Data Catalog
A guide to enterprise data catalogs, the metadata management platforms that make data assets discoverable, understandable, and trustworthy for both human analysts and AI-powered analytical systems.
The Discovery Problem at Scale
A medium-sized enterprise data platform contains thousands of tables, hundreds of dashboards, dozens of pipelines, and petabytes of data. A new data scientist joining the team faces an immediately paralyzing question: what data is available, what does it mean, how was it produced, how current is it, and who owns it?
Without a data catalog, the answer involves scheduling meetings with data engineers to ask what tables exist, reading undocumented SQL code to understand transformation logic, querying table schemas directly to guess at column semantics, and asking colleagues which tables are trustworthy versus abandoned. This knowledge is entirely person-dependent: when the data engineer who built a critical pipeline leaves the organization, their knowledge of what the pipeline produces and how it should be interpreted leaves with them.
A data catalog is the solution to this discovery problem. It is a centralized metadata repository and search interface that makes every data asset in the organization discoverable through a search interface (by name, description, tag, or semantic concept), understandable (with business descriptions, column-level documentation, and lineage graphs), and trustworthy (with quality scores, usage statistics, and certification labels from data owners).
What a Data Catalog Manages
The scope of a modern data catalog extends beyond simple table listings. A comprehensive data catalog manages multiple categories of metadata.
Technical metadata describes the structure of data assets: table schemas, column names and types, partition information, file formats, storage locations, row counts, and size statistics. This metadata is typically harvested automatically by the catalog through connectors that scan data sources (Iceberg catalogs, Hive Metastore, Glue, operational databases) without manual input.
Business metadata describes the meaning and business context of data assets: the business definition of the net_revenue column (gross sales minus returns and discounts), the business owner of the customer_360 dataset, the target audience for a specific dashboard, and the data domain (Finance, Marketing, Operations) each asset belongs to. Business metadata is typically entered manually by data owners and stewards through the catalog’s annotation interface.
Operational metadata describes the operational characteristics of data assets: pipeline run history, last refresh timestamp, data freshness (how recently the data was updated relative to its expected refresh schedule), quality score history, and usage statistics (which users query this table most frequently, which dashboards depend on it).
Lineage metadata describes the ancestry and downstream dependencies of each data asset: which source systems and upstream tables were used to produce this table, which downstream tables and dashboards consume it.
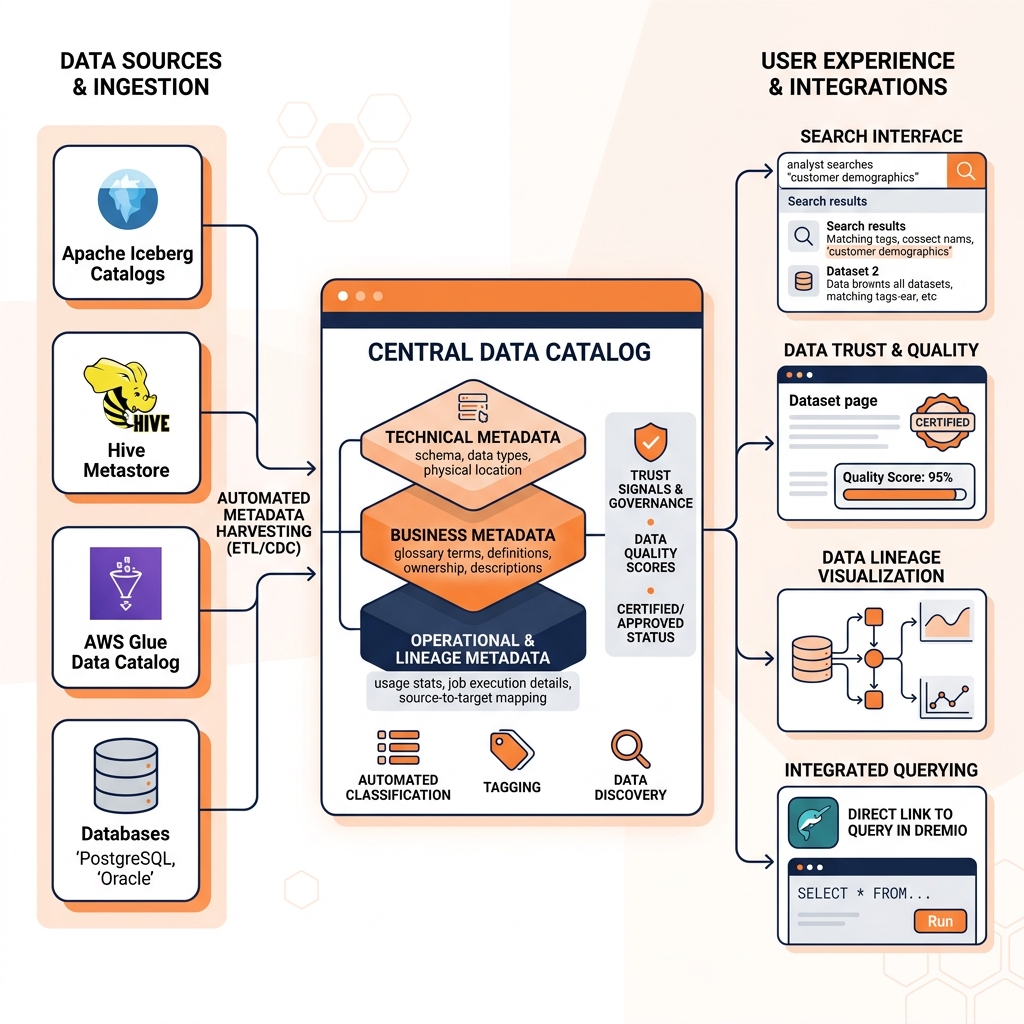
Catalog Discovery and Search
The user-facing capability that justifies a data catalog’s existence is search. A data scientist looking for customer demographic data types “customer demographics” into the catalog’s search interface and sees a ranked list of tables, columns, and dashboards that match the query. The search results include trust signals (certified by the Data Engineering team), freshness indicators (updated daily, last refresh 2 hours ago), and usage metrics (queried by 47 users this month). The scientist can browse to the table’s detail page, read the business description, see the column-level definitions, view the lineage graph showing where the data came from, and click through to query it in Dremio, all without ever leaving the catalog interface.
Modern catalogs like Collibra, Alation, DataHub, and Apache Atlas implement AI-powered semantic search that matches synonyms and business concepts rather than requiring exact name matches. Searching “revenue” finds tables containing gross_sales, net_income, and order_value columns because the AI semantic layer understands these are revenue-related concepts.
Data Catalog and Apache Iceberg
Apache Iceberg’s rich metadata layer provides high-quality technical metadata for data catalog ingestion. Iceberg’s schema history, snapshot timeline, partition specifications, and file-level statistics give catalog connectors detailed technical information to harvest automatically. The snapshot timeline provides exact timestamps for every historical table state, enabling precise freshness calculations. The file-level column statistics enable quality-adjacent metrics like null rates and value distributions.
Dremio’s internal catalog exposes technical metadata for all Iceberg tables and Virtual Datasets registered in Dremio, serving as a metadata source for external data catalog platforms. Organizations using enterprise catalogs like Collibra or Alation can configure connectors that harvest Dremio’s metadata, populating the enterprise catalog with up-to-date schema, lineage, and usage information from the Dremio environment automatically.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.