Incremental Processing
A guide to incremental processing patterns in data engineering, the techniques for processing only new or changed data rather than reprocessing entire datasets on every pipeline run.
The Full-Scan Problem
A pipeline that reprocesses an entire billion-row table to identify and update the 50,000 rows that changed since the last run is extraordinarily wasteful. Yet this full-scan-and-rebuild pattern is common in data engineering organizations that lack the infrastructure for incremental processing. The pipeline reads 1TB of data, computes transformations, and writes a new version of the output table, 95% of which is identical to the previous version.
Incremental processing is the set of techniques that identify and process only the data that has changed since the last successful pipeline run, producing the correct output by merging the incremental changes into the existing output. When implemented correctly, incremental processing reduces compute costs, pipeline latency, and infrastructure load by orders of magnitude compared to full reprocessing.
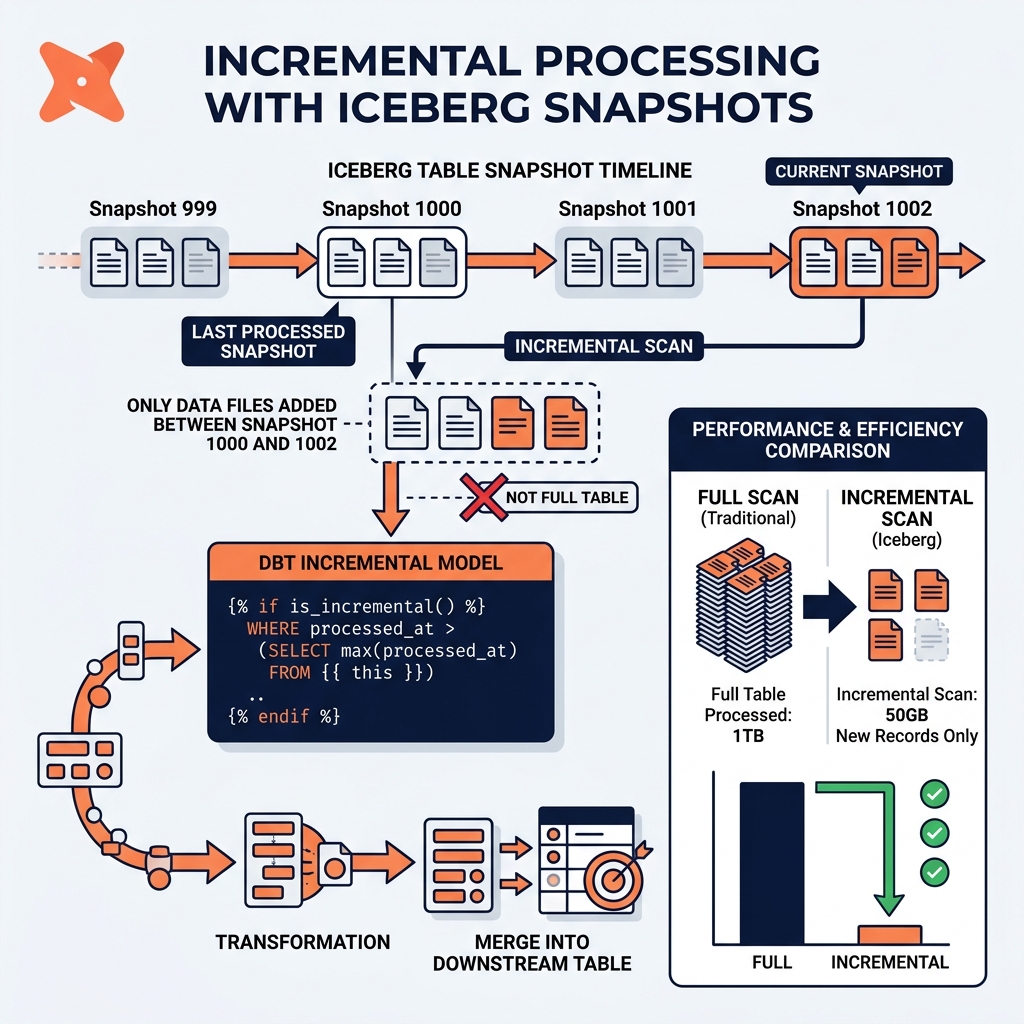
Incremental processing requires two core capabilities: the ability to identify which records have changed since the last run, and the ability to efficiently merge those changes into the output table. Apache Iceberg’s snapshot timeline provides both capabilities for Iceberg-based pipelines.
Iceberg Incremental Reads
Apache Iceberg’s snapshot timeline records every change to the table as a new snapshot with a precise timestamp. The Iceberg incremental_scan API (available in Spark and through PyIceberg) reads only the data file changes between two snapshots: the files added and the files removed in the snapshot range. A pipeline that last ran at snapshot ID 1000 can efficiently read only the new and changed data files added between snapshot 1000 and the current snapshot, without scanning the entire table.
This snapshot-based incremental read is the foundation for incremental pipelines in Iceberg-based lakehouses. A Spark job that processes upstream table changes runs table.newIncrementalScan(startSnapshotId=1000, endSnapshotId=current_snapshot_id) to get only the new records, processes them, and merges the results into the downstream Iceberg table using MERGE INTO.
For Change Data Capture pipelines, the incremental_scan returns only the records that were inserted, updated, or deleted since the last run, allowing downstream Silver and Gold layer tables to be updated without full-table reprocessing.
dbt Incremental Models
dbt’s incremental materialization implements incremental processing for SQL transformation pipelines. An incremental model is a dbt SQL model that, on its first run, builds the entire output table from scratch. On subsequent runs, dbt queries only for new or changed records (using a configurable is_incremental() condition, typically filtering by a timestamp column), transforms them, and merges them into the existing output table using the target platform’s MERGE or INSERT-OVERWRITE semantics.
For Iceberg tables in dbt-spark or dbt-trino, the incremental materialization uses Iceberg’s MERGE INTO to perform UPSERT semantics: new records are inserted, changed records (matching on a configurable unique key) are updated. This produces a correctly maintained output table that always reflects the latest state of the upstream data without full-table reprocessing on each run.
The incremental processing pattern’s correctness depends critically on idempotency: if the pipeline fails partway through and is retried, it must produce the same output as a successful run without double-processing records. Iceberg’s ACID semantics ensure that partial writes are not visible to readers, and dbt’s unique key-based MERGE ensures that re-processing the same records produces the same result.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.