Idempotency
A guide to idempotency in data engineering, the critical property of a data pipeline ensuring that executing the same code multiple times yields the exact same result, preventing duplicate data during retries.
Safe to Retry
In distributed systems, failures are inevitable. Network connections drop, database locks timeout, and APIs return 503 errors. Because data pipelines interact with numerous external systems, a pipeline will eventually fail midway through its execution.
When a pipeline fails, the standard operational response is to retry it. However, retrying a pipeline can cause catastrophic data corruption if the pipeline is not designed carefully.
Imagine a script that calculates daily sales and INSERTs the total ($10,000) into a reporting table. If the script successfully inserts the data but crashes immediately afterward (before notifying the orchestrator of success), the orchestrator assumes the task failed and retries it. The script runs again, calculating $10,000 and inserting it again. The reporting table now shows $20,000 for the day.
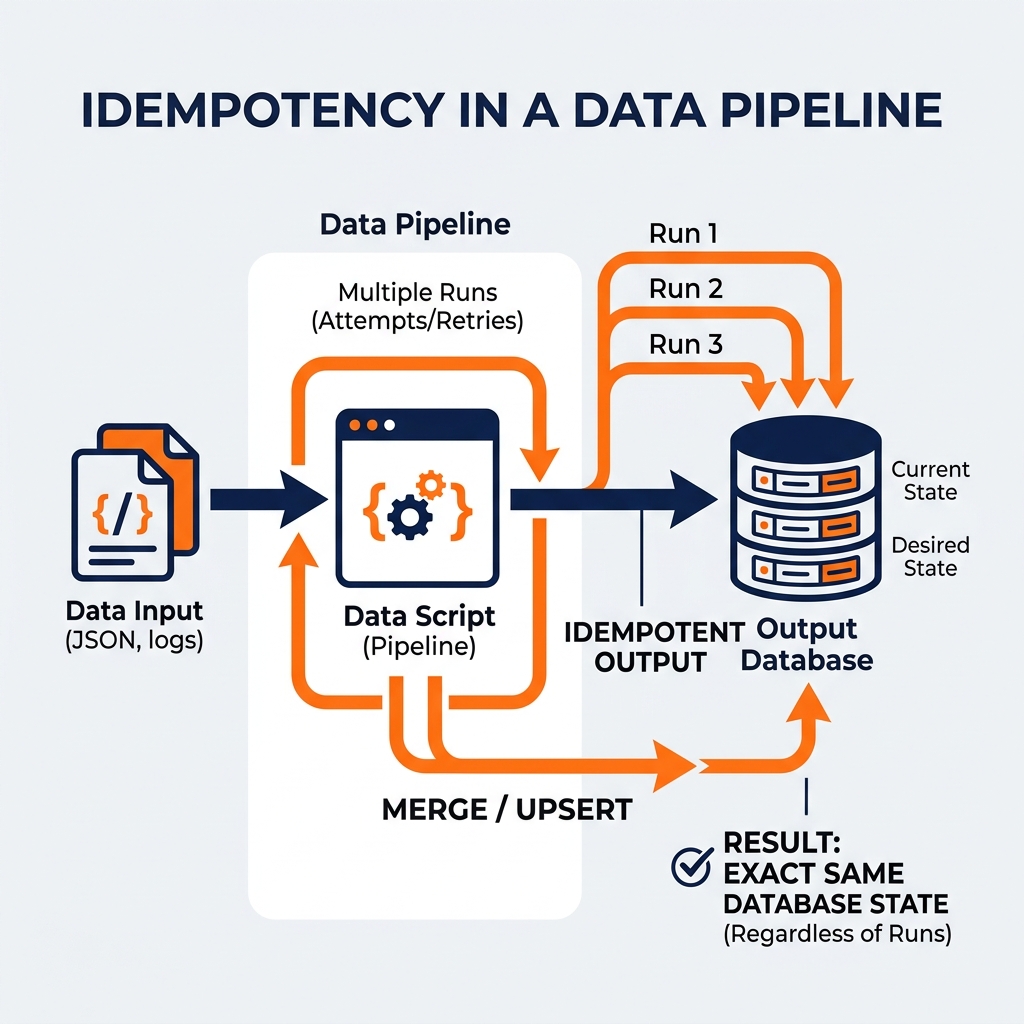
Idempotency is the property of an operation that guarantees that no matter how many times you execute it, the final result remains the same as if you had executed it only once. An idempotent pipeline is “safe to retry.”
Achieving Idempotency
Making a pipeline idempotent requires moving away from naive INSERT statements and embracing more robust architectural patterns.
The MERGE (Upsert) Pattern: Instead of blindly inserting rows, the pipeline uses a MERGE statement based on a unique primary key. If a record with order_id = 123 already exists, it UPDATEs it; if it doesn’t exist, it INSERTs it. If the pipeline is run ten times, the record is simply updated with the same values ten times, leaving the final table state identical to a single run.
The “Delete Then Insert” Pattern: Common in batch processing. Before writing the data for transaction_date = '2023-10-01', the pipeline explicitly issues a DELETE FROM table WHERE transaction_date = '2023-10-01'. If the pipeline is retried, the partial or duplicate data from the previous failed run is wiped out before the new data is inserted.
Full Overwrite: The simplest form of idempotency, often used in the Silver and Gold layers by tools like dbt (materialized='table'). The entire table is dropped and recreated from scratch on every run. While highly idempotent, it is computationally expensive for massive datasets.
Idempotency and Iceberg
Apache Iceberg natively supports highly performant idempotent operations. Iceberg’s MERGE INTO command handles row-level upserts efficiently, even across petabytes of data, rewriting only the necessary Parquet files.
More importantly, Iceberg’s Write-Audit-Publish (WAP) pattern provides ultimate idempotency. If a pipeline runs, it writes data to a hidden branch. If it fails midway, that branch is simply discarded. The main table is never touched until the pipeline successfully completes and the branch is merged. If the pipeline is retried, it simply starts over on a fresh hidden branch, guaranteeing that partial, duplicate data is never exposed to downstream consumers.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.