Data Lakehouse
A comprehensive guide to the data lakehouse architecture, bridging the reliability of data warehouses with the scale and flexibility of data lakes, powered by open table formats like Apache Iceberg.
The Evolution of Data Architecture
The journey toward modern data engineering is defined by the tension between structured reliability and unstructured scale. Understanding the data lakehouse requires tracing the architectural shifts that preceded it. Historically, organizations relied entirely on data warehouses for analytics. A data warehouse mandates that all ingested data conforms to a rigid, predefined schema before it is written to disk. This paradigm, known as schema-on-write, ensures high data quality and provides the foundation for reliable, performant business intelligence dashboards. The primary drawback of the data warehouse is rigidity. When a business needs to analyze novel data formats, nested JSON structures, or machine learning telemetry, the warehouse pipeline struggles to adapt without expensive and time-consuming engineering intervention. Furthermore, the storage and compute components of traditional on-premises data warehouses are tightly coupled. Scaling up to meet storage demands inevitably forces organizations to pay for unnecessary compute power.
To circumvent the bottlenecks of the data warehouse, the industry pivoted toward the data lake. Built initially on the Hadoop Distributed File System (HDFS) and later migrating to cloud object storage like Amazon S3, Google Cloud Storage, and Azure Data Lake Storage, the data lake operates on a schema-on-read philosophy. Data engineers dump raw, unprocessed files in their native formats directly into the storage bucket. This approach offers practically infinite scale and incredible flexibility, making it the preferred architecture for data science and machine learning teams who need access to unaltered datasets. However, the data lake introduced a severe reliability problem. Without the rigorous schema enforcement and ACID transaction guarantees of a relational database, data lakes quickly degenerated into “data swamps.” Concurrent read and write operations frequently resulted in data corruption. If a pipeline failed halfway through a write operation, the resulting partial files polluted the dataset. Querying the data lake directly proved chaotic and slow, forcing organizations into a compromise known as the two-tier architecture.
In a two-tier architecture, the data lake serves as the landing zone for raw data. Extract, Transform, and Load (ETL) pipelines then move a curated subset of that data into a downstream data warehouse for business intelligence consumption. This architecture is complex, fragile, and expensive. It requires maintaining duplicate copies of the same data across multiple systems. Data engineers spend the majority of their time building and fixing the pipelines that synchronize the lake and the warehouse rather than delivering business value. The synchronization delay also means that business analysts querying the warehouse are inherently looking at stale data.
The data lakehouse emerged specifically to dismantle the two-tier architecture. It proposes a unified paradigm that applies the reliability, ACID transactions, and governance of a data warehouse directly onto the cheap, scalable object storage of a data lake. The foundational breakthrough that enables the lakehouse is the open table format. By decoupling the metadata management from the physical storage layer, the lakehouse allows compute engines to treat collections of raw Parquet files as fully transactional SQL tables. Organizations no longer need to move data into a proprietary warehouse to analyze it. Instead, they bring the query engine directly to the data lake. This unification dramatically simplifies data engineering workflows, reduces storage costs, and enables a single source of truth for both business intelligence analysts and machine learning practitioners.
Core Components of a Data Lakehouse
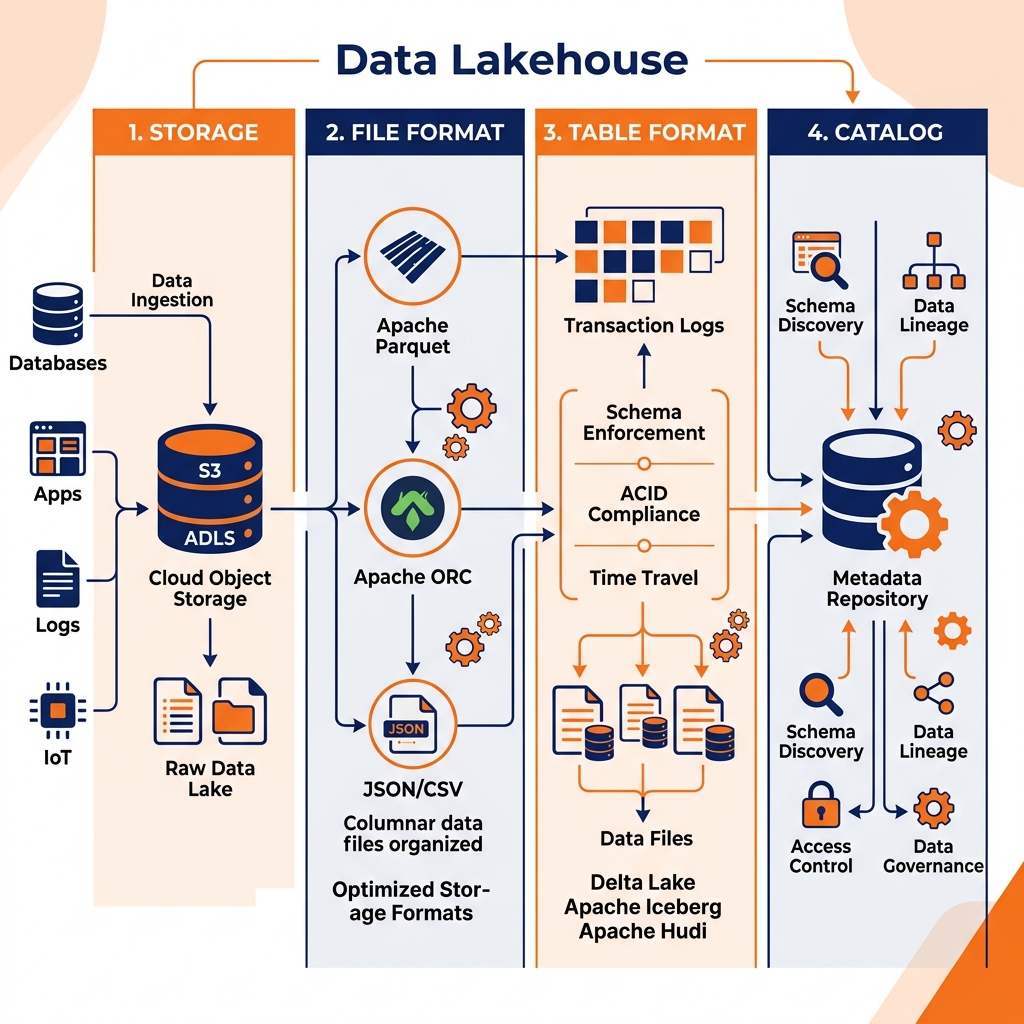
The architecture of a modern data lakehouse is intentionally modular. Rather than a monolithic system where storage, compute, and metadata are intertwined, the lakehouse decomposes the database architecture into distinct, interchangeable layers. This modularity prevents vendor lock-in and allows organizations to upgrade individual components as technology evolves. A fully realized data lakehouse consists of four primary layers: the storage layer, the file format layer, the table format layer, and the catalog layer.
The Storage Layer
At the foundation of the lakehouse sits the physical storage layer. In modern implementations, this is almost exclusively cloud object storage, such as Amazon S3, Google Cloud Storage (GCS), or Azure Data Lake Storage (ADLS). Object storage is fundamentally different from the block storage used by traditional relational databases. It is designed for unparalleled durability, massive scalability, and low-cost persistence of binary large objects (BLOBs). Unlike a traditional file system with a hierarchical directory structure, object storage uses a flat namespace where each file is accessed via a unique key.
The primary advantage of object storage is its decoupling from compute resources. Organizations can store petabytes of historical telemetry without provisioning active CPU or RAM. However, object storage is notoriously slow for small, randomized read-and-write operations. It lacks the ability to execute in-place updates. Modifying a single record in a one-gigabyte object requires rewriting the entire gigabyte. The subsequent layers of the lakehouse exist specifically to mask these physical limitations and optimize how compute engines interact with the raw objects.
The File Format Layer
Directly above the storage layer is the file format layer. If a data engineer simply dumps raw CSV or JSON files into object storage, analytics queries will suffer from abysmal performance. Text-based formats require heavy parsing, and querying a single column necessitates reading the entire row from disk. To optimize analytical workloads, the lakehouse relies on open columnar file formats, with Apache Parquet being the undisputed industry standard.
Parquet organizes data by columns rather than by rows. When a compute engine executes an aggregation query on a specific metric, it only reads the relevant column chunks from disk, drastically reducing I/O overhead. Parquet also employs aggressive encoding and compression techniques, such as dictionary encoding and Snappy compression. Because all data within a single column is of the same type, compression algorithms can achieve much higher density than they could with row-oriented formats. By standardizing on Parquet, the lakehouse ensures that the physical data is highly optimized for analytical scanning before the table format even comes into play.
The Table Format Layer
The table format layer is the defining innovation of the data lakehouse. It is the connective tissue that transforms a massive, chaotic collection of Parquet files into a reliable SQL table. A table format manages the metadata that describes the table state. When a user runs a SQL INSERT, UPDATE, or DELETE statement against a lakehouse table, the compute engine does not simply overwrite files in place. Instead, it writes new data files and generates new metadata files that track the precise list of active files that make up the current state of the table.
This metadata-driven approach enables true ACID (Atomicity, Consistency, Isolation, Durability) transactions on top of immutable object storage. If two queries attempt to modify the same table simultaneously, the table format uses Optimistic Concurrency Control (OCC) to ensure that only one operation succeeds while the other is prompted to retry. Because every modification creates a new metadata snapshot rather than destroying the old state, the table format inherently supports time travel. Analysts can query the exact state of the table as it existed last Tuesday simply by passing a timestamp or snapshot ID to their query engine.
The Catalog Layer
The final structural layer is the data catalog. While the table format tracks the files that belong to a single table, the catalog tracks the existence and location of all the tables across the entire enterprise. It serves as the definitive central repository for namespaces, schemas, and table pointers. When a query engine needs to read a table, it first asks the catalog for the location of the table’s current metadata file.
Beyond simple discovery, the modern catalog layer is the enforcement point for data governance and security. It provides centralized Role-Based Access Control (RBAC), ensuring that user permissions are evaluated consistently regardless of which compute engine executes the query. By standardizing on an open catalog, organizations establish a unified control plane for the entire data ecosystem.
Open Standards in the Lakehouse
A central tenet of the data lakehouse philosophy is the commitment to open standards. When organizations adopt proprietary data warehouses, they often surrender control of their data. The vendor dictates the storage format, the compute engine, and the catalog mechanism. Extracting data from these closed ecosystems incurs massive egress fees and demands substantial engineering effort. The lakehouse architecture explicitly rejects this model by insisting that the storage, table, and catalog layers remain fundamentally open. This openness guarantees that multiple, independent compute engines can safely and efficiently interact with the same underlying data without requiring a data copy.
Apache Iceberg: The Open Standard for Tables
While several table formats exist, Apache Iceberg has emerged as the definitive open standard for the data lakehouse. Originally engineered by Netflix to resolve the crippling performance bottlenecks of the Apache Hive layout, Iceberg was donated to the Apache Software Foundation and is now supported by every major analytics vendor. Iceberg replaces the slow, directory-listing operations of Hive with a strict, file-level metadata hierarchy.
At the root of an Iceberg table is the metadata file, which tracks the table’s schema, partitioning rules, and the current snapshot. A snapshot represents the complete state of the table at a specific point in time. It points to a manifest list, which in turn points to individual manifest files. These manifest files store the actual paths to the underlying Parquet data files, alongside column-level statistics like the minimum and maximum values for every data file. This architecture allows a query engine to perform aggressive file pruning. Before the engine even touches the object storage, it analyzes the Iceberg metadata to determine exactly which Parquet files contain the required data. This metadata-first approach accelerates queries by orders of magnitude compared to traditional directory scans.
Iceberg introduces two critical operational features: hidden partitioning and schema evolution. In legacy systems, partitioning required users to manually extract partition values, such as extracting the year or month from a timestamp, and storing it in a separate column. Queries that failed to explicitly filter on this artificial column would trigger catastrophic full-table scans. Iceberg handles partitioning invisibly under the hood. The data engineer defines the partition transformation rule (for example, partitioning a timestamp by day) at the table level. The user simply queries the timestamp column naturally, and Iceberg automatically translates the query to prune the correct files. Furthermore, Iceberg tracks columns by a unique ID rather than by name. This mechanism allows engineers to safely rename, drop, or reorder columns without triggering a massive data rewrite, ensuring that schema evolution is an instantaneous metadata operation rather than a multi-day engineering migration.
Apache Arrow: The Standard for Memory
While Parquet standardizes data on disk, Apache Arrow standardizes data in memory. Moving data from the storage layer into the CPU cache is historically one of the most expensive operations in analytics. When a compute engine reads a Parquet file, it must deserialize the data into its own internal memory representation before it can perform calculations. If the organization uses a Python-based machine learning tool to analyze the output, the data must be serialized back out, transmitted, and deserialized into pandas or NumPy arrays.
Apache Arrow eliminates this serialization overhead by defining a language-independent columnar memory format. When an Arrow-native query engine pulls data from disk, it maps the data directly into the Arrow format in RAM. If another system, such as a Python script or a secondary compute engine, needs to access that data, it can read the memory buffers directly without any serialization penalty. Arrow enables hardware-accelerated, vectorized processing, allowing modern CPUs to apply an operation to thousands of values simultaneously. It forms the computational backbone of modern, high-performance lakehouse engines.
Apache Polaris: The Standard for Catalogs
The final pillar of the open lakehouse is the catalog layer. As Iceberg adoption accelerated, organizations encountered a fragmentation problem. Different query engines relied on different, often proprietary, catalog implementations to track Iceberg tables. This fragmentation threatened the promise of true interoperability.
Apache Polaris was introduced to solve this by providing a unified, open-source catalog specifically engineered for Apache Iceberg. Polaris implements the official Iceberg REST API specification, ensuring that any compliant compute engine can seamlessly discover and access tables. Crucially, Polaris provides a centralized enforcement mechanism for Role-Based Access Control. By managing security credentials at the catalog level, organizations ensure that data access policies remain consistent regardless of whether a data scientist queries the lakehouse via Apache Spark or a financial analyst runs a report via Dremio. Polaris ensures that the catalog itself does not become a new vector for vendor lock-in.
The Dremio Implementation
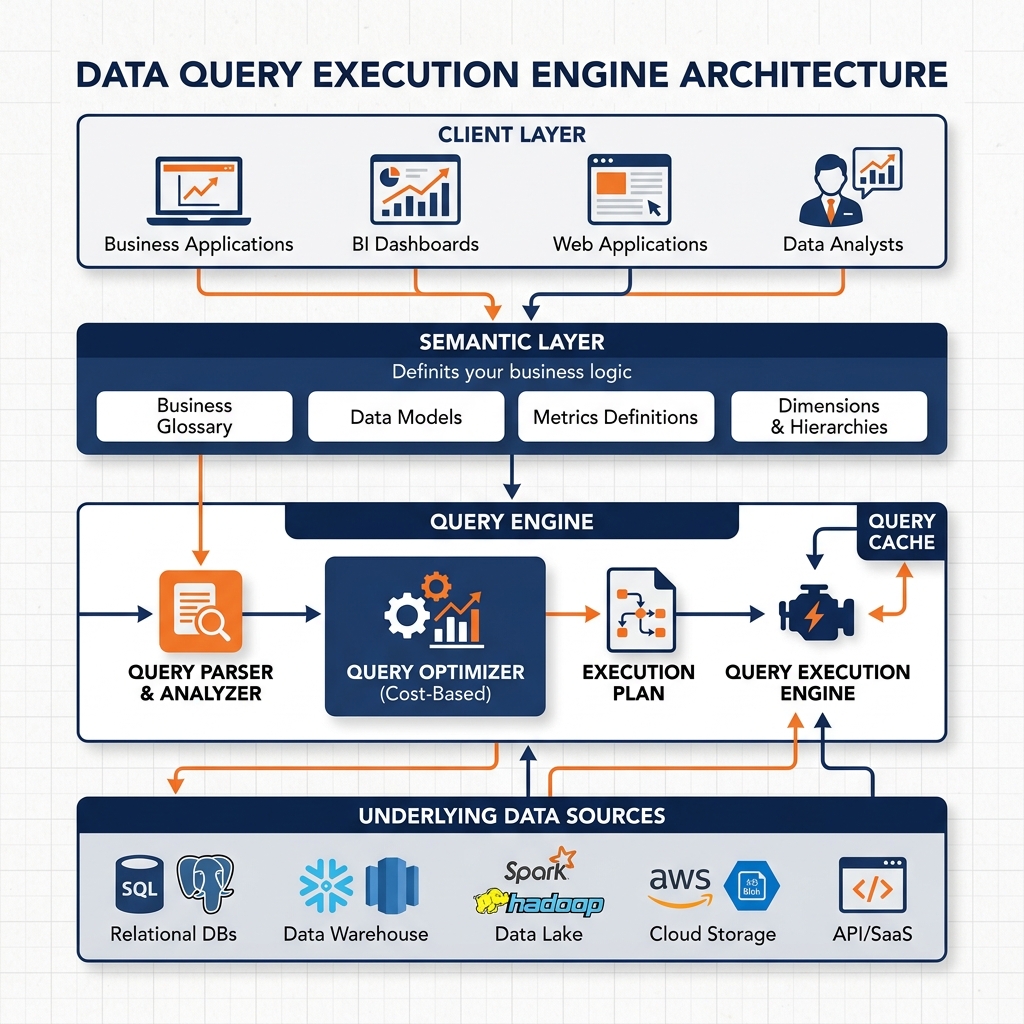
While open standards provide the blueprint for the data lakehouse, realizing its full potential requires a compute engine capable of executing complex analytics directly against object storage at interactive speeds. This is the precise engineering mandate of Dremio. Dremio is a unified lakehouse platform designed to eliminate data silos, secure object storage with Iceberg, and accelerate time-to-insight. It accomplishes this through a unique architecture that combines a high-performance SQL query engine with a governed, business-friendly semantic layer.
Zero-ETL and Direct Querying
Traditional data architectures rely on Extract, Transform, and Load (ETL) pipelines to move data from its origin into an analytical warehouse. This process is inherently brittle, resource-intensive, and introduces significant latency. Dremio operates on a Zero-ETL philosophy. It connects directly to the data where it currently resides, whether that data sits in a cloud object store like Amazon S3, a traditional relational database, or a NoSQL system.
When a user submits a SQL query, the Dremio engine performs the necessary processing in place. By querying the data directly at the source, organizations eliminate the need for costly data duplication and pipeline maintenance. Data engineers are freed from the constant burden of fixing broken ETL jobs, and business analysts gain access to real-time, up-to-the-minute data. Dremio’s native integration with Apache Iceberg ensures that these direct queries are executed with full ACID compliance and metadata-driven optimization.
The Semantic Layer
The challenge of direct querying is that raw data stored in a data lake is rarely structured in a way that is easily understood by business users. Column names might be cryptic, and critical business logic (such as calculating net revenue from multiple source tables) is often absent. To bridge the gap between physical storage and business intelligence, Dremio introduces a robust semantic layer.
The semantic layer provides a logical abstraction over the physical data. It allows data engineers and domain experts to construct virtual datasets. A virtual dataset is essentially a saved SQL query that looks and acts like a physical table to downstream users, but requires no actual data movement. Within the semantic layer, engineers can rename columns, join disparate tables, standardize formatting, and embed complex business calculations.
Because the semantic layer is centralized within Dremio, it guarantees consistency across the organization. Whether an analyst connects to Dremio using Tableau, Power BI, or a custom Python script, they all query the exact same virtual dataset. This prevents the classic analytical anti-pattern where different teams arrive at different numbers for the same metric because they applied conflicting logic in their local BI tools. The semantic layer transforms the raw data lakehouse into a governed, business-ready data fabric.
Data Reflections for Unmatched Acceleration
Querying massive datasets directly on object storage requires substantial compute power. To deliver sub-second response times for interactive BI dashboards, Dremio utilizes a proprietary acceleration technology known as Data Reflections.
Data Reflections operate similarly to traditional materialized views or database indexes, but with significantly more intelligence and automation. When a data engineer enables a Data Reflection on a specific virtual dataset, Dremio physically pre-computes and stores an optimized representation of that data, typically in Apache Parquet format. The crucial innovation of Data Reflections is that they are entirely invisible to the end user.
When an analyst submits a query against a virtual dataset, the Dremio query optimizer automatically evaluates the available Data Reflections. If a Reflection can satisfy the query faster than scanning the raw source files, Dremio seamlessly rewrites the query execution plan to read from the Reflection instead. The user never needs to know the Reflection exists or explicitly reference it in their SQL statement. This algebraic matching allows a single Data Reflection to accelerate hundreds of different, related queries. By combining the Zero-ETL direct query model with the intelligent acceleration of Data Reflections, Dremio provides the performance of a premium data warehouse at the cost and scale of a data lake.
Advanced Workloads and Agentic Analytics
The modular nature of the data lakehouse enables organizations to run drastically different workloads against the same underlying data without provisioning parallel infrastructure. In traditional architectures, a data engineering team would typically build a highly normalized data warehouse for business intelligence (BI) reporting, and a separate, unstructured data lake environment for machine learning (ML) and data science. This bifurcation led to inconsistent metrics. A data scientist’s predictive model might use a different definition of “active user” than the financial analyst’s BI dashboard, simply because they were querying different systems.
The lakehouse collapses this divide. Because the data resides in open formats on scalable object storage, an organization can attach multiple compute engines simultaneously. A BI analyst can use Dremio to execute sub-second SQL queries against an Iceberg table, while a data scientist concurrently uses Apache Spark or Python’s Polars library to train a machine learning model on the exact same Iceberg table. The semantic layer ensures that both users benefit from the same governed definitions and business logic.
The Foundation for Agentic AI
As the industry transitions from predictive machine learning to generative AI, the requirements for data architecture are shifting. Modern AI applications rely heavily on Large Language Models (LLMs). While LLMs possess vast general knowledge, they lack specific context about an organization’s proprietary data. To bridge this gap, organizations employ Retrieval-Augmented Generation (RAG). In a RAG workflow, the application retrieves relevant proprietary data from a database and injects it into the LLM’s prompt context, allowing the model to generate accurate, company-specific answers.
The data lakehouse is the ideal foundation for RAG and, by extension, Agentic AI. Agentic AI refers to autonomous systems capable of reasoning, planning, and executing complex workflows without human intervention. An AI agent might be tasked with analyzing a drop in quarterly revenue, determining the root cause, and drafting a remediation plan. To accomplish this, the agent needs uninterrupted, governed access to the entire enterprise data footprint.
If the data is siloed across dozens of proprietary SaaS applications and closed data warehouses, the AI agent will fail. It will lack the permissions or the technical ability to retrieve the necessary context. The lakehouse solves this by providing a unified, accessible data plane. With a semantic layer in place, the AI agent does not need to understand the complex, underlying physical schema of the data lake. It can simply query the semantic layer, using the exact same governed metrics that a human analyst would use. Furthermore, because Iceberg supports time travel, an AI agent can analyze historical trends by querying the exact state of a table as it existed months prior, ensuring that its analytical reasoning is built on a stable, reproducible foundation. The open lakehouse effectively turns the entire enterprise data estate into a massive, governed context window for autonomous agents.
Operations, Best Practices, and Future Outlook
While the data lakehouse simplifies architectural design, it introduces specific operational requirements that data engineers must manage to ensure long-term performance and reliability.
Compaction and Maintenance
Because the lakehouse relies on immutable object storage and table formats like Apache Iceberg, every INSERT, UPDATE, or DELETE operation generates new data files. Over time, especially in streaming or micro-batching environments, a table can fragment into thousands of tiny Parquet files. This fragmentation degrades query performance, as the compute engine spends more time opening and closing file handles than actually scanning data.
To mitigate this, data engineers must implement routine compaction strategies. Compaction is the process of reading numerous small files and rewriting them into a smaller number of large, optimized files. Iceberg provides built-in procedures to rewrite data files, expire old snapshots, and remove orphaned files. Modern lakehouse platforms often automate these maintenance tasks, ensuring that tables remain highly performant without requiring constant manual intervention from the engineering team.
Avoiding Vendor Lock-in
The primary value proposition of the data lakehouse is optionality. However, true optionality requires strict adherence to open standards at every layer of the stack. If an organization adopts a proprietary table format or relies on a closed, vendor-specific catalog, they reintroduce the very lock-in the lakehouse was designed to eliminate. Data engineers must carefully evaluate their tooling, ensuring that their chosen compute engines fully support open formats like Iceberg and open catalogs like Polaris. By controlling the storage, the format, and the catalog, the organization retains the power to swap compute engines at will, leveraging the most cost-effective or performant engine for any given workload.
Conclusion
The data lakehouse represents the convergence of storage economics and analytical performance. By layering transactionality, governance, and semantic abstraction over open object storage, it eliminates the need for brittle two-tier architectures. Platforms like Dremio, combined with standards like Apache Iceberg and Apache Arrow, empower organizations to democratize their data. As the demands of analytics evolve toward Agentic AI and real-time processing, the open lakehouse provides the scalable, governed foundation required to support the next decade of data engineering innovation.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.