Materialized Views
A guide to materialized views in data engineering, pre-computed query results stored as physical tables that dramatically accelerate repeated analytical queries by eliminating redundant aggregation and join work.
Paying the Query Cost Once
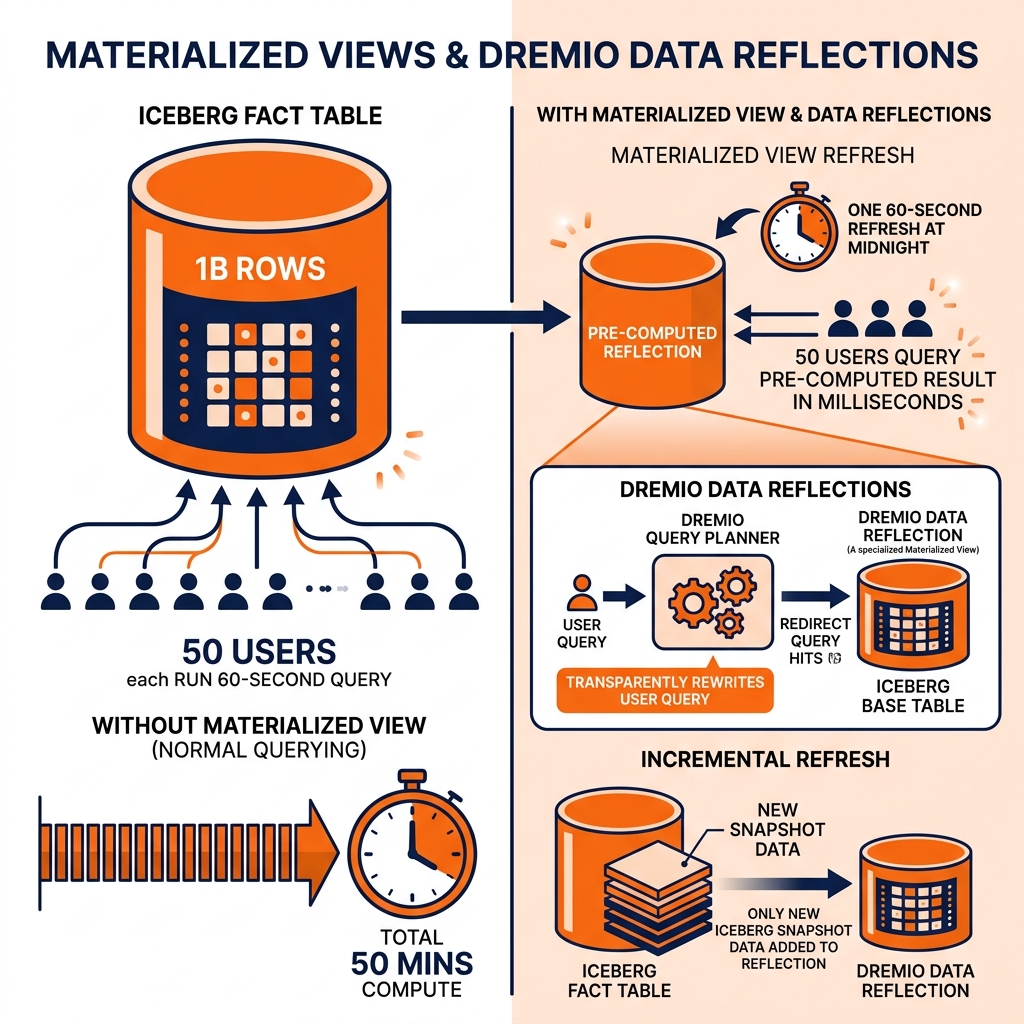
A complex analytical query joining a billion-row fact table with five dimension tables, applying date range filters, computing revenue aggregations by product category and geography, and ordering results may take 30-60 seconds on a well-optimized lakehouse. When this query is executed by 50 dashboard users simultaneously every morning, the lakehouse is performing the same 30-60 seconds of compute work 50 times, each time reading the same data from the same Iceberg files and producing the same results.
A materialized view pre-computes this query result and stores it as a physical table. The materialized view is populated once (at refresh time) by executing the query, and the result is stored in a fast, pre-aggregated format. All 50 dashboard users query the materialized view instead of the underlying fact table, retrieving pre-computed results in milliseconds instead of seconds. The expensive join and aggregation work is performed once (during refresh) rather than 50 times.
Materialized views trade freshness for query speed. The materialized view reflects the state of the underlying data at its last refresh time, not the current live state. For dashboards that need hourly or daily aggregates, this freshness tradeoff is entirely acceptable. For dashboards that need up-to-the-minute data, materialized views require frequent refresh, and the refresh cost and freshness lag must be weighed against the query speed benefits.
Dremio Data Reflections
Dremio’s Data Reflections are the lakehouse platform’s implementation of materialized views, with several capabilities that make them more powerful than traditional database materialized views.
Transparent query acceleration: Dremio’s query planner automatically detects when a user’s query can be answered by an existing Data Reflection, and transparently rewrites the query to read from the reflection instead of the underlying Iceberg table. Users write standard SQL against their Virtual Datasets; Dremio transparently serves results from the appropriate reflection. No query changes are required.
Multiple reflection types: Dremio supports Raw Reflections (storing the full query result set, filtered and projected) and Aggregation Reflections (storing pre-aggregated group-bys). An Aggregation Reflection on (product_category, region, month) with pre-aggregated SUM(revenue) answers any query that groups by any subset of those dimensions and aggregates revenue.
Incremental refresh: For Iceberg-based sources, Dremio supports incremental reflection refresh: only the new data added since the last refresh is incorporated into the reflection, without rebuilding the entire reflection from scratch. This dramatically reduces the compute cost of maintaining fresh reflections on large tables.
Automatic reflection management: Dremio can automatically create reflections based on observed query patterns, identifying common query predicates, group-bys, and join patterns and materializing reflections that will accelerate the most frequent query shapes.
Materialized Views in Iceberg
Apache Iceberg supports materialized views through the CREATE MATERIALIZED VIEW DDL available in Spark and Trino. Iceberg materialized views are stored as Iceberg tables with automatic staleness tracking: when the underlying base tables change (new snapshots are committed), the materialized view is marked as stale and refreshed on the next query or on a scheduled refresh cycle.
The combination of Iceberg materialized views (managed through the Iceberg catalog) and Dremio Data Reflections (managed through Dremio’s Semantic Layer) provides a two-tier acceleration architecture: Iceberg views handle pre-aggregated analytical patterns managed through the catalog, while Dremio reflections handle ad-hoc acceleration patterns detected from real query traffic.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.