Data Migration
A guide to data migration, the complex engineering process of securely and accurately transferring massive datasets from legacy systems (like on-premises data warehouses) to modern cloud architectures like the data lakehouse.
Moving the Mountain
The transition from legacy on-premises data warehouses (like Teradata or Oracle) or first-generation Hadoop clusters to modern cloud data lakehouses (using Apache Iceberg) is rarely a simple “copy-paste” operation.
Data migration is the highly planned, complex engineering process of transferring data, schema definitions, and transformation logic from a source system to a target system. Because the source system is typically powering critical daily business operations, a migration must be executed without data loss, without corrupting data integrity, and ideally with minimal downtime for the business users.
A successful migration is not just moving bytes over a network; it is an opportunity to refactor technical debt, modernize pipelines, and embrace new architectural paradigms.
The Phases of Data Migration
A massive enterprise data migration typically follows a structured, multi-phase approach:
1. Assessment and Profiling: The team audits the legacy system to identify what data actually needs to move. Often, 30% of a legacy data warehouse consists of abandoned tables and obsolete reports. Profiling identifies dependencies, data quality issues, and the specific SQL dialects that must be rewritten for the new engine.
2. Schema Translation and Provisioning: The physical table structures are mapped to the new system. A proprietary legacy schema is translated into open Apache Iceberg table definitions.
3. Initial Bulk Load (The Big Bang): The historical data is extracted from the legacy system and loaded into the cloud lakehouse. For petabyte-scale migrations, this is often done using physical hard drives shipped to the cloud provider (e.g., AWS Snowball) because transferring petabytes over the internet would take months.
4. Change Data Capture (CDC) and Sync: While the bulk load is happening, the legacy system is still receiving new data. CDC tools (like Debezium or GoldenGate) are used to capture every new transaction in the legacy system and replicate it to the new lakehouse, ensuring the two systems remain perfectly synchronized.
5. Cutover: The moment of truth. The BI dashboards and downstream applications are repointed from the legacy system to the new lakehouse (e.g., routing Tableau from Teradata to Dremio). Once the cutover is validated, the legacy system is decommissioned.
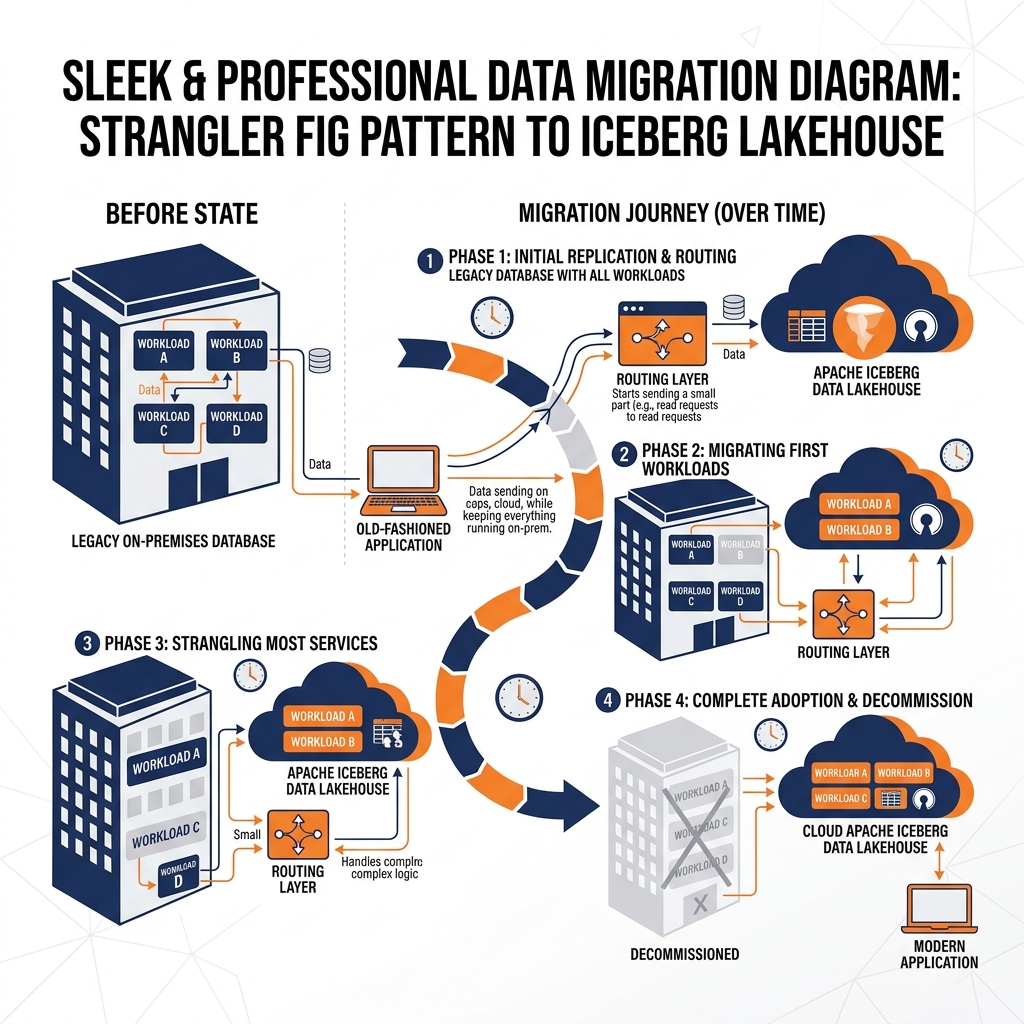
The Strangler Fig Pattern
For large enterprises, a “Big Bang” cutover (moving everything at once over a weekend) is incredibly risky. Instead, modern migrations often use the “Strangler Fig” architectural pattern.
In this pattern, the legacy system and the new lakehouse run in parallel. The migration team identifies a single business domain (e.g., Marketing Analytics) and migrates its data and pipelines to the lakehouse. They point the marketing dashboards to the lakehouse, while finance and sales continue using the legacy system.
Over months, domain by domain, workloads are migrated to the new architecture. The new lakehouse slowly “strangles” the legacy system until all workloads have been moved, at which point the legacy system is turned off. This iterative approach minimizes risk and allows the engineering team to learn and adjust their migration tooling on smaller, less critical workloads first.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.