Medallion Architecture
A definitive guide to the Medallion Architecture, a layered data design pattern used to logically organize data in a lakehouse, progressing from raw ingestion to business-ready aggregates.
The Chaos of Unstructured Pipelines
To appreciate the elegance and necessity of the Medallion Architecture, one must first understand the state of data engineering prior to its widespread adoption. During the early era of the Hadoop data lake, organizations adopted a “store everything now, figure it out later” mentality. Data was ingested from hundreds of source systems, ranging from relational transaction databases to semi-structured JSON application logs, and dumped unceremoniously into massive, flat object storage buckets.
This approach solved the immediate problem of scalable, cheap storage, but it created an operational nightmare for data consumers. Data scientists attempting to train models and BI analysts attempting to build dashboards were forced to wade through petabytes of raw, undocumented, and often corrupted files. When an analyst needed to calculate quarterly revenue, they had to write fragile scripts to parse raw CSV files, manually filter out corrupted records, deduplicate overlapping events, and handle missing schemas on the fly.
This lack of structural organization led to the proliferation of tangled, interdependent ETL (Extract, Transform, Load) pipelines. A single raw file might be parsed and transformed by five different downstream jobs simultaneously. If the upstream application development team slightly altered the structure of the incoming JSON log, all five of those downstream ETL pipelines would crash simultaneously. Because there was no logical separation between the raw landing zone and the curated presentation layer, backfilling data or recovering from a pipeline failure was nearly impossible. If a transformation logic error was discovered, engineers often had to completely purge the destination tables and attempt to re-process weeks of raw data from scratch, assuming the raw data hadn’t been accidentally overwritten or deleted.
The industry desperately needed a standardized, logical design pattern that could impose order on the chaotic data lake. Organizations required a pipeline architecture that guaranteed reproducibility, isolated downstream consumers from upstream data corruption, and provided clear, distinct stages of data quality. This requirement catalyzed the development of the Medallion Architecture, a paradigm that transformed the stagnant data swamp into a tiered, highly functional data factory.
What is the Medallion Architecture?
The Medallion Architecture is a data design pattern used to logically organize data in a lakehouse. Its core principle is to incrementally and progressively improve the structure and quality of data as it flows through a series of distinct layers. Rather than attempting to transform raw telemetry into a perfect business dashboard in a single, monolithic ETL step, the Medallion approach breaks the transformation process into three distinct, manageable phases.
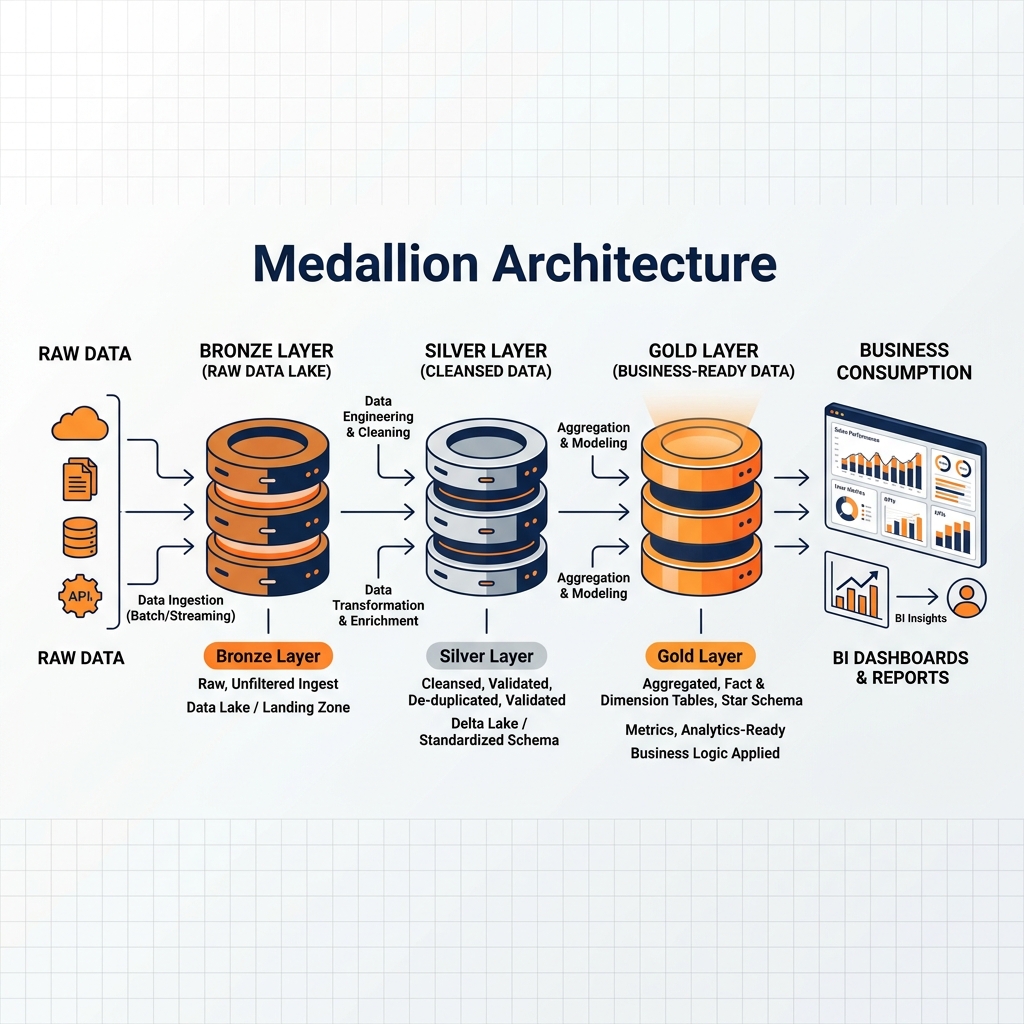
These phases are universally denoted by the colors of Olympic medals: Bronze, Silver, and Gold. Each layer serves a highly specific architectural purpose and caters to a different persona within the data organization.
The Bronze layer acts as the landing zone, storing data in its exact, unaltered original state. It prioritizes raw throughput and historical preservation. The Silver layer represents the cleansed and conformed layer. Here, the data is filtered, deduplicated, and normalized into a consistent enterprise schema, providing a reliable foundation for data science and advanced analytics. Finally, the Gold layer is the business presentation layer. In this layer, the cleansed data is heavily aggregated and modeled (often into dimensional star schemas) specifically to power high-performance Business Intelligence dashboards and executive reporting.
This layered approach provides immense operational resilience. By strictly separating the raw data from the cleansed data, and the cleansed data from the business aggregates, engineering teams isolate failures. If a complex aggregation in the Gold layer fails due to a logic error, the underlying cleansed data in the Silver layer remains perfectly intact. The engineers simply deploy a fix to the Gold transformation script and rerun it, without needing to re-ingest or re-cleanse the data. This modularity makes debugging, backfilling, and scaling data pipelines significantly more efficient than legacy monolithic approaches.
The Bronze Layer: Raw and Immutable
The Bronze layer is the absolute foundation of the Medallion Architecture. Its primary directive is to capture and persist data from external source systems as quickly and accurately as possible. The defining characteristic of a proper Bronze layer is immutability; data written to the Bronze layer should never be updated, overwritten, or modified in place.
The Append-Only Landing Zone
When streaming data (such as website clickstreams via Apache Kafka) or batch data (such as nightly database dumps) arrives at the data platform, it is immediately ingested into the Bronze tables. To ensure maximum ingestion speed and fidelity, the data is stored in its native format, which is often unstructured JSON, CSV, or raw Parquet files.
Data engineers explicitly do not perform schema validation, type casting, or data cleansing during the Bronze ingestion phase. If a source system suddenly starts sending a timestamp field as a string instead of a datetime object, the Bronze layer accepts it anyway. The goal is to ensure that no data is ever dropped or rejected at the front door. The Bronze layer serves as the ultimate historical system of record. If an organization ever needs to rebuild its entire analytical environment from scratch, or if a downstream transformation bug is discovered months later, the unadulterated ground truth is always safely preserved in the Bronze layer.
Metadata and Provenance
While the payload of the data remains untouched, data engineers typically enrich Bronze records with critical operational metadata. Common additions include an ingestion_timestamp (indicating exactly when the record arrived in the lakehouse), a source_system_id (identifying which API or database generated the record), and a batch_id (linking the record to a specific pipeline execution).
This metadata is invaluable for auditing, lineage tracking, and incremental processing. When the pipeline moves to the next stage, the compute engine can query the Bronze table using the ingestion_timestamp to select only the records that have arrived since the last successful pipeline run, ensuring that transformations are processed efficiently as incremental micro-batches rather than expensive full-table scans.
The Silver Layer: Cleansed and Conformed
If the Bronze layer is the chaotic landing zone, the Silver layer is the organized warehouse. The transformation from Bronze to Silver is where the majority of heavy data engineering takes place. The objective of the Silver layer is to produce an “enterprise view” of all core entities (such as Customers, Products, and Transactions) that is clean, conformed, and trustworthy.
Cleansing and Deduplication
The first step in the Silver transformation is rigorous data cleansing. Data engineers write pipelines (often using Apache Spark, dbt, or Dremio) to read the raw Bronze records and apply strict schema enforcement. Strings are correctly cast to integers, invalid date formats are standardized into ISO-8601 timestamps, and completely malformed records are quarantined into separate “dead-letter” tables for manual review.
Furthermore, the Silver layer is responsible for deduplication. In distributed streaming systems, network retries frequently cause the exact same event to be ingested into the Bronze layer multiple times (at-least-once delivery). The Silver pipeline identifies these duplicates using unique primary keys and filters them out. If the source system is a relational database emitting Change Data Capture (CDC) events, the Silver layer is where the sequence of INSERT, UPDATE, and DELETE events are merged together to produce a single, accurate representation of the current state of the database row.
The Domain for Data Science
Once the data is cleansed, deduplicated, and organized into standardized tables, it becomes the primary playground for data scientists and machine learning engineers. Data scientists rarely want to interact with the raw, chaotic JSON of the Bronze layer, but they also cannot use the highly aggregated metrics of the Gold layer (because aggregation destroys the granular fidelity required for training predictive models).
The Silver layer provides the perfect balance: the data is structurally sound and reliable, yet it retains all of its atomic, row-level detail. A machine learning model tasked with predicting customer churn can safely consume millions of individual transaction records from the Silver layer, confident that the data types are consistent and the duplicates have been resolved.
The final tier of the Medallion Architecture is the Gold layer. While the Silver layer is optimized for data scientists and machine learning, the Gold layer is obsessively optimized for business analysts, executive reporting, and BI dashboards.
Dimensional Modeling and Aggregation
Data in the Silver layer, while clean, is often highly normalized. An analyst attempting to calculate revenue by region might still have to join a Transactions table, a Customers table, and a Geography table. For a BI tool rendering a dashboard in real-time, executing these complex joins across billions of rows will result in unacceptable latency.
The Gold layer solves this by applying dimensional modeling techniques, most notably the Star Schema. Data engineers transform the normalized Silver tables into denormalized Fact tables (containing quantitative metrics like sales amounts) and Dimension tables (containing descriptive attributes like time, product category, and customer demographic).
Furthermore, the Gold layer is where heavy business aggregations occur. Instead of forcing the BI tool to sum up a million individual transactions, the data engineering pipeline pre-calculates the daily, weekly, and monthly revenue totals and stores them as physical aggregate tables in the Gold layer. When the CEO opens their Tableau dashboard, the query hits the Gold aggregate table, returning the answer in milliseconds rather than minutes.
The Integration with the Semantic Layer
In modern lakehouse architectures, the physical Gold layer is tightly coupled with a logical Semantic Layer. While the Gold tables contain the physical aggregations, the Semantic Layer (such as Dremio) sits on top to provide the final business-friendly abstraction. The Semantic Layer renames the physical Gold columns into natural language (e.g., tot_rev_usd becomes Total Revenue (USD)) and enforces Row-Based Access Control (RBAC) to ensure that regional managers can only query Gold records associated with their specific territory. The combination of physically optimized Gold tables and a governed Semantic Layer represents the pinnacle of enterprise data delivery.
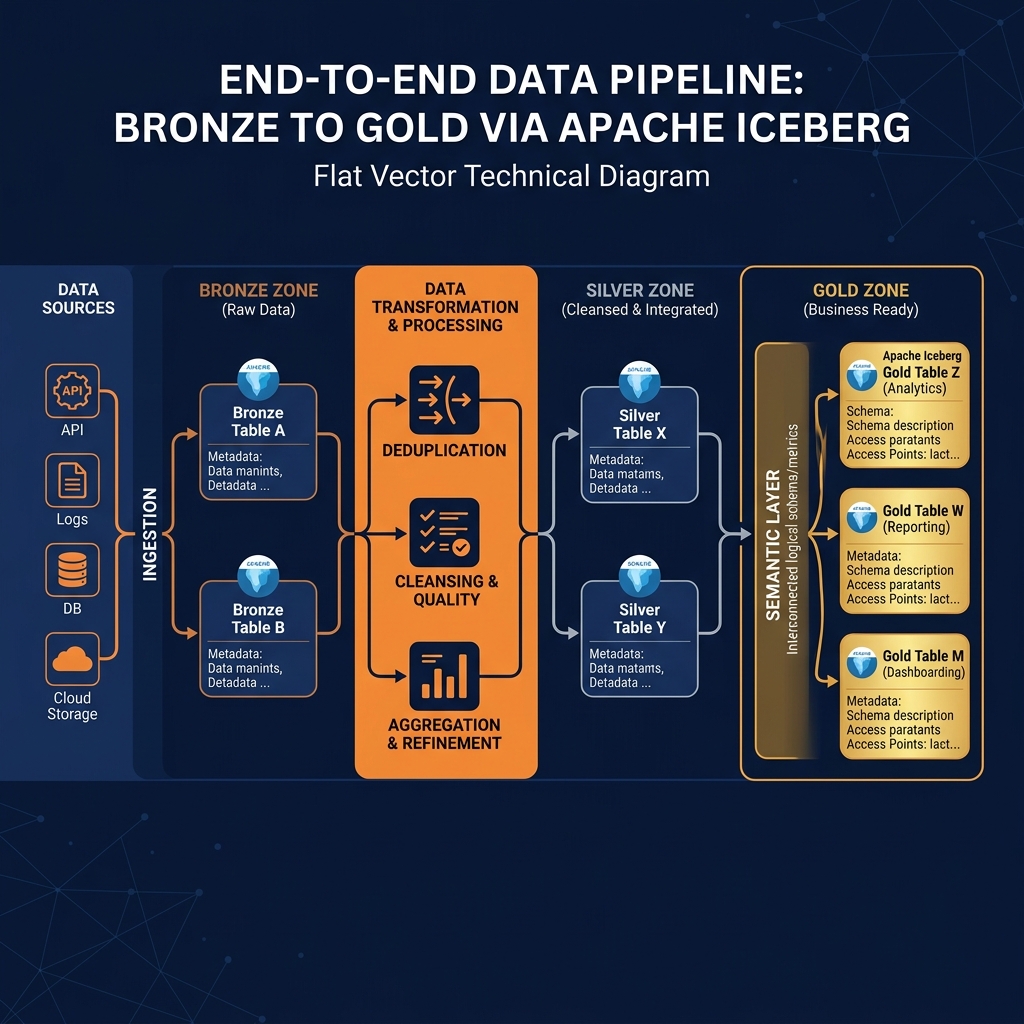
The theoretical benefits of the Medallion Architecture are only achievable if the underlying storage and compute infrastructure can support complex data mutations and high-performance querying. Attempting to build a rigorous Medallion pipeline on raw Parquet files and legacy Hive tables invariably leads to data corruption during the Silver layer’s deduplication and merge phases.
ACID Guarantees with Open Table Formats
Apache Iceberg is the definitive enabler of the modern Medallion Architecture. Because Iceberg provides strict ACID (Atomicity, Consistency, Isolation, Durability) guarantees, data engineers can safely execute complex MERGE INTO operations to upsert CDC data from Bronze to Silver without fear of corrupting the table. Iceberg’s Optimistic Concurrency Control ensures that if two pipelines attempt to update the Silver table simultaneously, they will not overwrite each other’s data.
Furthermore, Iceberg’s Time Travel capabilities make debugging a Medallion pipeline effortless. If an engineer discovers that a bug in the Silver transformation logic corrupted the Gold tables, they can use Time Travel to query the exact state of the Bronze tables as they existed prior to the pipeline run, and seamlessly replay the fixed logic.
Zero-ETL Acceleration with Dremio
Historically, physically moving data from Bronze to Silver to Gold required expensive, rigid ETL pipelines that created massive data duplication and latency. Dremio modernizes this workflow by introducing a Zero-ETL approach to the upper layers of the Medallion Architecture.
While the transition from Bronze to Silver typically still requires physical processing to cleanse and deduplicate the data, the transition from Silver to Gold can be entirely virtualized using Dremio’s Semantic Layer. Instead of building a physical ETL pipeline to generate aggregate tables, data engineers create Virtual Datasets (logical views) in Dremio that define the Gold layer aggregations on top of the physical Silver tables. To ensure sub-second dashboard performance, the engineers enable Dremio Data Reflections on these Gold Virtual Datasets. Dremio automatically materializes, manages, and updates the aggregations under the hood as hidden Iceberg tables.
This hybrid physical/virtual Medallion Architecture minimizes storage costs, drastically reduces ETL pipeline complexity, and empowers business analysts with lightning-fast access to trusted, conformed data directly from the open lakehouse.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.