Large Language Models
A guide to Large Language Models (LLMs), the massive neural networks built on the Transformer architecture that power modern AI by understanding, generating, and translating human language at an unprecedented scale.
The Engine of the AI Revolution
For decades, getting computers to understand human language was a brittle, frustrating process. Early Natural Language Processing (NLP) relied on hard-coded grammar rules and dictionaries. If a human used slang, sarcasm, or complex sentence structures, the computer failed to understand the intent.
Large Language Models (LLMs) completely revolutionized this field. An LLM (like GPT-4, Claude, or LLaMA) is a specific type of Generative AI model designed exclusively to understand and generate text. They do not rely on grammar rules; they rely on pure statistical probability derived from reading billions of pages of human text.
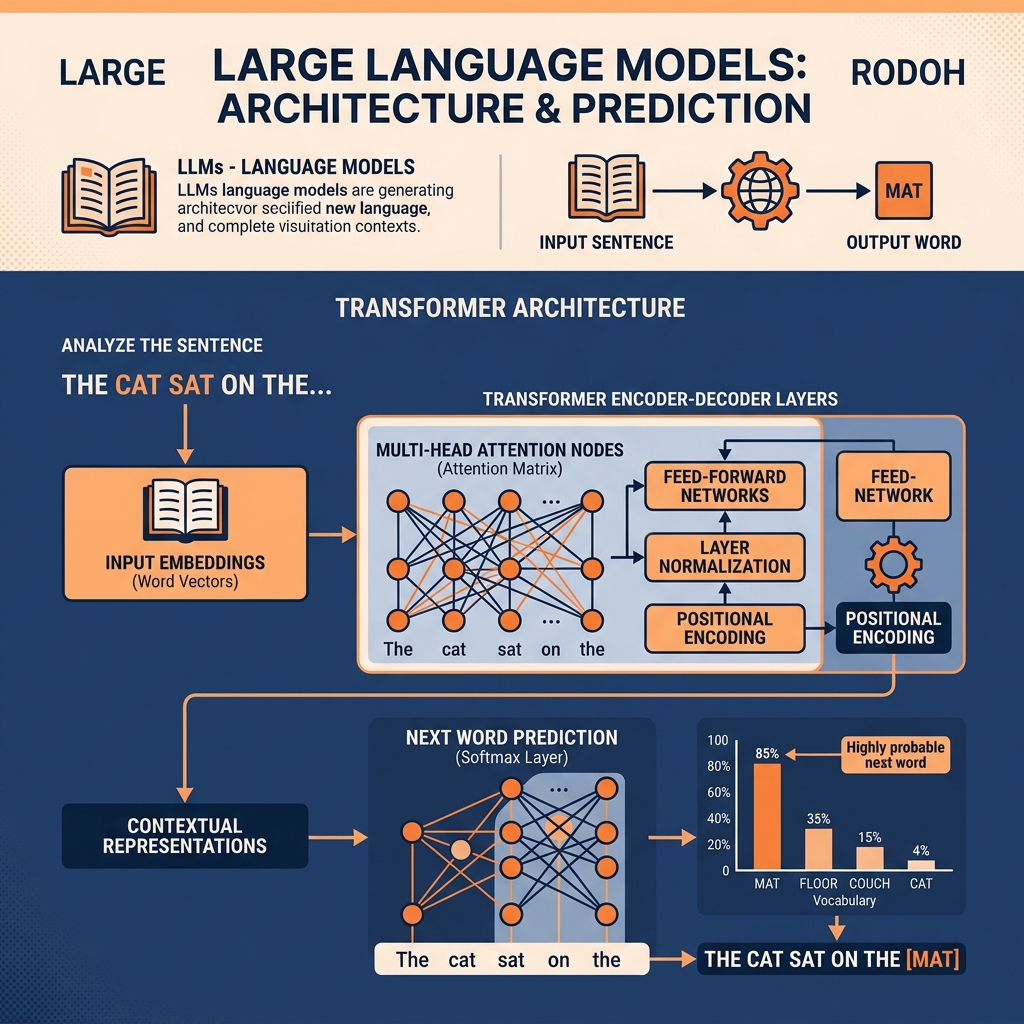
The Transformer Architecture
The breakthrough that made LLMs possible was the invention of the “Transformer” architecture by Google researchers in 2017.
Older language models read text sequentially, word by word. By the time they reached the end of a long paragraph, they “forgot” what the first sentence was about.
Transformers use a mechanism called Self-Attention. When a Transformer reads a sentence, it looks at every single word simultaneously and calculates how strongly each word relates to every other word in the sentence, regardless of how far apart they are. If the sentence says, “The bank of the river was muddy, so he couldn’t deposit his boat,” the self-attention mechanism instantly understands that the word “bank” refers to a muddy shoreline, not a financial institution, based on its mathematical relationship to the words “river” and “muddy.”
Scale is All You Need
What makes an LLM “Large”? It comes down to two factors: the size of the training data and the parameter count.
Training Data: LLMs are trained on massive scrapes of the internet (Wikipedia, Reddit, entire libraries of books, GitHub code repositories). This exposes the model to every conceivable nuance of human language, factual knowledge, and logical reasoning.
Parameters: Parameters are the internal mathematical weights inside the neural network. A model like GPT-3 has 175 billion parameters. These billions of numbers capture the incredibly complex, high-dimensional statistical relationships between words.
The astonishing discovery of LLMs is that as you increase the parameter count and the training data, the models develop “Emergent Abilities.” A model trained simply to “guess the next word in a sentence” suddenly becomes capable of writing poetry, debugging Python code, translating French to Japanese, and passing the Bar Exam, simply because those logical structures are embedded within the statistical fabric of human language.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.