Change Data Capture (CDC)
A comprehensive guide to Change Data Capture (CDC), the data integration technique that identifies and delivers row-level database changes in real time to downstream analytical systems.
The Problem of Stale Analytical Data
Enterprise organizations operate under a fundamental tension between their operational systems and their analytical systems. Operational databases, such as PostgreSQL, MySQL, and Oracle, are tuned for transactional workloads: they process thousands of individual row insertions, updates, and deletions per second to support real-time applications. Analytical systems, such as data warehouses and data lakehouses, are tuned for aggregate query workloads: scanning billions of rows to compute business metrics.
Historically, the bridge between these two worlds was the nightly batch ETL job. After business hours, an ETL pipeline would extract a full or incremental snapshot of each operational database, transform the data, and load it into the data warehouse. Analysts could then query the warehouse the following morning to review yesterday’s business performance. This batch cycle created an inherent analytical latency of twelve to twenty-four hours. Business decisions were made on data that was always at least half a day old.
For many traditional reporting use cases, this latency was acceptable. A weekly sales performance review does not require up-to-the-second accuracy. However, modern business operations increasingly demand analytical responsiveness that batch pipelines fundamentally cannot provide. A fraud detection system must identify a suspicious transaction pattern within seconds of the transaction occurring. A supply chain monitoring system must alert warehouse managers to inventory shortfalls the moment the operational database records a depletion event. A customer success platform must update health scores in near-real-time as customers interact with the product. These use cases require a fundamentally different approach to data integration.
Change Data Capture (CDC) provides that approach. Rather than periodically extracting bulk snapshots of database tables, CDC continuously monitors the operational database at the transaction log level and captures every individual row-level change (INSERT, UPDATE, DELETE) the instant it is committed. These change events are delivered to downstream systems in real time, enabling analytical platforms to maintain state that is continuously synchronized with the operational source of truth, often within seconds of the originating transaction.
How CDC Works: Transaction Log Mining
Most production CDC implementations in enterprise environments are built around a technique called transaction log mining. Understanding why this approach is preferred over alternatives requires understanding how relational databases guarantee data durability.
Every ACID-compliant relational database maintains a persistent transaction log, variously called the Write-Ahead Log (WAL) in PostgreSQL, the Binary Log (binlog) in MySQL, the Redo Log in Oracle, and the Transaction Log in SQL Server. This log serves as the database’s fundamental durability mechanism. Before any change is applied to the actual data pages on disk, the database writes a record of that change to the transaction log. If the database crashes mid-operation, it recovers by replaying the transaction log to restore the data to a consistent state.
The transaction log is, therefore, a complete, ordered, durable record of every change the database has ever committed. CDC systems exploit this property by reading the transaction log as an external reader, parsing the log entries for data change events, and publishing those events to downstream consumers.
This log-based approach has several critical advantages over alternative CDC techniques. Because it reads directly from the transaction log, it adds zero load to the operational database’s query processing capacity. The log is already being written for durability purposes; reading it is purely additive. This is in stark contrast to query-based CDC techniques (where a scheduled polling query runs SELECT * FROM table WHERE updated_at > last_run_time), which consume database I/O, CPU, and connections on every polling cycle.
Log-based CDC also captures DELETE events, which polling-based approaches cannot detect (deleted rows simply disappear from the query result set). It captures all changes, including those made through direct database connections that bypass the application layer, ensuring complete capture fidelity.
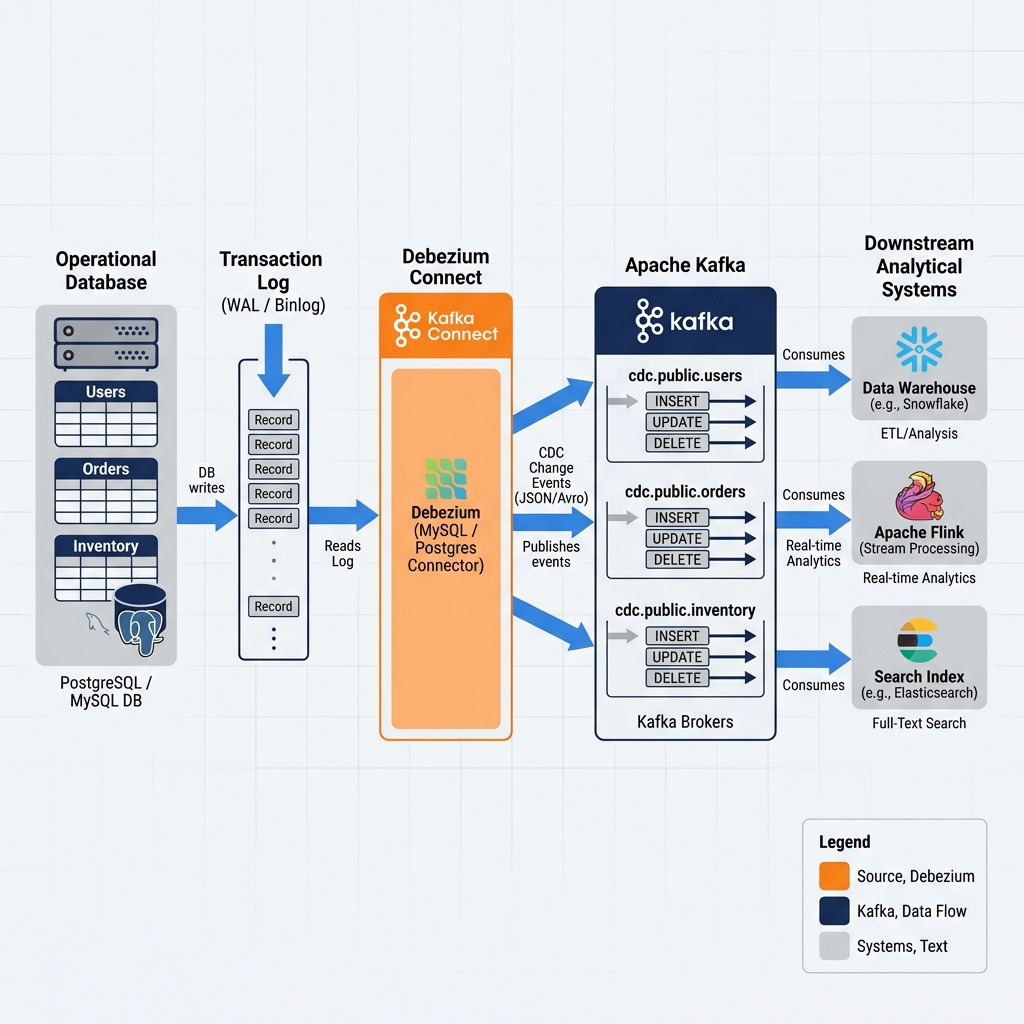
Tools like Debezium, an open-source CDC framework originally developed at Red Hat and now a top-level Apache Incubator project, implement log-based CDC for PostgreSQL, MySQL, Oracle, MongoDB, and other major databases. Debezium acts as a database replication client, registering with the source database as a replication slot (in PostgreSQL’s terminology) or a replica server (in MySQL’s terminology), and consuming the transaction log events as they are produced.
CDC Event Structure and Delivery
Each change event captured by a CDC system carries a rich, structured payload that downstream consumers use to reconstruct the operational state. Understanding the event structure is essential for building reliable CDC-powered analytical pipelines.
A typical Debezium CDC event published to Apache Kafka is a JSON message containing several key fields. The before field contains the complete row state before the change was applied (null for INSERT events). The after field contains the complete row state after the change was applied (null for DELETE events). The op field indicates the operation type: c for create (INSERT), u for update (UPDATE), d for delete (DELETE), and r for read (initial snapshot). The source metadata block contains the source database name, table name, transaction ID, and the precise log sequence number (LSN) that identifies the position of this event in the transaction log. The ts_ms field records the millisecond timestamp when the change was committed to the source database.
This rich event structure enables downstream systems to perform several critical analytical operations. By processing events in sequence by their LSN, a consumer can reconstruct the exact current state of every row in the operational table. By comparing the before and after payloads, a consumer can identify precisely which columns changed in an UPDATE event. By recording the source ts_ms timestamp, analytical pipelines can track exactly when each business event occurred in the operational system, enabling accurate temporal analysis independent of when the event was processed by the analytical pipeline.
The Initial Snapshot
When a CDC pipeline is first established for a table, the downstream consumer needs to synchronize with the current state of the table before it can begin processing incremental changes. CDC systems handle this through an initial snapshot phase. Debezium takes a consistent snapshot of the entire source table at a specific database transaction boundary, publishing each existing row as an r (read) event. Once the snapshot is complete, Debezium seamlessly transitions to streaming mode, capturing and publishing live change events from the transaction log. The downstream consumer processes the snapshot events to populate its initial state, then continues updating that state with the live change events, achieving complete synchronization.
CDC to the Lakehouse: Iceberg MERGE INTO
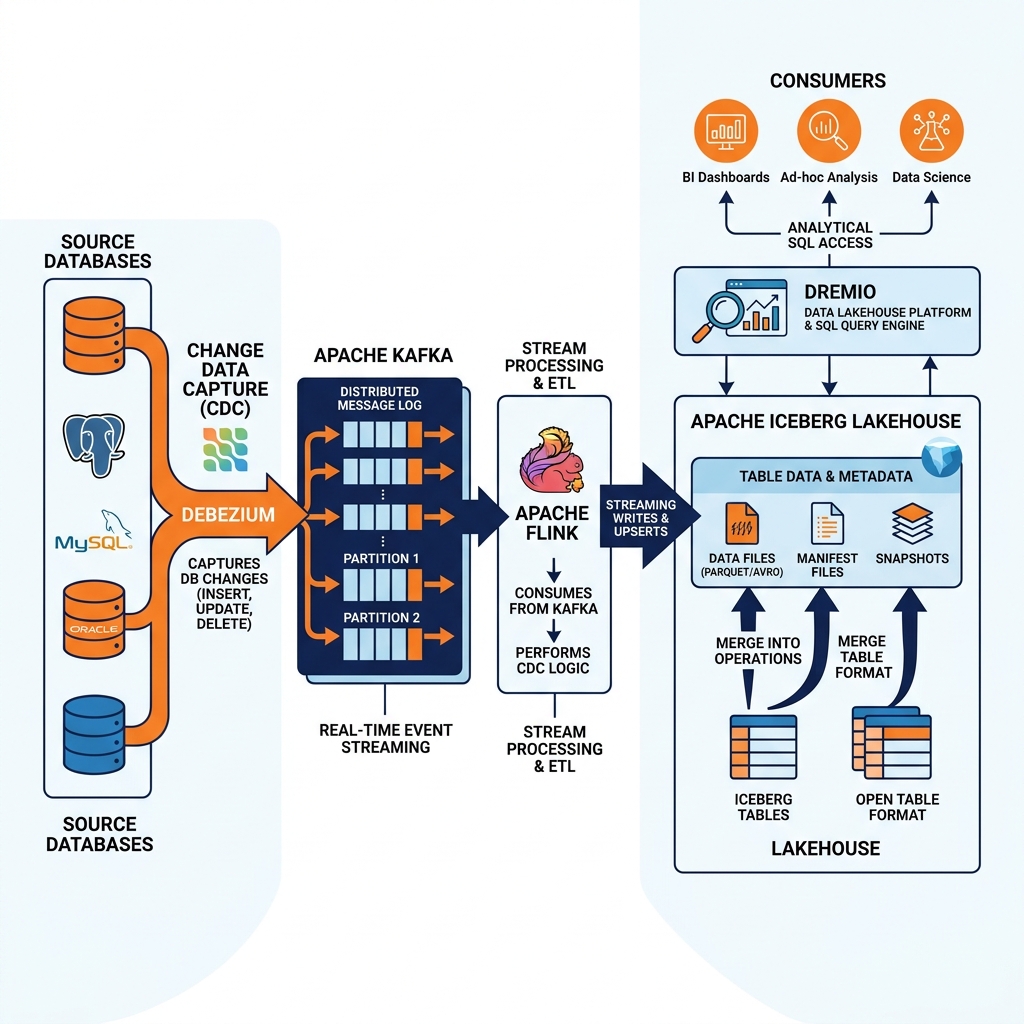
The most powerful application of CDC in modern data engineering is the continuous synchronization of operational relational databases with Apache Iceberg tables in the data lakehouse. CDC transforms the Iceberg lakehouse from a batch-updated snapshot repository into a continuously updated operational mirror.
The pattern works as follows: Debezium captures change events from the operational database and publishes them to Apache Kafka topics. A stream processing job, typically implemented in Apache Flink with the Flink CDC connector or the Apache Iceberg Flink sink, consumes the Kafka events and applies them to the target Iceberg table. For INSERT events, new rows are added to the Iceberg table. For UPDATE events, the Iceberg MERGE INTO statement atomically updates the existing row. For DELETE events, the row is removed from the table.
Apache Iceberg’s ACID guarantees make this continuous merge pattern safe and reliable. Because Iceberg implements Optimistic Concurrency Control, multiple streams can write to different partitions of the same Iceberg table simultaneously without corrupting each other’s changes. Because Iceberg uses snapshot-based versioning, analysts querying the table during an ongoing CDC merge cycle always see a consistent view of the data, never encountering partially applied batches or corrupted rows.
The latency of this end-to-end pipeline from operational change to Iceberg lakehouse availability typically ranges from a few seconds to under a minute, depending on the batch commit interval of the Flink job. This represents a dramatic reduction from the twelve to twenty-four hours of latency characteristic of nightly batch ETL pipelines.
Dremio and Near-Real-Time Analytics on CDC Data
Once CDC events are continuously materializing changes into Apache Iceberg tables, Dremio can serve as the high-performance analytical layer on top of these near-real-time Iceberg tables. Analysts query the Dremio Semantic Layer using standard SQL and receive results reflecting the operational state as of a few seconds or minutes ago, without any awareness of the CDC pipeline operating beneath them.
Dremio’s ability to read Iceberg tables directly from object storage, combined with its aggressive file pruning based on Iceberg metadata statistics, ensures that even as CDC pipelines continuously write small batches of change files to the Iceberg table, query performance remains high. Data Reflections can be configured on stable, slowly changing dimensions to deliver sub-second performance, while frequently changing fact tables are queried directly against the Iceberg files for maximum freshness.
This combination, Debezium for CDC capture, Apache Kafka for event streaming, Apache Flink for stream processing and Iceberg writes, and Dremio for governed analytical access, forms a complete near-real-time data platform capable of supporting both operational intelligence and deep analytical workloads on the same unified data lakehouse.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.