Dimension Tables
A guide to dimension tables in dimensional modeling, the contextual tables in a star schema that store the 'who, what, where, and when' attributes used to filter and group analytical metrics.
The Context of the Business
If a fact table holds the numeric measurements of a business event (the “how much”), dimension tables hold the descriptive context surrounding that event (the “who, what, where, when, and why”). In a star schema, dimension tables surround the central fact table, providing the textual attributes used by analysts to slice, dice, filter, and group the data.
When a retail executive asks to see “Total Sales (Fact) grouped by Product Category (Dimension) and Region (Dimension) over the last Quarter (Dimension),” they are leveraging dimension tables to give meaning to raw numbers.
Dimension tables are characteristically wide (containing many descriptive columns) but shallow (containing relatively few rows compared to fact tables). A dim_customer table might have millions of rows, but a fact_sales table will have billions.
Anatomy of a Dimension Table
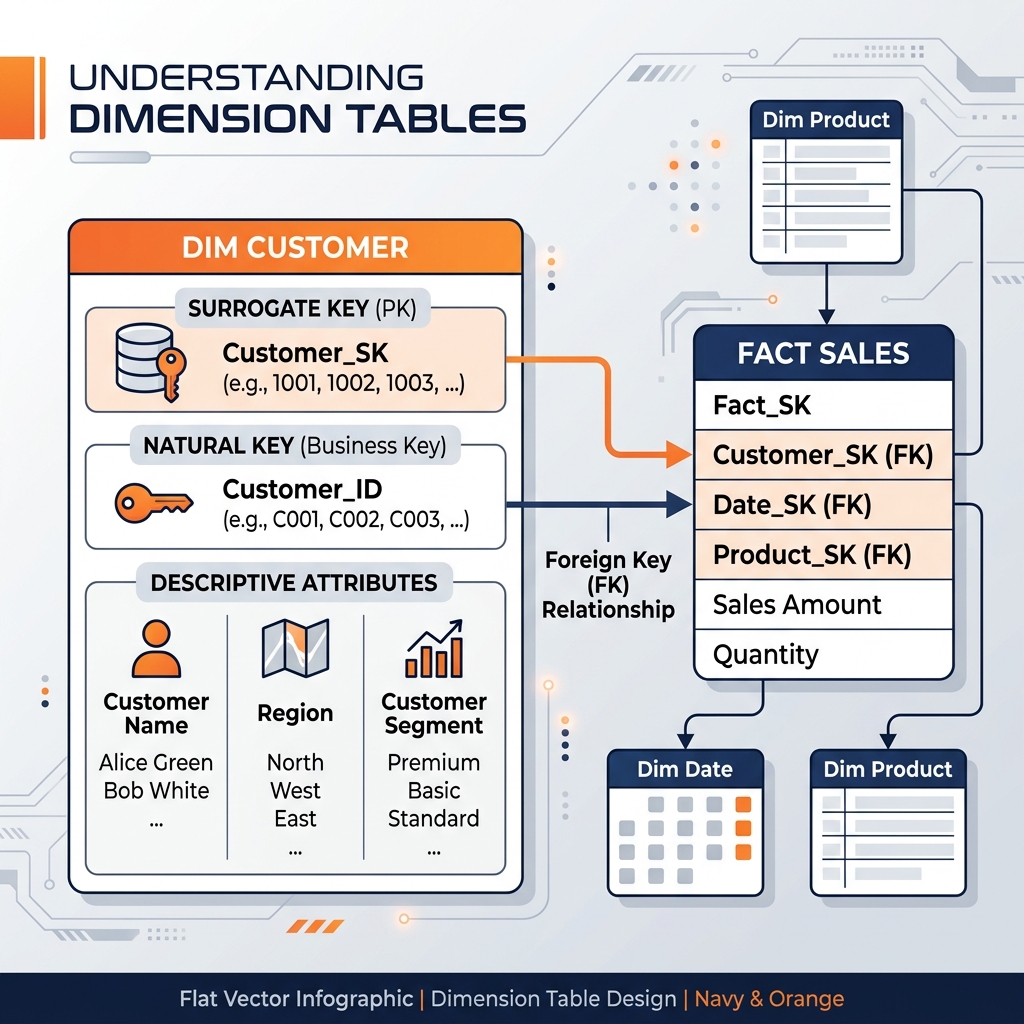
1. Surrogate Key: The primary key of a dimension table is almost always a system-generated integer called a surrogate key (e.g., customer_key = 10452). It uniquely identifies the row in the data warehouse, independent of the operational source system’s natural key (like an email address or CRM ID). Using surrogate keys protects the data warehouse from changes in source system logic and is required for tracking historical changes (Slowly Changing Dimensions).
2. Natural Key: The identifier from the source system (e.g., salesforce_account_id). This is used during the ETL process to match incoming data to the correct dimension row.
3. Descriptive Attributes: The textual columns that users query against. A dim_product table contains attributes like product_name, brand, category, color, and department. The quality of an analytical platform is largely determined by the richness and clarity of its dimensional attributes.
Common Types of Dimensions
Date/Time Dimension: The most universal dimension in any data warehouse. Rather than extracting “month” or “day of week” from a timestamp at query time, a dim_date table contains one row for every calendar day, with pre-computed columns for day_of_week, is_holiday, fiscal_quarter, and is_weekend. This makes complex calendar math trivial in SQL.
Conformed Dimensions: A dimension table that is shared across multiple fact tables. If dim_customer is joined to fact_sales and fact_support_tickets, analysts can seamlessly compare a customer’s purchasing behavior against their support history. Conformed dimensions are the key to breaking down data silos in an enterprise.
Junk Dimensions: A catch-all dimension table created to hold low-cardinality flags and indicators that don’t logically belong in a dedicated dimension table. Instead of adding ten separate boolean flag columns to a massive fact table, the flags are combined into a single dim_transaction_profile table, saving space and improving query performance.
Dimension Tables in the Lakehouse
In the Iceberg lakehouse, dimension tables sit in the Gold layer and are heavily optimized for JOIN performance. Because dimension tables are frequently joined to massive fact tables, query engines (like Dremio or Spark) often broadcast smaller dimension tables (sending a copy of the table to every worker node) to perform incredibly fast hash joins without shuffling the larger fact table data across the network. Keeping dimension tables relatively small and clean ensures these broadcast joins remain highly performant.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.