Predicate Pushdown
A guide to predicate pushdown, the query optimization technique that evaluates filter conditions as close to the data source as possible to minimize the volume of data read and transferred through the query pipeline.
Moving Filters Closer to the Data
A SQL query is a declarative specification: it describes what data should be returned, not how to retrieve it. A query engine translates this specification into an execution plan that fetches data from storage and processes it through a pipeline of operators (scans, filters, joins, aggregations). The order and placement of these operators has profound performance implications.
The naive execution plan for a query with a WHERE clause reads all data from the table, loads it into memory, and then applies the filter predicate to discard non-matching rows. For a 10TB table where the filter matches only 0.1% of rows (10GB), this naive plan reads and transfers 10TB to discard 99.9% of it, resulting in enormous wasted I/O.
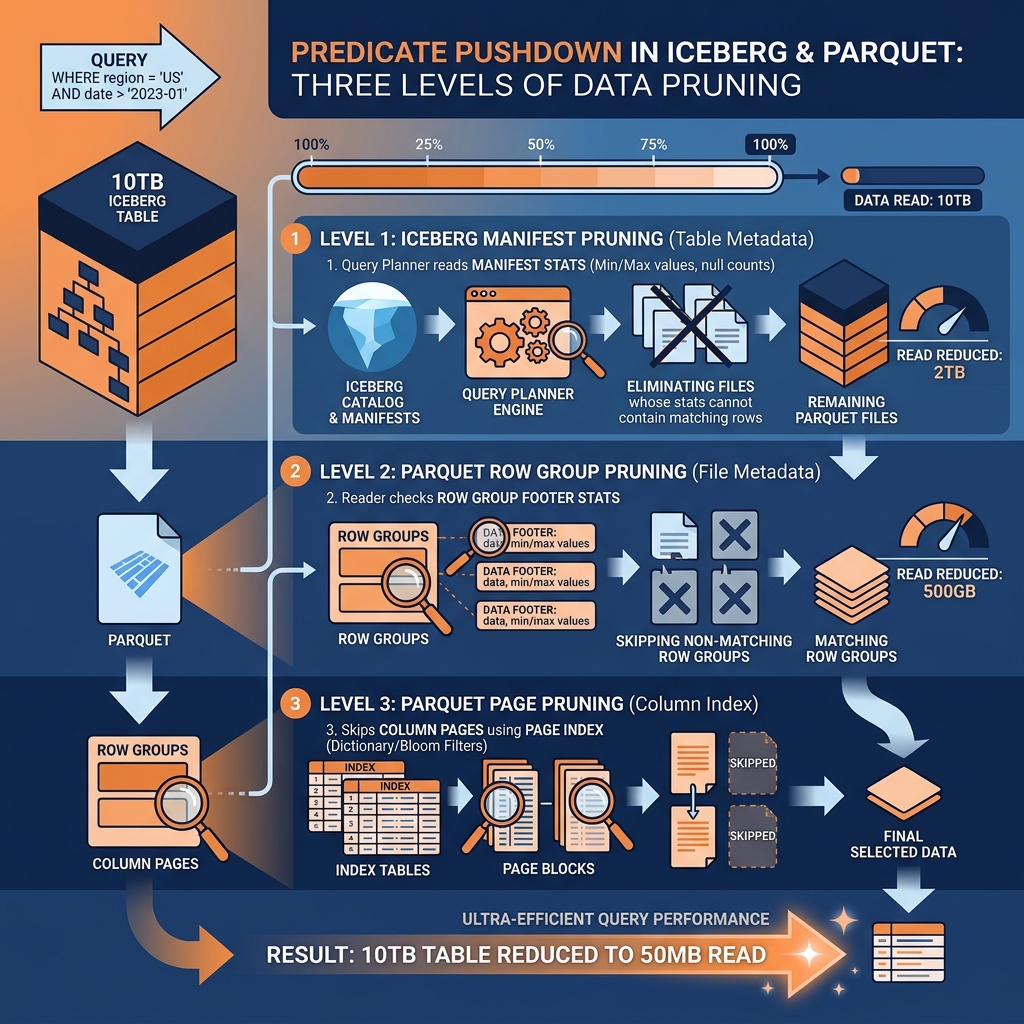
Predicate pushdown is the query optimization technique that moves filter evaluation as early in the execution pipeline as possible, eliminating non-matching data before it is read or transferred. In a query against an Iceberg table in S3, effective predicate pushdown means evaluating filter conditions at the Iceberg metadata level (eliminating entire data files without reading them), at the Parquet row group level (eliminating row groups within files without reading them), and at the Parquet page level (eliminating column pages within row groups without decompressing them). The goal is to read only the bytes that contribute to the query result.
Three Levels of Pushdown in Iceberg and Parquet
Iceberg manifest-level pushdown: Iceberg manifests store file-level column statistics (min value, max value, null count) for each data file. When a query filter is WHERE event_date = '2024-01-15', the query planner reads the manifest and eliminates every data file whose max event_date is earlier than ‘2024-01-15’ or min event_date is later than ‘2024-01-15’. Only files that might contain matching rows are passed to the executor. For well-partitioned and Z-ordered tables, this eliminates the vast majority of data files without reading a single byte of actual data.
Parquet row group-level pushdown: Each Parquet file contains multiple row groups (typically 128MB each), and each row group stores column-level min/max statistics and bloom filter data in its row group metadata (footer). The Parquet reader evaluates the filter predicate against each row group’s statistics before reading the row group data. Row groups whose min/max range cannot contain matching values are skipped entirely without decompressing their column pages.
Parquet page-level pushdown: Within a row group, each column’s data is stored as a sequence of pages (8KB-1MB each). Parquet page-level index (introduced in Parquet 2.0) records the min/max values for each page, enabling the reader to skip individual pages within a row group when the filter value falls outside the page’s range.
Predicate Pushdown in Dremio
Dremio’s query planner aggressively pushes predicates down through all available optimization layers. When a query with WHERE clause filters is planned against an Iceberg table, Dremio’s planner first applies the filter to the Iceberg manifest to prune files, then configures the Parquet scanner to apply row-group-level statistics filtering, and finally applies the column-level predicate within each row group’s column scan.
The result of this multi-level pushdown is that the ratio of data read to data actually matching the query can be extremely low. A query against a properly organized 10TB Iceberg table might read only 50MB of Parquet data to return 100,000 matching rows, a 200,000:1 data reduction ratio from the naive full-scan baseline.
Predicate pushdown effectiveness depends critically on the data organization quality. Tables with good partition pruning, Z-ordering, and tight file-level column statistics enable dramatic pushdown effectiveness. Poorly organized tables (random file order, wide min/max ranges per file) provide much less pushdown opportunity. This is why compaction, Z-ordering, and statistics collection are not just housekeeping operations but directly determine the analytical query performance of the lakehouse.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.