DuckDB
A guide to DuckDB, the embeddable in-process analytical database engine that brings high-performance columnar SQL analytics to local workloads, notebooks, and serverless environments.
A Database That Lives Inside Your Process
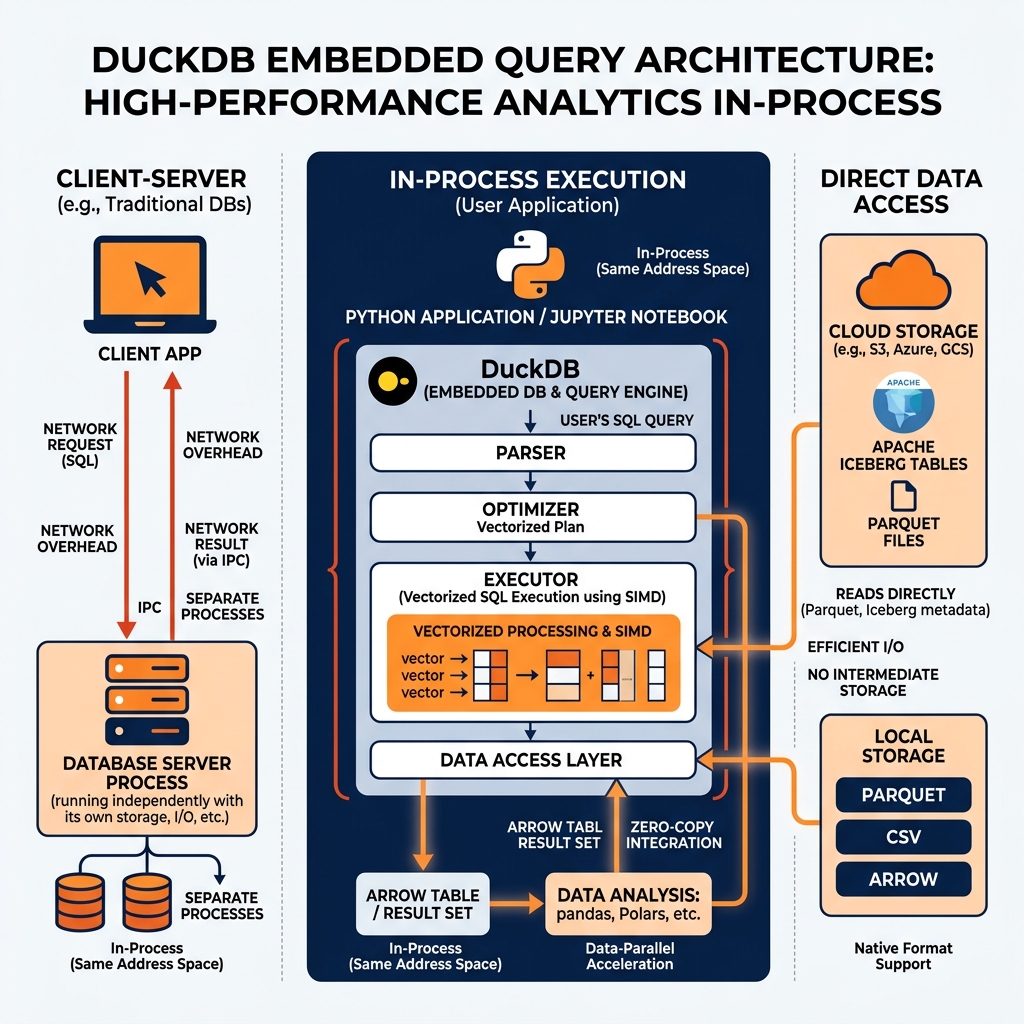
DuckDB occupies a unique position in the data engineering landscape: it is a full-featured analytical SQL engine that runs embedded within the same process as the application using it, with no separate server, no network connection, and no configuration required. A Python script can import DuckDB, load a 100GB Parquet file, run complex analytical SQL queries against it, and receive results, all in-process, without any external infrastructure.
This embedded architecture is DuckDB’s defining characteristic. SQLite is the canonical embedded database for transactional workloads; DuckDB is SQLite’s analytical counterpart for OLAP workloads. Where SQLite stores data in a row-oriented format optimized for single-row lookups, DuckDB uses a vectorized columnar execution engine that processes analytical queries against large datasets with performance comparable to specialized cloud data warehouses.
The practical implications are significant for data engineers and data scientists. Local development and testing of analytical pipelines no longer requires standing up a Spark cluster or connecting to a cloud data warehouse. A data scientist building a new transformation can test it against a 50GB sample dataset on their laptop using DuckDB, validating the logic and performance characteristics before deploying the production job to a distributed cluster. This dramatically shortens the development feedback loop.
Vectorized Query Execution
DuckDB’s query engine uses a vectorized execution model, the same architectural approach that powers cloud data warehouses like Snowflake. Rather than processing one row at a time (the classic Volcano model used by most traditional databases), vectorized execution processes data in column batches of 1,024 to 2,048 values at a time.
This batch processing model aligns with modern CPU architecture. When a filter predicate is applied to a batch of 1,024 integer values stored contiguously in memory, the CPU’s SIMD (Single Instruction, Multiple Data) instructions can evaluate the predicate against multiple values simultaneously in a single clock cycle. DuckDB’s vectorized operators (filters, projections, aggregations, hash joins) are implemented using these SIMD-optimized routines, delivering analytical performance that approaches the theoretical limit of the CPU’s data processing throughput.
DuckDB also implements parallel query execution across all available CPU cores. A query that scans a 10GB Parquet file is automatically parallelized across all CPU cores, with each core processing a separate portion of the data. The partial results from each core are merged by the query coordinator to produce the final answer.
DuckDB and Apache Iceberg
DuckDB’s Iceberg extension allows DuckDB to read Apache Iceberg tables stored in local filesystems or cloud object storage (S3, ADLS, GCS). The Iceberg extension reads the Iceberg metadata layer to identify the current table snapshot and the relevant Parquet data files, then reads those files directly using DuckDB’s native Parquet reader.
This Iceberg integration makes DuckDB a powerful lightweight tool for exploring and validating lakehouse data without requiring a running compute cluster. A data engineer debugging an Iceberg table can query it from a local Python notebook using DuckDB, running the same SQL they would run in Dremio or Spark but with zero infrastructure overhead and sub-second query startup time.
DuckDB’s Arrow integration provides a high-performance path for exchanging data with Python analytical libraries. DuckDB can directly consume Arrow Tables (from Dremio query results received via Arrow Flight, or from PyArrow memory), query them with SQL, and return results as Arrow Tables. This zero-copy pipeline from Dremio through Arrow Flight to DuckDB to pandas represents one of the most efficient data analysis workflows currently available.
DuckDB in Production Lakehouse Architectures
While DuckDB is most commonly associated with local and notebook-based analytics, it is increasingly used in production architectures for specific use cases where its embedded nature is an advantage rather than a limitation.
Serverless analytics functions (AWS Lambda, Google Cloud Functions) benefit from DuckDB’s ability to execute complex SQL queries against Parquet files in S3 without any persistent infrastructure. A Lambda function can use DuckDB to compute aggregations over a Parquet-formatted daily report file, produce a summary JSON result, and terminate, with no persistent database process to manage.
MotherDuck, the managed cloud service for DuckDB, extends DuckDB to cloud-scale workloads through a hybrid local-cloud execution model. Queries can run partially on the local DuckDB instance and partially on MotherDuck’s cloud infrastructure, enabling interactive analysis of datasets too large to fit in local memory.
As the Iceberg ecosystem matures, DuckDB’s role as a lightweight query layer for local lakehouse development and debugging is likely to grow. The combination of DuckDB’s local query speed, Iceberg’s open table format, and Dremio’s governed production query layer forms a natural development-to-production workflow: develop and test locally with DuckDB, deploy to production with Dremio.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.