Apache Airflow
A guide to Apache Airflow, the open-source workflow orchestration platform that schedules, monitors, and manages complex data pipeline DAGs in production data engineering environments.
The Pipeline Orchestration Problem
Data pipelines in production environments are rarely simple, linear chains of steps that always succeed. A production data pipeline for a financial analytics platform might involve 40 interdependent tasks: extracting data from three source systems, validating schema compatibility, running parallel transformation jobs, executing data quality checks, building Silver and Gold layer tables, refreshing BI dashboards, and sending success notifications. These tasks have complex dependency relationships (Task C cannot start until both Task A and Task B have completed successfully), must run on a schedule (daily at 3 AM), and must handle failures gracefully (retry failed tasks three times, alert on persistent failure, skip downstream dependents when an upstream task fails).
Apache Airflow is the most widely deployed open-source solution for this class of problem. Airflow allows data engineers to define their pipeline workflows as Directed Acyclic Graphs (DAGs) in Python code, schedule those DAGs to run on configurable triggers, monitor their execution through a rich web UI, and manage failures through configurable retry policies, alerting mechanisms, and manual intervention capabilities.
DAGs: Workflows as Code
A DAG in Airflow is a Python script that defines a collection of tasks and the dependency relationships between them. Each task is an instance of an Operator: a template that encapsulates a specific type of work. The PythonOperator executes a Python function. The BashOperator runs a shell command. The SparkSubmitOperator submits a Spark job to a cluster. The dbtRunOperator runs a dbt transformation. The SnowflakeOperator executes a SQL statement against Snowflake.
Defining workflows as Python code is Airflow’s primary architectural advantage over GUI-based scheduling tools. A DAG definition can be version-controlled in Git, code-reviewed by the team, tested in a development environment, and deployed through a CI/CD pipeline. Complex dynamic DAGs (where the set of tasks is determined at runtime based on data conditions) are straightforward to implement in Python but impossible to express in most GUI-based schedulers.
The dependency structure between tasks is defined through the >> operator or explicit set_upstream/set_downstream calls. Tasks with no dependencies run in parallel by Airflow’s scheduler; tasks with defined dependencies wait for their prerequisites to complete before starting.
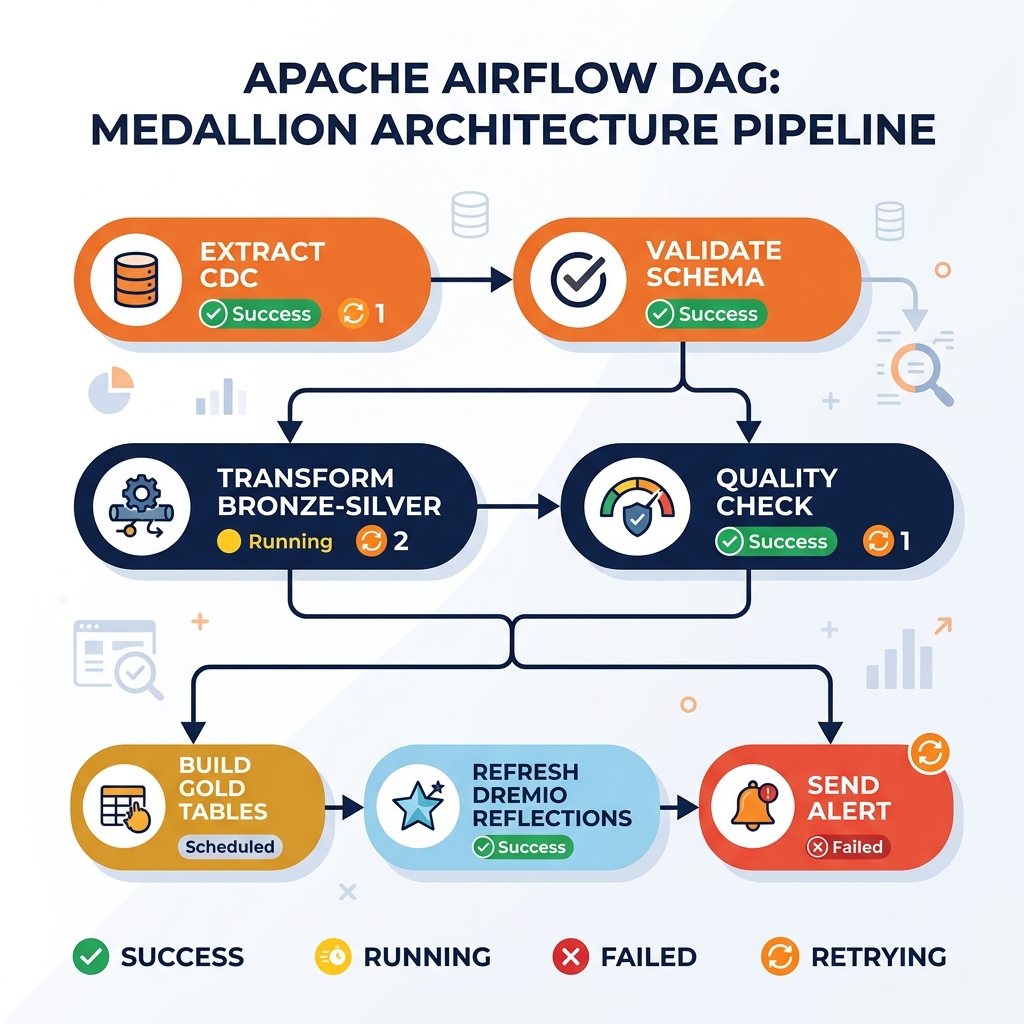
Airflow in the Lakehouse Pipeline
Apache Airflow is the standard orchestration layer for complex Medallion Architecture pipelines. A typical lakehouse Airflow DAG orchestrates the complete Bronze-to-Gold pipeline: scheduling the Debezium CDC extraction to begin, waiting for the raw data to land in the Bronze Iceberg table, triggering the Spark transformation job that processes the Bronze-to-Silver layer, running dbt tests on the Silver tables, triggering the Gold layer aggregation jobs, refreshing Dremio Data Reflections for the updated Gold tables, and sending a pipeline completion notification to the Slack channel.
Airflow’s sensor tasks allow pipelines to wait for external conditions. An S3Sensor waits until a specific file appears in S3 before triggering downstream tasks. An IcebergTableSensor waits until a new Iceberg snapshot has been committed to a specific table. These sensors enable event-driven pipeline patterns where downstream jobs automatically trigger when upstream data is ready, without requiring fixed schedule offsets.
Airflow integrates with Apache Iceberg pipelines through Spark, dbt, and direct Python Iceberg API calls. The PyIceberg library allows Airflow PythonOperator tasks to directly interact with Iceberg catalog APIs for catalog metadata operations (creating tables, running snapshot expiration, triggering compaction) without spawning a full Spark cluster for catalog-only operations.
Managed Airflow Services
Running Airflow in production requires managing the Airflow scheduler, web server, worker processes, and a metadata database (typically PostgreSQL). This operational overhead motivated cloud providers to offer managed Airflow services. Amazon MWAA (Managed Workflows for Apache Airflow), Google Cloud Composer, and Astronomer (a commercial Airflow platform) provide managed Airflow environments with automated scaling, high availability, and simplified DAG deployment.
For Dremio-centric lakehouse architectures, Airflow DAGs can trigger Dremio operations through Dremio’s REST API: running reflections refresh, executing SQL against Dremio’s query engine, and managing virtual dataset definitions through programmatic calls, enabling fully automated end-to-end pipeline management.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.