Apache Kafka
A comprehensive guide to Apache Kafka, the distributed event streaming platform that serves as the central nervous system for real-time data pipelines, enabling high-throughput, durable, and scalable event streaming.
The Event Streaming Revolution
Before Apache Kafka, enterprise systems communicated through point-to-point integrations. System A sent data directly to System B, System C, and System D through custom interfaces. When a new System E needed access to System A’s data, a new integration was built. The resulting architecture was a sprawling web of point-to-point connections that was expensive to maintain, brittle to failures, and nearly impossible to scale.
Apache Kafka, developed at LinkedIn in 2011 and open-sourced the same year, introduced a fundamentally different architectural pattern: the publish-subscribe event log. Rather than sending data directly to consumers, producers write events to a central, durable, ordered log. Consumers independently read from this log at their own pace. System A writes events once; Systems B, C, D, and E all read the same events independently, with no coordination between them. Adding System F requires only a new consumer reading from the existing Kafka log, with no modification to System A or any other existing system.
This decoupling of producers from consumers is the foundational architectural contribution of Kafka. It transformed enterprise data integration from a O(n^2) point-to-point integration problem into a O(n) hub-and-spoke architecture where the Kafka cluster is the central data integration hub.
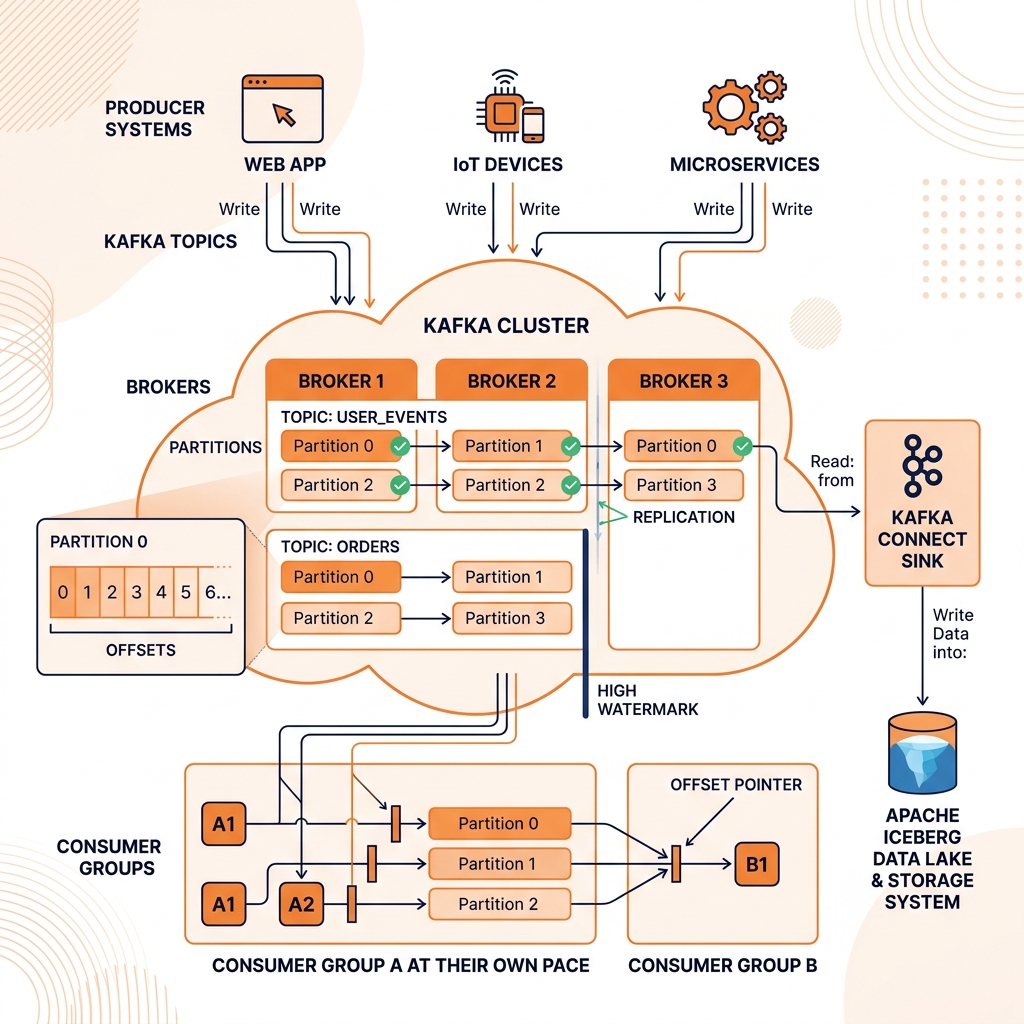
Topics, Partitions, and Offsets
Kafka organizes events into topics: named, ordered sequences of events. A topic is analogous to a database table, but instead of rows, it contains an append-only, time-ordered sequence of events. Events in a topic are never deleted as they arrive (unlike a message queue, which deletes messages upon acknowledgment); they are retained for a configurable retention period (days, weeks, or indefinitely), allowing consumers to replay historical events.
Topics are divided into partitions, which are the unit of parallelism and durability. Each partition is an ordered, immutable sequence of events stored on disk. Events within a partition maintain strict ordering (events are always read in the order they were written). Events across different partitions in the same topic do not have a guaranteed order relative to each other.
Partitions are replicated across multiple Kafka brokers (servers) in the cluster, with one partition designated as the leader (handling all reads and writes) and the others as followers (maintaining synchronous copies of the partition data). If the leader broker fails, one of the follower brokers is automatically promoted to leader, providing automatic fault tolerance without data loss.
Each event in a partition is identified by its offset: a monotonically increasing integer that uniquely identifies the event’s position in the partition. Consumers track their read position by recording the last offset they processed. If a consumer fails and restarts, it resumes from its last committed offset, processing exactly the events it missed.
Kafka as the CDC Integration Hub
Apache Kafka serves as the central integration hub for Change Data Capture pipelines. Debezium captures database change events and publishes them to Kafka topics, one topic per source database table. Downstream consumers (Apache Flink jobs, Spark Structured Streaming jobs, Kafka Connect sink connectors) independently consume from these CDC topics at their own pace.
This architecture provides several critical advantages over direct database-to-database CDC integration. Kafka acts as a buffer, absorbing write bursts from the source database without overwhelming downstream consumers. Multiple downstream systems can consume the same CDC events independently, allowing a single Debezium capture pipeline to feed both a Flink-based Iceberg writer (for the analytical lakehouse) and an Elasticsearch indexer (for full-text search) without any coordination between them. The event retention policy means that a downstream consumer that was offline for maintenance can replay the missed events when it comes back online.
Kafka Connect and the Sink Ecosystem
Kafka Connect is a managed framework for running Kafka connectors, pre-built integration components that move data between Kafka and external systems. Source connectors ingest data from external systems into Kafka topics; sink connectors deliver data from Kafka topics to external systems.
The Iceberg Kafka Connect sink connector writes Kafka topic events directly to Apache Iceberg tables, providing a zero-code ingestion path from any Kafka-producing source system to the data lakehouse. Organizations with existing Kafka infrastructure can land all their event streams into Iceberg tables through the Kafka Connect sink connector without writing any custom ingestion code.
Dremio connects to the Iceberg tables populated by Kafka-sourced pipelines through its standard Iceberg table reading capability, providing governed SQL access to the near-real-time event data flowing through the Kafka-to-Iceberg pipeline.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.