In-Memory Processing
A guide to in-memory processing, the performance architecture that loads massive datasets entirely into RAM to execute analytical queries at lightning speed, eliminating the bottleneck of reading from physical disks.
Eliminating the Disk Bottleneck
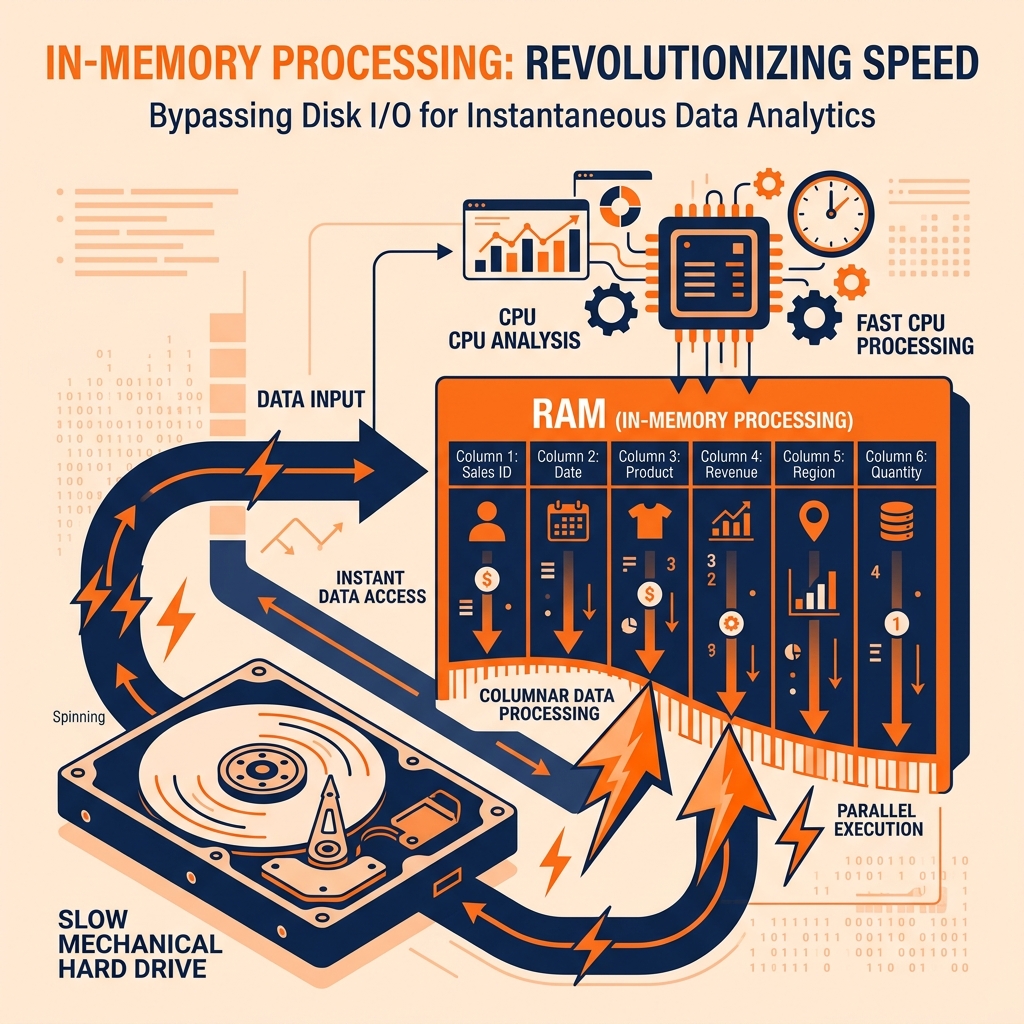
For decades, the biggest bottleneck in database performance was the physical hard drive. When a query executed, the CPU had to wait for the spinning magnetic disk to mechanically find the data and load it into RAM. Even with the advent of solid-state drives (SSDs), disk I/O remains orders of magnitude slower than the speed at which a modern CPU can process data.
In-memory processing solves this bottleneck by entirely eliminating the disk from the active query path. Instead of fetching data from the hard drive on demand, an in-memory database or compute engine loads the entire dataset (or the active “hot” portion of it) directly into the server’s Random Access Memory (RAM) before the query even begins.
When the CPU executes the query, it reads the data directly from RAM at nanosecond speeds, allowing complex analytical aggregations that would normally take minutes on disk to complete in milliseconds.
The Architecture of In-Memory Engines
Apache Spark popularized distributed in-memory processing for big data. Before Spark, Hadoop MapReduce wrote the intermediate results of every step to the physical hard drive, causing massive I/O delays. Spark’s revolutionary architecture kept these intermediate results entirely in distributed RAM across the cluster, leading to a 100x performance increase.
Modern in-memory engines often rely on Apache Arrow, a standardized columnar memory format. When data is loaded into RAM, it is arranged in tight columns rather than scattered rows. This columnar layout in memory allows the CPU to use Vectorized Execution (SIMD instructions) to process millions of values simultaneously without skipping around the RAM chips.
The Cost Trade-off
The primary constraint of in-memory processing is cost. RAM is exponentially more expensive per gigabyte than SSD or cloud object storage (S3).
It is financially impossible for most enterprises to load a 10 Petabyte historical data lakehouse entirely into RAM. Therefore, modern architectures use a tiered approach:
- Cold Data: 10 Petabytes of 5-year-old historical data sits on cheap S3 object storage.
- Warm Data: 100 Terabytes of recent data is cached on the local NVMe SSDs of the compute nodes.
- Hot Data: 1 Terabyte of today’s highly-active sales data is pinned directly in RAM for instant, in-memory dashboard querying.
This tiered architecture balances the blazing speed of in-memory processing with the practical economic reality of enterprise data volumes.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.