Data Warehouse
A deep dive into the data warehouse, the foundational architecture for business intelligence, its history, its strict schema-on-write enforcement, and its evolution into the modern data lakehouse.
The Origins and Purpose of the Data Warehouse
The data warehouse represents one of the most critical structural paradigms in the history of data engineering. To understand its fundamental architecture and enduring legacy, one must first examine the specific business problems it was engineered to solve. In the early days of enterprise computing, organizations relied heavily on transactional databases. These systems, known as Online Transaction Processing (OLTP) databases, are optimized for rapid, high-volume insertions, updates, and deletions. A classic example of an OLTP system is the database powering an e-commerce checkout flow or an airline reservation system. OLTP systems prioritize row-level locking, referential integrity, and immediate consistency.
However, as businesses grew more sophisticated, they required the ability to analyze historical trends, aggregate sales across multiple quarters, and forecast future revenue. Running massive analytical aggregations directly on a live OLTP database proved disastrous. A complex SQL query calculating the average revenue per customer across a ten-year dataset would monopolize the database’s CPU and disk I/O, causing the entire system to lock up. This inevitably led to customer-facing outages where users could no longer complete transactions because an analyst was running a quarterly report. The industry needed a way to physically separate analytical workloads from transactional workloads.
The solution was the data warehouse. A data warehouse is a centralized repository designed exclusively for Online Analytical Processing (OLAP). Rather than processing individual transactions as they happen, the data warehouse ingests historical data from multiple distinct operational systems (such as CRM platforms, ERP systems, and billing databases), integrates that data, and optimizes it for complex read-heavy queries. By physically decoupling the analytical environment from the operational environment, organizations ensured that their business intelligence dashboards could run massive aggregations without impacting the performance of their live applications.
The defining characteristic of the traditional data warehouse is its rigid enforcement of structure, known as schema-on-write. Before a single record can be loaded into the warehouse, the data engineering team must meticulously define the exact table schema, column data types, and primary key relationships. When data arrives from upstream sources, it must be validated and transformed to perfectly match this predefined blueprint. If a source system suddenly adds a new column or changes a data type from an integer to a string, the ingestion process fails immediately, preventing the “bad” data from corrupting the warehouse.
This strict schema-on-write paradigm is both the greatest strength and the most significant limitation of the data warehouse. Its strength lies in the absolute guarantee of data quality and consistency. Because the data has been rigorously cleansed, structured, and validated upon entry, business analysts can trust the output of their dashboards implicitly. The data warehouse serves as the single source of truth for the entire enterprise. Financial reporting, compliance auditing, and executive decision-making rely entirely on the absolute certainty provided by this structured environment.
Conversely, the limitation of schema-on-write is extreme rigidity. In a modern data ecosystem, data formats change constantly. Machine learning models require access to unstructured text, nested JSON payloads from mobile applications, and high-velocity streaming telemetry. The traditional data warehouse struggles to accommodate these novel data types. Adapting the warehouse schema to ingest a new data source often requires weeks of planning, database migrations, and pipeline rewrites. This inherent rigidity eventually led to the development of alternative architectures, but the core principles of the data warehouse (centralization, separation of workloads, and data governance) remain foundational to all subsequent data engineering advancements.
Architecture of a Traditional Data Warehouse
The physical and logical architecture of a traditional on-premises data warehouse is fundamentally different from both operational databases and modern cloud architectures. Understanding this architecture is crucial for recognizing the structural bottlenecks that eventually drove the industry toward cloud-native and lakehouse paradigms.
Massively Parallel Processing (MPP)
Traditional relational databases typically operate on a single server node. This Symmetric Multiprocessing (SMP) architecture is perfectly adequate for handling thousands of small OLTP transactions per second, but it cannot scale to process petabytes of analytical data. To overcome this limitation, enterprise data warehouses like Teradata and Netezza introduced Massively Parallel Processing (MPP) architectures.
An MPP data warehouse is a distributed system comprising a central coordinator node and multiple subordinate compute nodes. When an analyst submits a complex SQL aggregation query, the coordinator node intercepts the request, generates an execution plan, and divides the query into smaller, independent tasks. It then pushes these tasks down to the compute nodes. Each compute node processes its designated slice of the data simultaneously, operating entirely independently of the others. Once the compute nodes finish their local aggregations, they return their intermediate results to the coordinator, which assembles the final result set and returns it to the user. This “divide and conquer” approach allows MPP warehouses to scan billions of rows in seconds.
The Storage and Compute Coupling
The fatal flaw of the traditional MPP architecture is the tight coupling of storage and compute resources. In these systems, each compute node possesses its own dedicated, attached disk storage. This is known as a shared-nothing architecture. The data is physically partitioned and distributed across the hard drives of the individual compute nodes.
This tight coupling creates severe scaling inefficiencies. If an organization exhausts its storage capacity because they are retaining years of historical data, they cannot simply add more hard drives to the system. They are forced to purchase and provision entirely new MPP nodes, which include expensive CPU and RAM that they may not actually need for their analytical workloads. Conversely, if the organization experiences a surge in analytical query volume (for example, during end-of-quarter financial reporting), they cannot dynamically add more compute power without also rebalancing the entire physical storage layer across the new nodes. This inelasticity made traditional data warehouses incredibly expensive to scale and maintain.
Dimensional Data Modeling
Beyond the physical hardware, the logical architecture of the data warehouse is defined by its data modeling strategy. Unlike operational databases that use Third Normal Form (3NF) to eliminate data redundancy, data warehouses use dimensional modeling techniques specifically optimized for read performance. The most prevalent of these techniques is the Star Schema, popularized by Ralph Kimball.
In a Star Schema, the database is divided into two distinct types of tables: Fact tables and Dimension tables. A Fact table sits at the center of the schema and contains the quantitative, measurable events of the business, such as individual sales transactions, website clicks, or inventory movements. Fact tables are typically massive, containing billions of rows, but they are narrow, consisting primarily of foreign keys and numerical metrics (like revenue or quantity).
Surrounding the Fact table are the Dimension tables. Dimension tables contain the descriptive context that gives meaning to the facts. For example, a Customer dimension table might contain the customer’s name, demographic information, and location. A Date dimension table contains attributes like the day of the week, fiscal quarter, and holiday indicators.
When an analyst queries the warehouse, they typically join the central Fact table to multiple surrounding Dimension tables (creating a shape that resembles a star). This schema is highly denormalized, meaning some data redundancy is intentionally introduced into the dimension tables to reduce the total number of complex SQL joins required to execute a query. This intentional redundancy drastically accelerates query performance, allowing business intelligence tools to render dashboards with minimal latency.
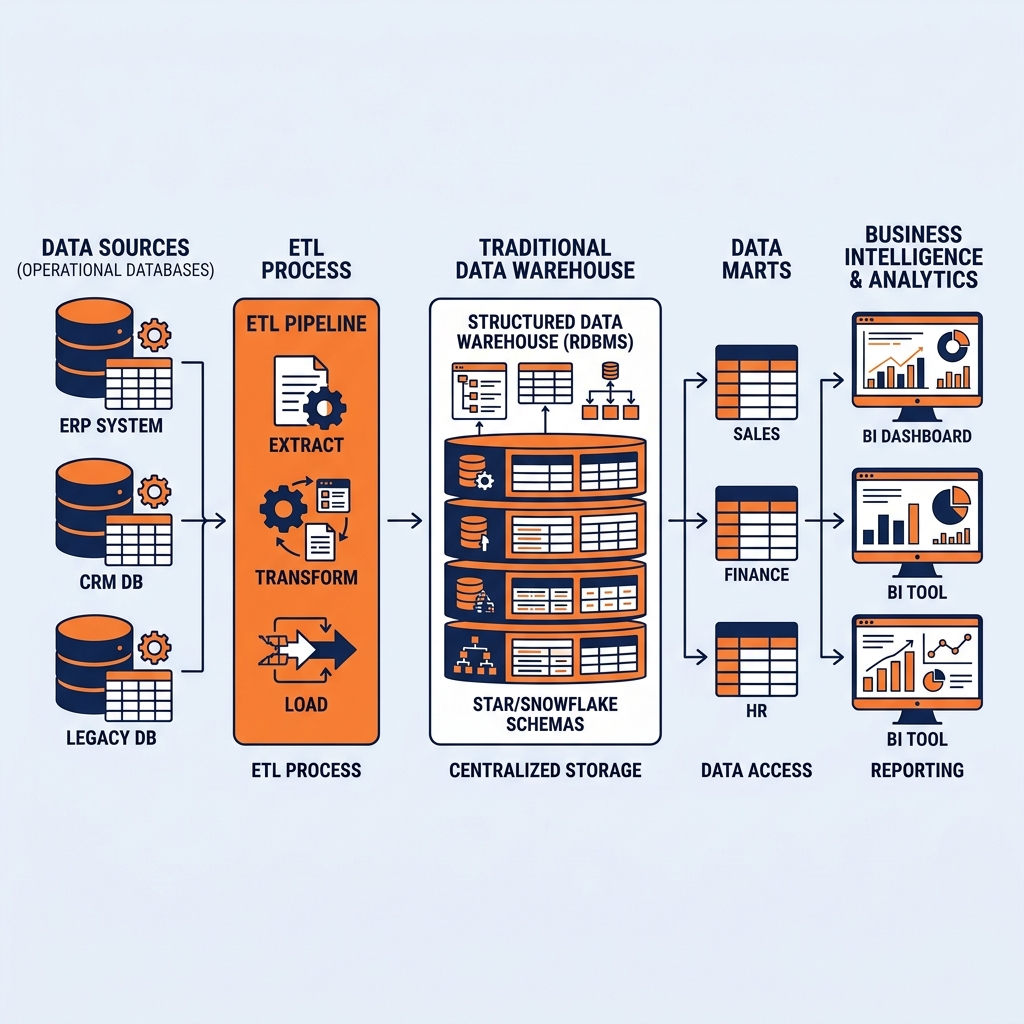
The ETL Pipeline (Extract, Transform, Load)
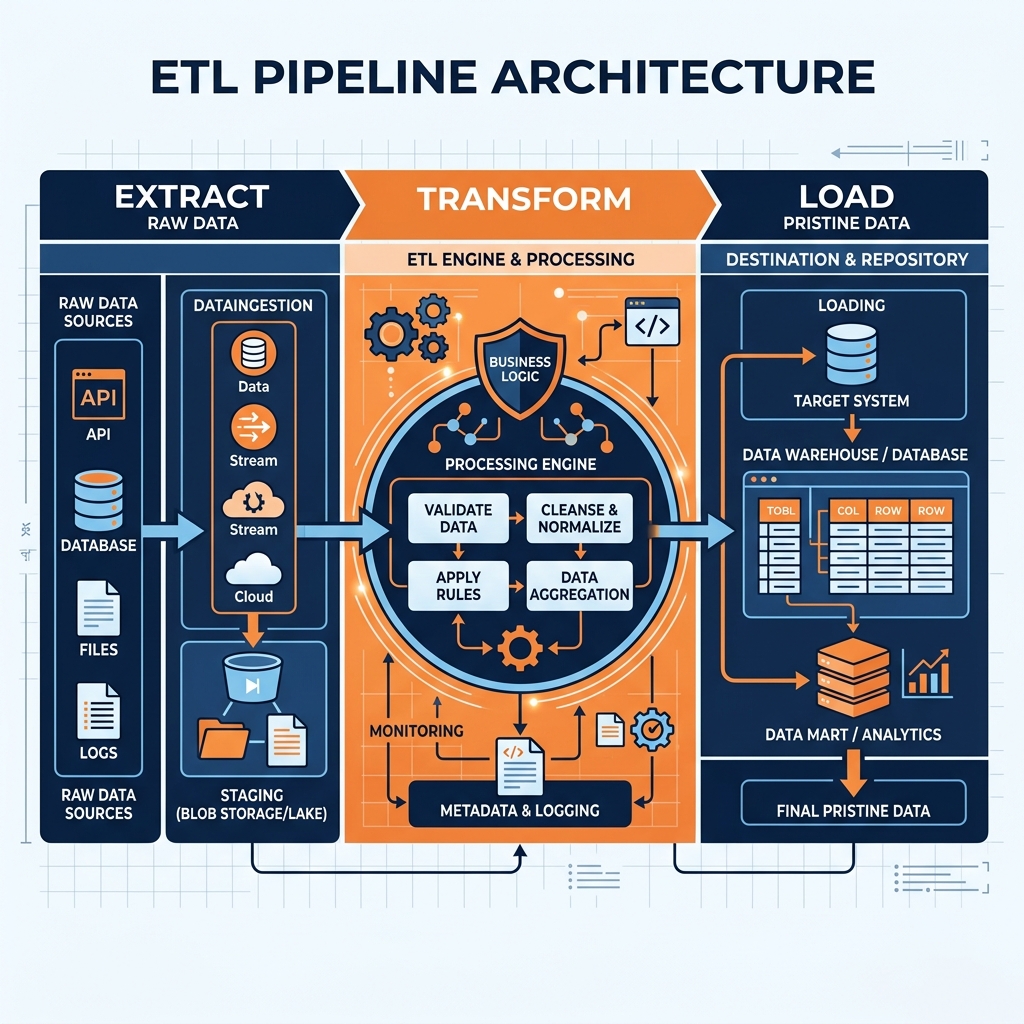
Because the data warehouse enforces strict schema-on-write principles, raw data cannot simply be copied from a source system into the warehouse. It must undergo a rigorous, multi-stage engineering process before it is deemed acceptable for analytical querying. This process is known as Extract, Transform, and Load (ETL). The ETL pipeline is the critical logistical backbone of the traditional data warehouse architecture, but it is also its most fragile and resource-intensive component.
Extract
The first phase of the pipeline is Extraction. Data engineers must build connectors to pull data from a myriad of disparate operational systems. This might include extracting relational data from a PostgreSQL database, pulling JSON payloads from a REST API, scraping flat CSV files from an external FTP server, and retrieving logs from application servers.
Extraction is inherently complex because source systems are entirely unaware of the downstream data warehouse. They do not maintain a convenient list of which records have changed since the last extraction. Data engineers must implement Change Data Capture (CDC) mechanisms to identify and extract only the new or modified records (incremental loads) rather than executing a massive full-table extraction every night. Extracting data also places a computational burden on the operational source systems, so engineers must carefully schedule these extraction windows during off-peak hours to avoid impacting live application performance.
Transform
Once the raw data is extracted, it enters the Transformation phase. In a traditional ETL architecture, transformation occurs on a dedicated, standalone processing server located outside of the data warehouse. This is the most computationally expensive and complex stage of the pipeline.
During transformation, the raw data is cleansed, standardized, and modeled to fit the strict dimensional schema of the warehouse. This involves a wide array of operations. Data engineers must resolve inconsistencies, such as converting all date strings into a standard ISO format. They must handle missing values by either imputing default values or dropping corrupted records. They must deduplicate records that were accidentally generated multiple times in the source system.
Crucially, the transformation phase is where complex business logic is applied. For example, if the business defines “Net Revenue” as gross sales minus returns and local taxes, the ETL pipeline must calculate this specific metric during the transformation phase and write the final calculated value into the warehouse. By pre-calculating these metrics, the warehouse ensures that every analyst querying the system sees the exact same numbers, eliminating the risk of conflicting reports.
Load
The final phase is Loading the transformed, pristine data into the target tables of the data warehouse. Depending on the business requirements, this can be executed as a massive batch load overnight, or through continuous micro-batching throughout the day.
Loading is not as simple as executing a basic SQL INSERT statement. The ETL pipeline must manage the complexities of Slowly Changing Dimensions (SCD). If a customer moves to a new city, the pipeline must determine whether to overwrite their old address (SCD Type 1) or insert a new record with a version number to preserve the historical context of their previous purchases (SCD Type 2). The pipeline must also rebuild database indexes and update table statistics so that the MPP query optimizer can generate efficient execution plans for the new data.
The Fragility of Traditional ETL
While the ETL process guarantees pristine data quality, it creates an enormous operational bottleneck. Traditional ETL pipelines are notoriously brittle. If an upstream software developer renames a column in the operational database, the downstream ETL pipeline will fail, effectively halting the flow of data into the warehouse until a data engineer patches the code. Because the transformation logic is hard-coded into proprietary ETL tools running on separate servers, it is incredibly difficult to audit, version-control, or migrate. The sheer complexity of maintaining these pipelines forces data engineering teams to spend the vast majority of their time fixing broken ETL jobs rather than architecting new analytical capabilities.
Cloud Data Warehouses vs. On-Premises
As data volumes exploded in the 2010s, the limitations of traditional, on-premises MPP data warehouses became insurmountable. Purchasing massive hardware appliances, managing physical data center racks, and executing complex capacity planning cycles could no longer keep pace with the agility required by modern businesses. This crisis catalyzed the migration to the Cloud Data Warehouse, representing a monumental architectural shift that resolved the most glaring inefficiencies of on-premises deployments.
The Separation of Compute and Storage
The defining architectural innovation of the cloud data warehouse is the complete physical separation of compute and storage. First pioneered by platforms like Snowflake and Google BigQuery, and later adopted by Amazon Redshift, this architecture dismantles the rigid, shared-nothing hardware constraints of traditional MPP systems.
In a cloud data warehouse, all persistent data is stored in a centralized, highly durable cloud object storage layer (such as Amazon S3). Object storage is practically infinite and incredibly cheap. The compute layer, conversely, consists of clusters of virtual machines (or serverless execution engines) that are completely stateless. When a user submits a query, the cloud data warehouse spins up a virtual compute cluster on demand, pulls the necessary data from the central object storage layer over a high-speed network, performs the analytical aggregation, and then immediately spins the compute cluster back down.
This separation provides unprecedented elasticity. If an organization needs to retain ten years of historical telemetry data, they simply pay the minimal cost of keeping those files in object storage without provisioning a single CPU core. If the finance team requires massive computational power for end-of-year reporting, the organization can instantly provision a massive compute cluster for precisely two hours, and then destroy it when the report is finished. Compute and storage can be scaled entirely independently of one another, drastically reducing total cost of ownership.
The Shift to ELT (Extract, Load, Transform)
The immense computational power of the cloud data warehouse fundamentally altered the traditional data engineering pipeline. Because cloud warehouses can execute massive SQL aggregations in seconds, it is no longer necessary to perform transformations on a separate, dedicated processing server. The industry shifted from ETL (Extract, Transform, Load) to ELT (Extract, Load, Transform).
In the ELT paradigm, raw data is extracted from the source systems and loaded directly into the cloud data warehouse with minimal modification. The warehouse acts as both the storage repository and the transformation engine. Data engineers leverage the native distributed processing power of the warehouse to execute complex SQL transformations on the raw tables, molding them into the final dimensional models required for business intelligence. This approach simplifies the architectural footprint, eliminates the need to maintain legacy ETL servers, and allows transformation logic to be managed entirely in standard SQL.
The Persistence of Vendor Lock-in
Despite these massive advancements in elasticity and scalability, cloud data warehouses inherited a critical flaw from their on-premises predecessors: vendor lock-in. While the underlying storage mechanism might be standard cloud object storage, the data itself is ingested, heavily encrypted, and stored in highly proprietary, closed file formats.
Once an organization loads petabytes of data into a cloud warehouse, that data effectively becomes hostage to the vendor. If a data science team wishes to train a machine learning model using an open-source framework like Apache Spark, they cannot simply point Spark at the warehouse storage. They must execute a complex, expensive export operation to extract the data out of the warehouse and into an accessible format. Furthermore, cloud data warehouse vendors often charge significant premiums for compute usage. Because the data is locked inside their proprietary ecosystem, the organization has no choice but to use the vendor’s expensive compute engine for every single query, regardless of whether a cheaper or more specialized engine might be better suited for the task. This closed-ecosystem model ultimately paved the way for the open architecture of the data lakehouse.
Data Warehouse vs. Data Lake vs. Data Lakehouse
To fully grasp the current state of data engineering, one must understand how the data warehouse contrasts with the two architectures that followed it: the data lake and the data lakehouse. Each paradigm represents a distinct approach to the fundamental trade-off between structure and flexibility.
The Data Lake Contrast
While the data warehouse mandates absolute structure via schema-on-write, the data lake swings to the opposite extreme. A data lake is a centralized repository that stores all forms of data, structured, semi-structured (JSON, XML), and entirely unstructured (images, audio logs), in its native, raw format on cheap object storage. It operates on a schema-on-read philosophy. Data engineers dump raw files into the lake without any predefined modeling or validation. The responsibility of parsing, understanding, and structuring the data is pushed downstream to the analyst or data scientist at the exact moment they attempt to query it.
The data lake solves the rigidity problem of the warehouse. It is the perfect environment for machine learning and exploratory data science, as models often require access to unaltered, raw telemetry. However, the data lake fails completely as a reliable foundation for business intelligence. Because there is no strict validation upon entry, data lakes frequently suffer from data corruption, missing fields, and conflicting file formats. Querying a raw data lake directly is slow, chaotic, and completely unsuitable for generating the pristine financial reports that executives require. This massive capability gap forced organizations to adopt complex two-tier architectures, maintaining both a data lake for machine learning and a synchronized data warehouse for BI reporting.
The Data Lakehouse Unification
The data lakehouse emerged to dismantle this fragile two-tier architecture. It provides the cheap, infinitely scalable object storage of the data lake, but layers the reliability, ACID transaction guarantees, and governance of the data warehouse directly on top of it. This feat is accomplished through the use of open table formats like Apache Iceberg.
In a lakehouse, data is stored in open, columnar file formats (like Apache Parquet) directly on cloud object storage. The table format acts as the metadata layer, providing the transactional consistency and schema enforcement that traditional data lakes lack. Compute engines can read these open tables with the same reliability and speed as if they were querying a proprietary data warehouse.
The Dremio Perspective: Zero-ETL and Reflections
From the perspective of a modern lakehouse platform like Dremio, the traditional data warehouse represents an unnecessary duplication of data and effort. Moving data from a lake into a warehouse requires constant ETL maintenance and results in analysts querying stale data. Dremio argues that warehouse workloads should be migrated directly to the lakehouse.
Dremio executes this vision through its Zero-ETL architecture and Data Reflections. Rather than physically moving data into a proprietary warehouse, Dremio queries the data directly where it resides in the lakehouse. To match the sub-second performance of a highly optimized warehouse cube, Dremio utilizes Data Reflections. These are intelligent, invisible materializations of the data pre-computed and stored as Parquet files. When an analyst submits a complex BI query, the Dremio optimizer automatically intercepts the request and routes it to the pre-computed Reflection rather than scanning the raw tables. This provides the blazing-fast dashboard performance expected from a traditional data warehouse, but entirely within an open, decentralized lakehouse environment.
Modernizing Warehouse Workloads (The Future)
The era of the monolithic, proprietary data warehouse is concluding. As data volumes continue to grow exponentially and the demands of Artificial Intelligence require direct access to raw information, organizations are actively modernizing their legacy warehouse workloads. This modernization does not mean abandoning the principles of data governance and reliability; rather, it means applying those principles to open, decoupled architectures.
Migrating to Open Formats
The most critical step in modernizing a data warehouse is migrating persistent data out of proprietary, closed formats and into open standards. Apache Iceberg has become the undisputed standard for this transition. By exporting warehouse tables into Iceberg format on cloud object storage, organizations instantly break vendor lock-in.
Once the data is stored as Iceberg tables, the organization reclaims total control over their compute layer. They are no longer forced to pay premium compute rates to their legacy warehouse vendor. They can utilize Dremio for interactive BI dashboards, Apache Spark for heavy batch processing, and specialized AI frameworks for machine learning, all pointing to the exact same, single copy of the Iceberg table. This open architecture eliminates the massive egress fees and complex synchronization pipelines that plagued previous generations of data engineering.
The Rise of the Semantic Layer
In traditional architectures, business logic, metric definitions, and access controls were heavily embedded within the proprietary presentation layer of the data warehouse or hard-coded into specific BI tools. This created massive fragmentation. If an organization switched from Tableau to Power BI, they often had to rewrite years of custom business logic.
The modern approach extracts this logic out of the warehouse entirely and centralizes it within a universal Semantic Layer. Platforms like Dremio provide a logical abstraction over the physical Iceberg tables. Data engineers define metrics, join paths, and security policies once within the semantic layer. All downstream consumption tools, whether they are BI dashboards, Python notebooks, or autonomous AI agents, connect to this semantic layer rather than the physical tables. This guarantees absolute consistency across the enterprise. The semantic layer effectively absorbs the governance responsibilities of the legacy data warehouse, allowing the underlying physical data to remain decentralized and open.
Conclusion
The traditional data warehouse was a revolutionary concept that successfully decoupled analytical processing from operational systems, providing the foundation for modern business intelligence. Its rigorous enforcement of schema-on-write guaranteed data quality but ultimately sacrificed the flexibility required for the AI era. As the industry transitions to the data lakehouse, the monolithic warehouse is being disassembled. Its storage is migrating to open Iceberg tables, its compute is being replaced by distributed Arrow-native engines, and its governance is being centralized in universal semantic layers. The future of analytics retains the reliability of the data warehouse, but completely eliminates the lock-in, enabling organizations to democratize their data for the next generation of intelligent workloads.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.