Polars
A guide to Polars, the Rust-native DataFrame library that delivers blazing-fast in-process analytical query performance in Python and Rust, becoming a high-performance alternative to pandas for data engineering workflows.
The pandas Performance Problem
Pandas is the bedrock of Python data science, but its performance characteristics have always been a limitation. Pandas operates single-threaded on a single CPU core, stores data in NumPy arrays that are often memory-inefficient for mixed-type DataFrames, and copies data extensively during transformation operations. A pandas pipeline processing a 5GB CSV file on a 16-core machine with 64GB of RAM uses one core and may require 15-20GB of memory due to intermediate copies.
Polars was created to deliver orders-of-magnitude better performance for DataFrame operations by applying modern systems programming techniques to the DataFrame model. Polars is implemented in Rust, uses Apache Arrow as its internal memory format, executes queries in parallel across all available CPU cores, and applies lazy query optimization (analogous to a SQL query planner) to compute only the minimal set of operations needed to produce the final result.
The combination of these design choices produces benchmark results that consistently show Polars completing common DataFrame operations 5-30x faster than pandas on the same hardware, with significantly lower memory consumption due to Arrow’s columnar format and Polars’ avoidance of excessive intermediate copies.
The Arrow Foundation
Polars stores all DataFrame columns in Apache Arrow columnar arrays. This Arrow foundation provides several performance advantages. Arrow’s columnar layout enables SIMD (Single Instruction Multiple Data) CPU instructions to process 8 or 16 values simultaneously in a single CPU instruction, providing vectorized computation throughput that scalar row-by-row processing cannot match. Arrow’s zero-copy sharing enables Polars DataFrames to be passed to DuckDB, PyIceberg, and other Arrow-native libraries without copying data, enabling zero-overhead interoperability between components of the Python analytics stack.
Polars’ lazy evaluation model (the LazyFrame API) allows a sequence of operations to be planned as a query graph before any execution occurs. The query planner applies optimizations like predicate pushdown (filtering early to reduce data volume), projection pushdown (reading only needed columns), and common subexpression elimination before executing the query, similar to how a SQL query planner optimizes a SQL query before execution.
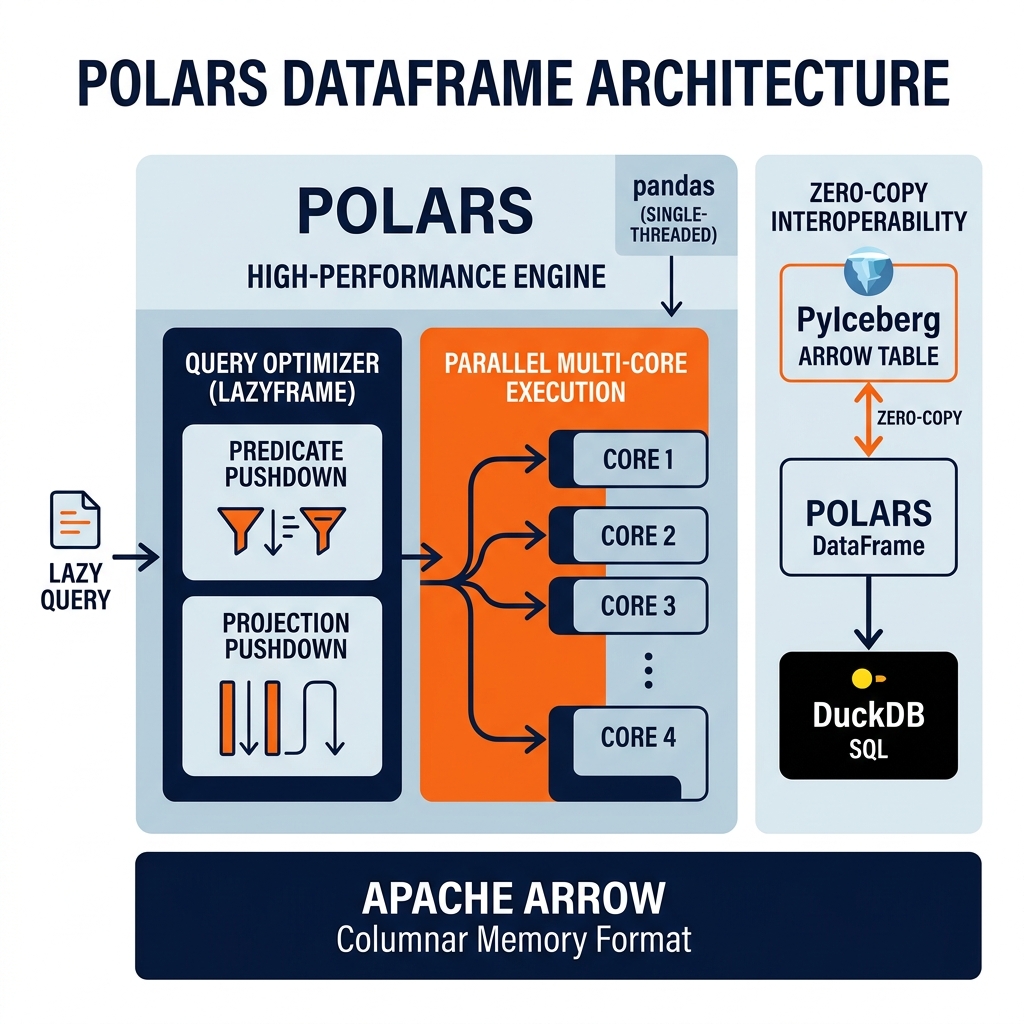
Polars in the Iceberg Lakehouse
Polars integrates naturally with the Iceberg lakehouse stack through its Arrow compatibility. PyIceberg’s table scan returns an Apache Arrow Table; Polars reads Arrow Tables with zero data copying: pl.from_arrow(iceberg_table.scan().to_arrow()). This PyIceberg + Polars combination provides a fast, pure-Python Iceberg data access stack without Spark or Dremio, suitable for data science notebooks and lightweight pipeline scripts.
DuckDB also integrates with Polars DataFrames through Arrow, enabling SQL queries against Polars DataFrames: duckdb.execute("SELECT * FROM df WHERE amount > 1000", {"df": polars_df}). The three-way integration of PyIceberg (Iceberg catalog access), Polars (fast DataFrame transformations), and DuckDB (SQL queries on DataFrames) provides a complete Python-native data engineering stack capable of processing hundreds of gigabytes on a single machine without a JVM.
For production pipelines processing terabytes, Dremio or Spark remain the appropriate execution engines. For local development, data science exploration, and medium-scale pipeline steps, the Polars stack provides exceptional performance with a clean Python API.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.