Star Schema
A guide to the star schema dimensional model, the foundational data warehouse design pattern that organizes analytical data into fact tables surrounded by denormalized dimension tables for optimized query performance.
The Foundation of Dimensional Modeling
Star schema is the most widely used data modeling pattern in analytical data warehouses and lakehouses. Developed and popularized by Ralph Kimball in the 1990s, the star schema organizes analytical data around two types of tables: fact tables that record measurable business events and dimension tables that provide the context describing those events.
The name “star schema” derives from its visual appearance: a central fact table is connected to multiple surrounding dimension tables by foreign key relationships, forming a shape that resembles a star with the fact table at the center.
The star schema’s design philosophy prioritizes query performance and analytical simplicity over storage efficiency and normalization. Dimension tables are intentionally denormalized: all descriptive attributes of an entity are stored in a single flat table, even if those attributes could be further normalized into sub-tables. This denormalization means that dimension table rows are wider (more columns) but eliminates the joins needed to retrieve related attributes, making analytical queries faster and simpler to write.
Fact Tables
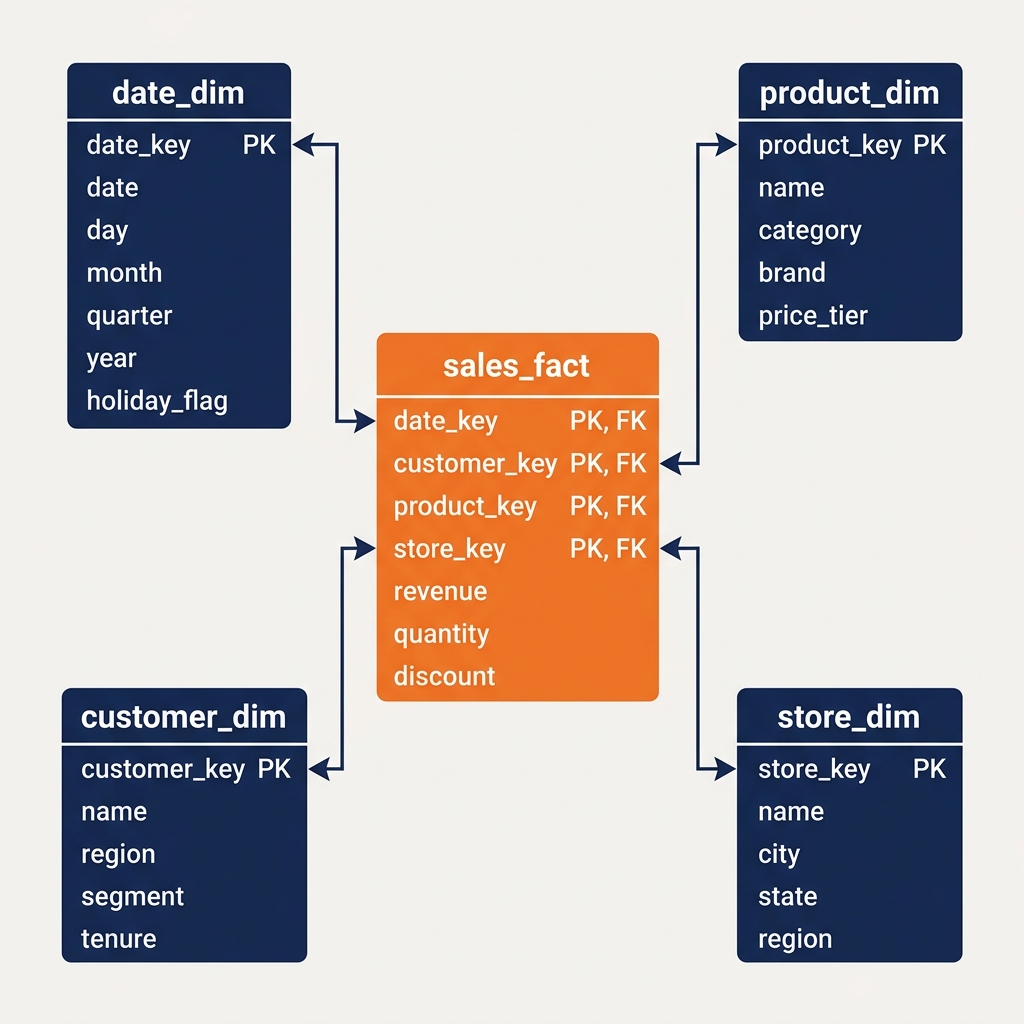
A fact table records measurable business events. Each row in a fact table represents one occurrence of the business process being measured: one sales transaction, one web page view, one order fulfillment, one customer service call. Fact table rows are typically narrow (fewer columns) but very numerous, potentially containing billions or trillions of rows for high-volume events.
Fact table columns fall into two categories. Measures (also called facts) are the numeric values being analyzed: revenue amount, order quantity, session duration, page views, call minutes. Foreign keys are the references to dimension tables that provide context for each event: which customer made the purchase (customer_key), which product was purchased (product_key), when the purchase occurred (date_key), which store location processed the purchase (store_key).
The combination of fact measures with dimension context enables analytical queries like “Sum of revenue by product category by month by region for the last 12 months” through simple joins and group-bys, which execute efficiently on columnar storage engines like Dremio reading from Iceberg Parquet tables.
Dimension Tables
Dimension tables describe the entities that participate in business events. A customer dimension table contains all descriptive attributes of customers: name, email, age band, geographic region, customer segment, acquisition channel, tenure cohort. A product dimension table contains all descriptive attributes of products: name, category, subcategory, brand, supplier, price tier.
Dimension tables are denormalized: the customer’s city, state, country, and geographic region are all stored as columns directly on the customer dimension row, rather than being split across a city table, state table, and country table with join keys. This denormalization makes queries simpler and faster, at the cost of some redundancy (many customers share the same city and state, so those values are repeated for each customer row).
Slowly changing dimensions (SCDs) are an important consideration in dimension table design. When a dimension attribute changes (a customer changes their geographic region, a product moves to a different category), the dimension table must decide whether to overwrite the old value (Type 1 SCD, losing history), add a new row with a validity date range (Type 2 SCD, preserving full history), or maintain both old and new values in separate columns (Type 3 SCD, limited history).
Iceberg’s support for row-level updates (Merge-on-Read delete files) and time travel makes implementing Type 2 SCDs in the lakehouse more efficient than in traditional file-based data lakes, enabling SCD management through MERGE INTO operations with Iceberg’s ACID guarantees.
Star Schema in the Iceberg Lakehouse
Star schema dimensional models map naturally to Iceberg table implementations in the lakehouse Gold layer. Fact tables are typically the largest Iceberg tables in the lakehouse, partitioned by date or event type, and compacted regularly for optimal analytical query performance. Dimension tables are relatively small and often stored as unpartitioned Iceberg tables, fully read on each query.
Dremio’s query planner is particularly effective at optimizing star schema queries, pushing down fact table partition filters before joining with dimension tables and applying dimension attribute filters (WHERE product_category = ‘Electronics’) as early as possible to minimize the data volume flowing through joins.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.