Vector Embeddings
A guide to vector embeddings, the mathematical representations of unstructured data (text, images, audio) that allow machine learning models to understand and compute the conceptual similarities between complex objects.
Translating Concepts into Math
Computers are incredibly fast at comparing numbers, but they natively understand nothing about language, images, or human concepts. If you ask a standard SQL database if the word “King” is related to the word “Queen”, it can only tell you that the ASCII character strings are completely different.
Vector embeddings are the bridge that translates human concepts into a mathematical format that computers can process. An embedding is simply an array of continuous floating-point numbers (a vector) that captures the semantic meaning of an object.
By converting words, sentences, or even entire images into vectors, we project them into a high-dimensional mathematical space. The core principle of embeddings is spatial proximity: objects that are conceptually similar in the real world will be placed mathematically close to each other in the vector space.
The Geometry of Meaning
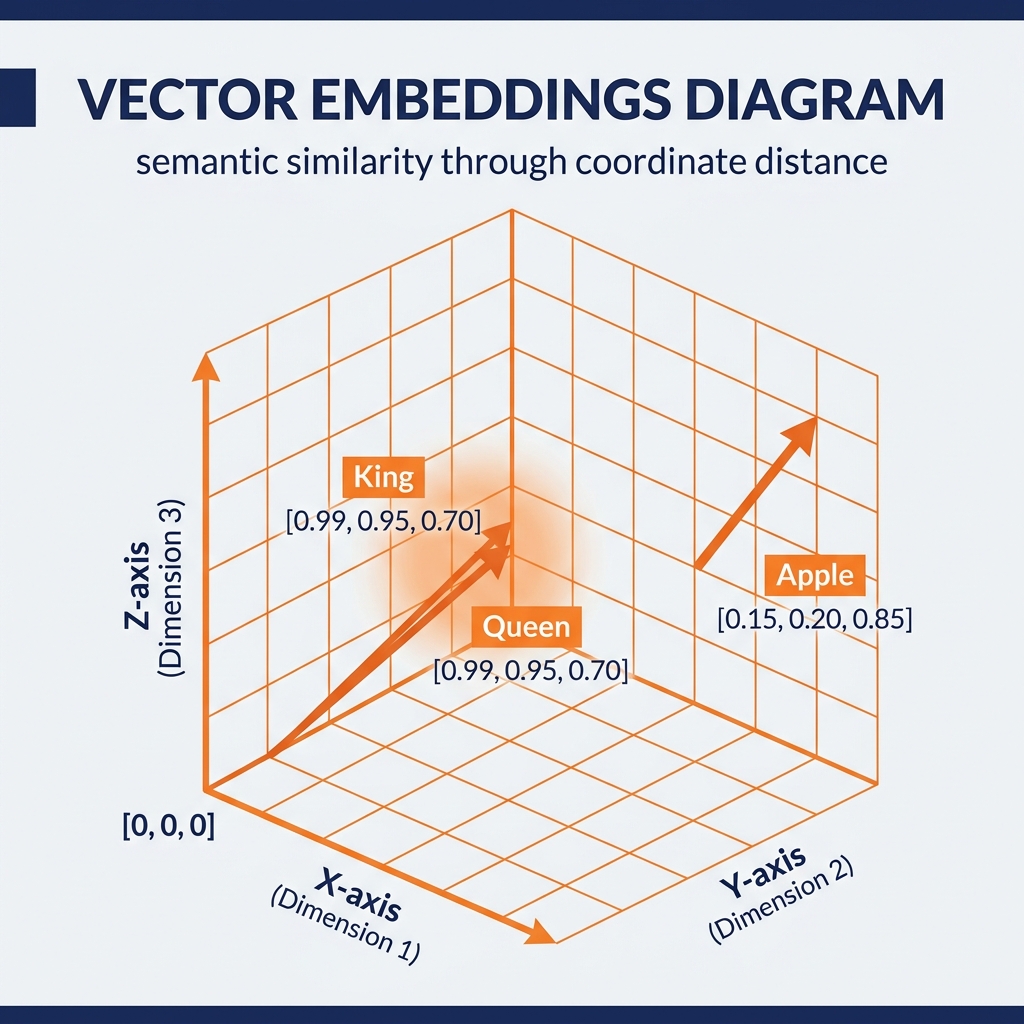
Consider a highly simplified, three-dimensional embedding space where the dimensions represent the concepts of [Royalty, Masculinity, Age].
If we embed the word “King,” the model might assign it the vector [0.99, 0.95, 0.70] (Highly Royal, Highly Masculine, Older).
If we embed the word “Queen,” the model assigns it the vector [0.99, 0.05, 0.70] (Highly Royal, Low Masculinity/Feminine, Older).
If we embed the word “Apple,” the model assigns it [0.01, 0.50, 0.10] (Not Royal, Neutral, Young/Fresh).
If a computer calculates the mathematical distance (using Cosine Similarity) between these vectors, it instantly realizes that “King” is geometrically much closer to “Queen” than it is to “Apple.”
Real-world embedding models (like OpenAI’s models or BERT) don’t use 3 dimensions; they use 768 or 1,536 dimensions, capturing incredibly subtle nuances of grammar, context, and syntax that humans cannot even define.
Generating and Using Embeddings
The Generation Process: Data engineers extract unstructured data from the data lake (e.g., millions of customer product reviews). They pass this text through a pre-trained neural network. The neural network’s hidden layers generate the high-dimensional vectors.
Storage: Because relational databases struggle to execute mathematical similarity searches across billions of 1,536-dimension arrays efficiently, these embeddings are loaded into specialized Vector Databases (like Pinecone, Weaviate, or Milvus) which index the vectors for sub-second retrieval.
Multimodal Embeddings: The true power of modern embeddings is that they are not limited to text. Models like CLIP can embed an image (a picture of a red shoe) and a text string (“ruby colored sneaker”) into the exact same vector space. Because the concepts are identical, their mathematical vectors will land close to each other, allowing users to type a text query and instantly search a database of millions of un-tagged images.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.