much broader range of data practitioners than the raw API approach.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.