Semantic Search
A guide to semantic search, the AI-driven methodology that retrieves information based on the contextual meaning and intent of a query, rather than relying on exact keyword matching.
Searching for Meaning, Not Words
For the first thirty years of the commercial internet, search was almost entirely lexical (keyword-based). When a user typed “affordable car insurance” into a search bar, the database engine (like Elasticsearch or a standard SQL LIKE '%affordable car insurance%' query) scoured the text corpus looking for the exact presence of those specific three words.
If a document was titled “Cheap Auto Coverage,” the keyword search would completely miss it, because the literal strings of characters did not match, even though the human meaning was identical.
Semantic search fundamentally changes this paradigm. Instead of searching for matching character strings, semantic search engines search for matching concepts and contextual intent. When a user searches for “affordable car insurance,” the system understands that “cheap” is a synonym for “affordable,” and “auto coverage” is semantically equivalent to “car insurance,” returning the highly relevant document that a keyword search would have ignored.
How Semantic Search Works
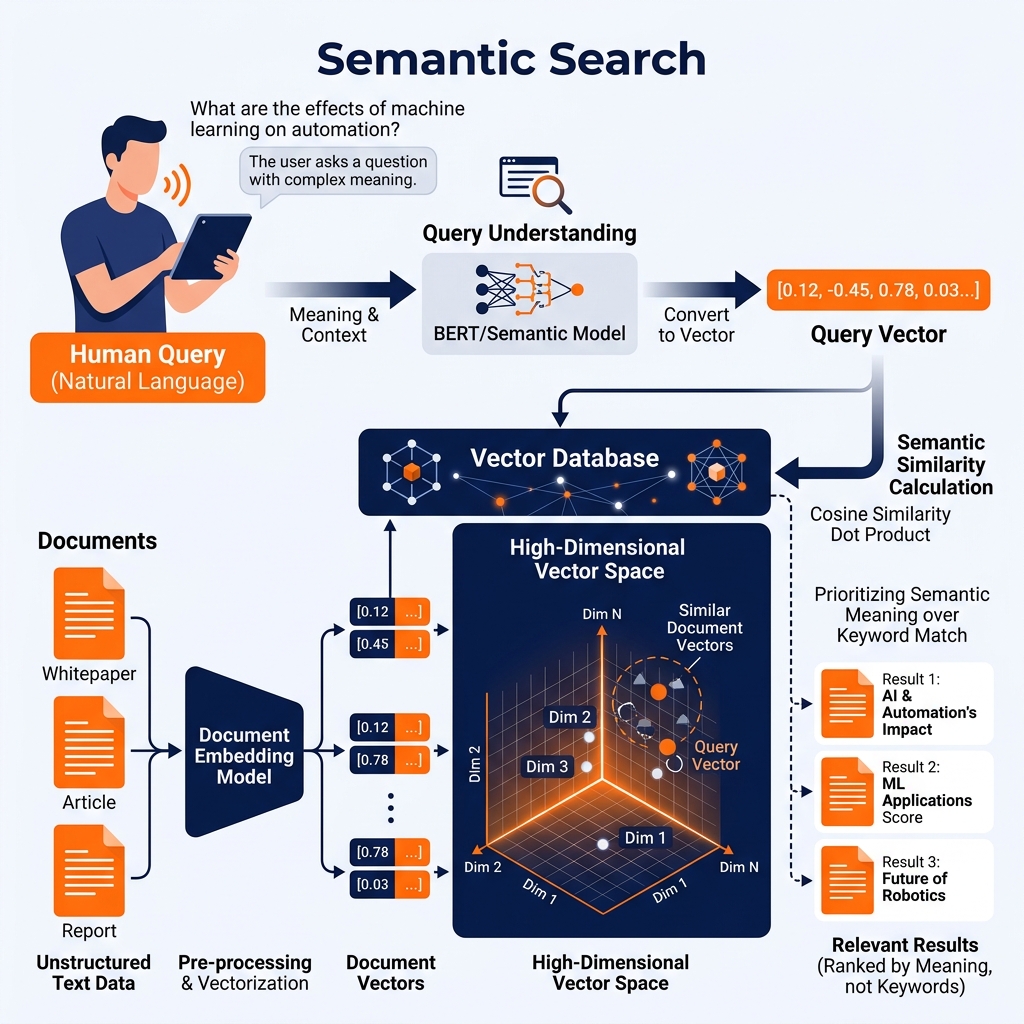
The magic of semantic search is powered by Large Language Models (LLMs) and Vector Embeddings.
1. Creating the Embeddings: The semantic search pipeline begins by passing every document in the corporate knowledge base through an embedding model (like OpenAI’s text-embedding-ada-002). The model reads the text and converts its semantic meaning into a dense vector-a massive array of floating-point numbers (often 1,536 dimensions long). These vectors are stored in a specialized Vector Database (like Pinecone, Milvus, or pgvector).
2. Query Translation: When a user types a search query (“How do I reset my password?”), the system passes that query through the exact same embedding model, generating a “Query Vector.”
3. Mathematical Similarity: The Vector Database then performs a mathematical operation (usually Cosine Similarity or K-Nearest Neighbors) to compare the Query Vector against millions of Document Vectors in milliseconds. Documents that are conceptually similar will reside physically close to each other in the high-dimensional vector space. The database returns the documents with vectors closest to the query vector.
Enterprise Applications
Semantic search is the foundational technology powering the modern AI revolution in the enterprise, specifically Retrieval-Augmented Generation (RAG).
When an employee asks an internal AI chatbot a complex HR question, the chatbot does not rely on its underlying generic training data. Instead, it executes a semantic search against the company’s internal HR policy documents. It retrieves the three most conceptually relevant paragraphs (even if the employee used completely different phrasing than the official policy manual), and feeds those paragraphs into an LLM to generate a perfectly accurate, context-aware answer.
Semantic search unlocks the value of the massive troves of unstructured data (PDFs, transcripts, emails) sitting dormant in the data lake.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.