Surrogate Keys
A guide to surrogate keys in dimensional data modeling, the system-generated artificial identifiers used in data warehouse fact and dimension tables to replace natural business keys and enable efficient joins and slowly changing dimension management.
The Problem with Natural Keys
A natural key is a business identifier that exists in the source system: a customer’s email address, an order number from the order management system, a product SKU from the product catalog. Natural keys are meaningful to business users and identify entities in their source operational context.
In data warehouse dimensional models, using natural keys as join keys between fact tables and dimension tables creates several problems. Natural keys change: customers change email addresses, products are rebranded with new SKUs, order numbers are reformatted when systems are migrated. When a natural key changes, every fact table row that references the old key must be updated, which is expensive in a billion-row fact table. Natural keys also reveal source system implementation details (the order numbering format, the product coding scheme) that should be abstracted in the analytical layer.
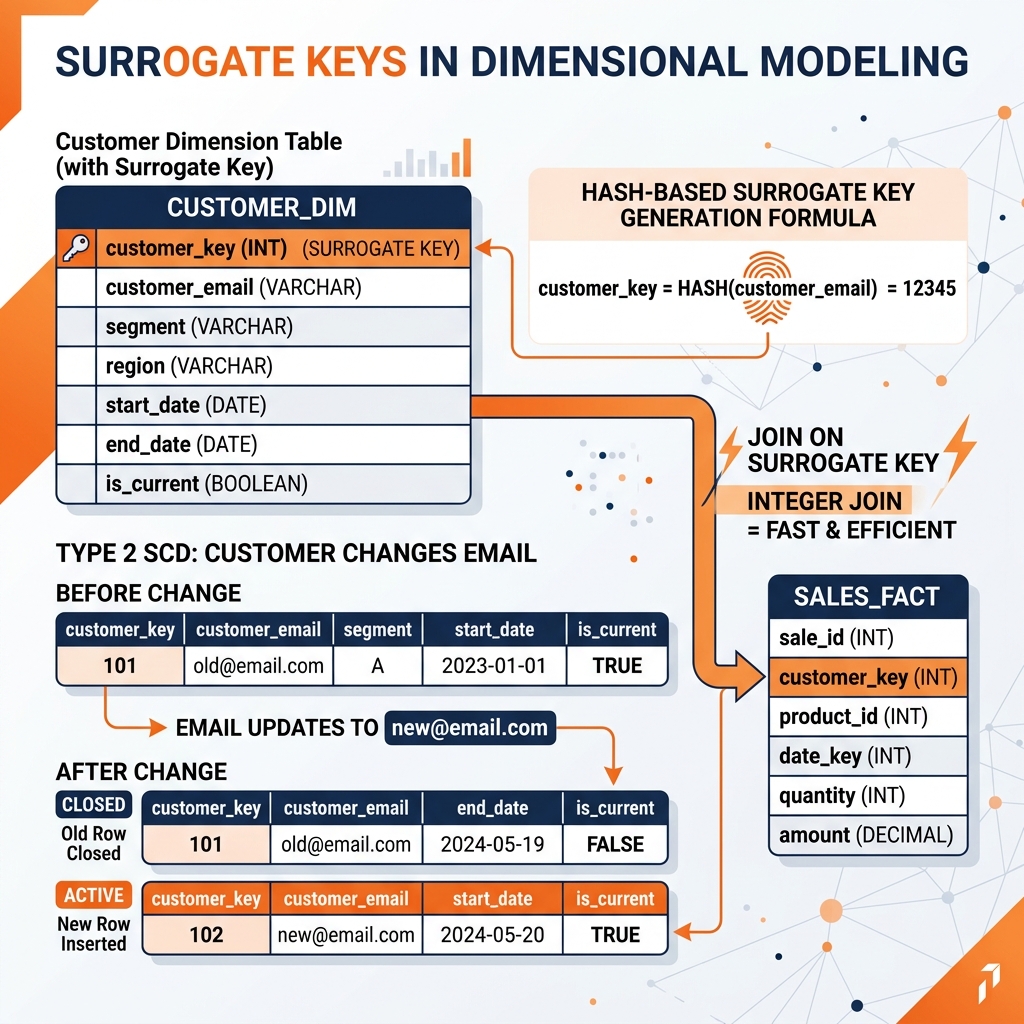
Surrogate keys solve these problems. A surrogate key is a system-generated, meaningless integer identifier assigned by the data warehouse to uniquely identify each row in a dimension table, independent of any source system identifier. When a customer’s email changes, the data warehouse creates a new dimension row for the new email (Type 2 SCD), assigns it a new surrogate key, and future fact rows reference the new surrogate key. Historical fact rows continue to reference the old surrogate key, preserving accurate history of which customer identity was in use at the time of each transaction.
Surrogate Key Generation in the Lakehouse
In traditional data warehouses, surrogate keys were generated through auto-increment sequences managed by the database engine. In a distributed lakehouse without a centralized sequence generator, surrogate key generation requires a different approach.
Hash-based surrogate keys: Many modern lakehouse dimensional models use deterministic hash functions applied to the natural key to generate surrogate keys: CAST(HASH(customer_email, 'SHA256') AS BIGINT). Hash-based surrogate keys are deterministic (the same natural key always produces the same surrogate key), distributed (multiple Spark partitions can generate surrogate keys independently without coordination), and portable (the surrogate key can be computed anywhere from the natural key). The downside is a small risk of hash collisions and the dependency on the hash function being stable across pipeline runs.
Sequence generation with Spark’s monotonically_increasing_id: For tables that are built once from full historical loads, monotonically_increasing_id() generates unique, non-sequential IDs distributed across Spark partitions. These IDs are suitable as surrogate keys but are not reproducible (re-running the job produces different IDs for the same rows).
Surrogate Keys and Iceberg MERGE INTO
Surrogate key-based dimensional models in the Iceberg lakehouse use MERGE INTO for Type 2 SCD management. When a source system record changes (customer email update), the MERGE logic:
- Marks the existing dimension row’s end_date as yesterday and is_current as false.
- Inserts a new dimension row for the changed record with a new surrogate key, today as start_date, and is_current as true.
- Future fact rows reference the new surrogate key.
Iceberg’s ACID MERGE INTO semantics ensure that this multi-row update (closing the old row and inserting the new one) is atomic, preventing readers from seeing a state where the old row is closed but the new row is not yet inserted.
Fact tables join dimension tables on surrogate keys: SELECT f.revenue, c.segment, p.category FROM sales_fact f JOIN customer_dim c ON f.customer_key = c.customer_key WHERE c.is_current = TRUE. The surrogate key join is efficient as an integer comparison, and the is_current filter on the dimension ensures only the current version of each dimension entity is joined.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.