Project Nessie
A guide to Project Nessie, the open-source transactional catalog for data lakes that brings Git-like branching, tagging, and merging semantics to Apache Iceberg table management.
Git Semantics for Data Lakehouses
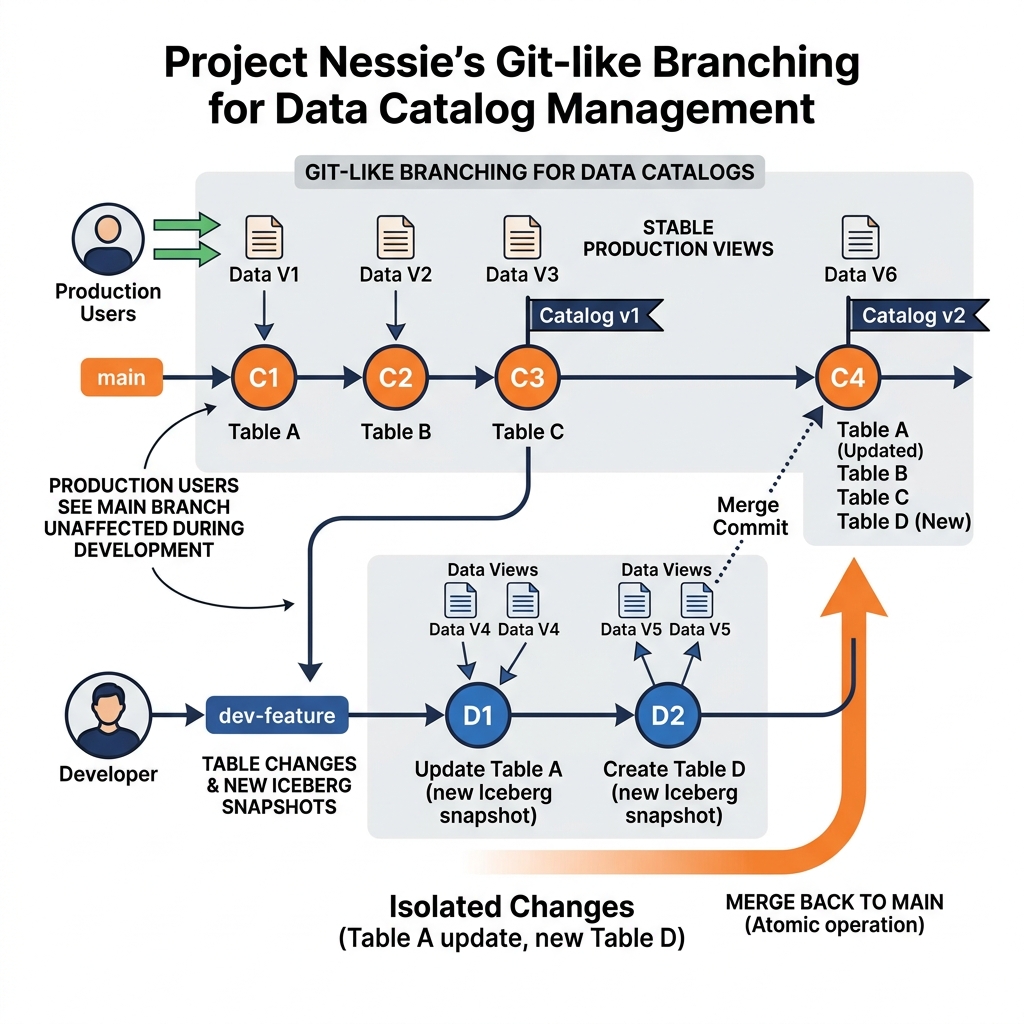
Project Nessie is an open-source catalog developed by Dremio that applies the branching and merging concepts of Git version control to the management of Apache Iceberg tables. The core insight behind Nessie is that data engineers working on complex transformations, schema migrations, and data quality validations face problems analogous to those software engineers face when modifying code: they need to work in isolation without affecting production users, test changes against real data before committing, and merge their changes back into the main data branch when ready.
Without branching semantics, data engineers must either apply all changes directly to the production tables (risking broken dashboards and wrong reports during the development process) or maintain expensive physical copies of production tables for development and testing (doubling storage costs and creating synchronization challenges). Nessie resolves this dilemma by providing lightweight logical branches that create an isolated view of the data catalog without physically copying any data files.
When a data engineer creates a Nessie branch, they get a snapshot of the catalog at that moment. All table operations performed on the branch (creating new tables, appending data, running transformations) are recorded in the Nessie branch’s commit history and affect only that branch. The main production branch continues serving analysts with the unmodified production state. When the engineer is satisfied with their work, they merge the branch back into main with a single operation, atomically advancing the production catalog state to include all the branch’s changes.
The Nessie Commit Model
Nessie models the catalog state as a commit graph with branches and tags, structurally identical to a Git repository. Each catalog operation (creating a table, modifying a table’s current Iceberg snapshot pointer, dropping a table) is recorded as an immutable commit. Each commit has a unique hash, a reference to its parent commit(s), and a description of the catalog operations it contains.
A branch is simply a named pointer to a specific commit in this commit graph. When new commits are added to a branch, the branch pointer advances to the latest commit. The main branch represents the production catalog state. Developer branches can diverge from main, accumulate their own commits, and be merged back when ready.
The critical insight is that Nessie does not store data files. It stores only pointers to Iceberg table metadata files. When a Nessie commit records that a table named customer_events has a new Iceberg snapshot, it stores the path to the new Iceberg metadata file that describes that snapshot. The actual Parquet data files remain on object storage unchanged. This means that creating a Nessie branch and making extensive table modifications costs almost nothing in storage: only the Nessie commit records and Iceberg metadata files are created for branch operations; no data is physically copied.
Practical Branching Workflows
Development and Testing Branches: A data engineer working on a new transformation pipeline creates a feature/new-revenue-model branch from main. She runs her transformation jobs, which create new Iceberg tables and modify existing ones on her branch. She queries her branch through Dremio (which supports Nessie as a catalog source) to validate the results against production-realistic data. When the results are correct, she merges her branch back to main, atomically making the new tables and updated snapshots available to all production consumers.
ETL Pipeline Isolation: Multiple ETL pipelines can run against separate Nessie branches simultaneously, each working with its own isolated view of the catalog state. When all pipelines complete successfully, their branches are merged to main in a coordinated release. Failed pipelines can be abandoned by simply discarding their branches, with no cleanup of production data required.
Data Quality Gates: Before merging a development branch to main, automated data quality checks can run against the branch’s tables. If any quality checks fail, the merge is blocked and the engineer corrects the issues on the branch before retrying the merge. This quality gate pattern prevents bad data from ever reaching production consumers.
Nessie and Dremio Arctic
Dremio integrates Project Nessie natively through its Arctic capability, providing a managed Nessie service that is deeply integrated with Dremio’s query and governance infrastructure. When an organization uses Arctic as its catalog, data engineers can create and manage branches through Dremio’s UI, run SQL queries against specific branches directly from Dremio’s SQL editor, and merge branches through Dremio’s data management interface.
The combination of Nessie’s branching semantics and Dremio’s Semantic Layer creates a powerful development workflow. Data engineers can build and test new virtual datasets on a development branch, validate the results using Dremio’s query engine, and promote the branch to production when ready, all within a single, unified data platform interface.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.