Data Modeling
A comprehensive guide to data modeling, the discipline of structuring and organizing data to accurately represent business processes and enable efficient analytical querying in data warehouses and lakehouses.
The Foundation of Analytical Intelligence
Every reliable analytical system is built on a foundation of intentional data structure. Data modeling is the discipline of deliberately designing how data is organized, related, and stored to accurately represent the real-world business processes it describes and to enable efficient, correct querying by downstream consumers.
The importance of data modeling is frequently underestimated by organizations in the early stages of building analytics platforms. It is tempting to simply dump raw operational data into a data warehouse and allow analysts to write ad-hoc SQL queries against the raw tables. This approach fails rapidly at scale. Raw operational databases are designed to support transactional workloads, optimized for high-speed single-row INSERT, UPDATE, and DELETE operations. Their schemas are deeply normalized across dozens of tables, minimizing data redundancy to protect write performance. Attempting to run analytical aggregations across a heavily normalized operational schema results in enormously complex SQL queries full of multi-level joins that are difficult to write correctly, nearly impossible for non-engineers to understand, and prohibitively slow for the MPP engines of analytical platforms.
Data modeling creates a purpose-built analytical structure that is separate from the operational schema. Rather than forcing analysts to navigate the normalized complexity of the operational system, data modelers denormalize and restructure the data specifically to answer business questions efficiently. The resulting analytical models are simpler to query, more comprehensible to business users, and dramatically faster to execute against the large analytical datasets typical of modern data platforms.
The discipline of data modeling encompasses several distinct paradigms, each suited to different analytical requirements and organizational contexts. Understanding the differences between these paradigms, their respective trade-offs, and the contexts in which each excels is a fundamental competency for any data engineer or analytics engineer working with modern data platforms.
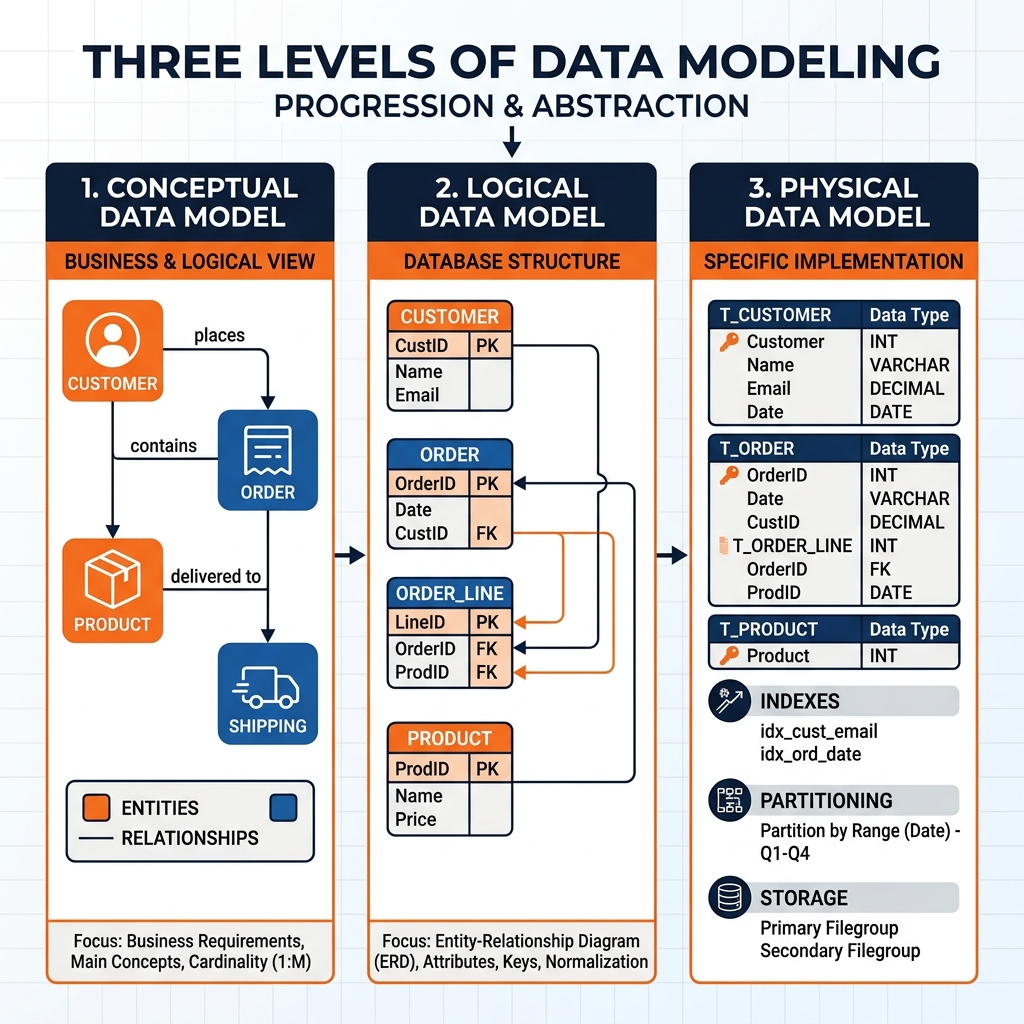
Conceptual, Logical, and Physical Modeling
Data modeling occurs at three distinct levels of abstraction, each serving a different audience and purpose in the design process.
Conceptual Data Models
The conceptual data model represents the highest level of abstraction. It describes the key entities in a business domain and their relationships without reference to any specific database technology or implementation detail. A conceptual model for an e-commerce business might identify the entities Customer, Order, Product, and Supplier, and describe that a Customer places Orders, an Order contains Products, and Products are supplied by Suppliers.
Conceptual models are expressed as Entity-Relationship (ER) diagrams using notation systems like Chen notation or Crow’s Foot notation. They are primarily communication tools used in the early stages of a data warehouse design project to ensure that business stakeholders and data engineers share a common understanding of the scope and structure of the problem domain. A conceptual model deliberately omits technical details like primary key columns, data types, and index strategies because it is intended for business-level communication rather than technical implementation.
Logical Data Models
The logical data model translates the conceptual entities and relationships into a more precise structure that identifies specific attributes (columns) for each entity, defines primary key and foreign key relationships, and establishes normalization rules, but remains independent of any specific database technology.
At the logical level, the Customer entity from the conceptual model becomes a table with specific columns: customer_id (integer primary key), first_name (string), last_name (string), email_address (string, unique), and registration_date (date). The relationship between Customer and Order is expressed as a foreign key: the orders table contains a customer_id column that references the customer_id primary key in the customers table.
Logical modeling is where normalization decisions occur. Database normalization is the process of structuring tables to reduce data redundancy. In First Normal Form (1NF), each table cell contains a single, atomic value. In Second Normal Form (2NF), all non-key columns are fully dependent on the primary key. In Third Normal Form (3NF), no non-key column depends on another non-key column. Highly normalized schemas minimize storage overhead and protect data integrity during write operations, but they produce complex, multi-join query patterns that are poorly suited to analytical workloads.
Physical Data Models
The physical data model translates the logical model into the implementation-specific constructs of a particular database technology. It specifies data types using the exact syntax of the target platform (VARCHAR(255) vs TEXT, BIGINT vs INT), defines partitioning strategies for large tables, identifies which columns should be indexed, specifies clustering keys for warehouse platforms, and documents compression algorithms and storage formats.
Physical modeling decisions have enormous performance implications for analytical workloads. Choosing the wrong partitioning strategy for a billion-row fact table can result in queries that perform full table scans instead of targeted partition reads, increasing query latency by orders of magnitude. In an Apache Iceberg Lakehouse context, physical modeling includes decisions about Iceberg’s Hidden Partitioning transforms, file size targets for Parquet optimization, and sort order configuration for the physical data files.
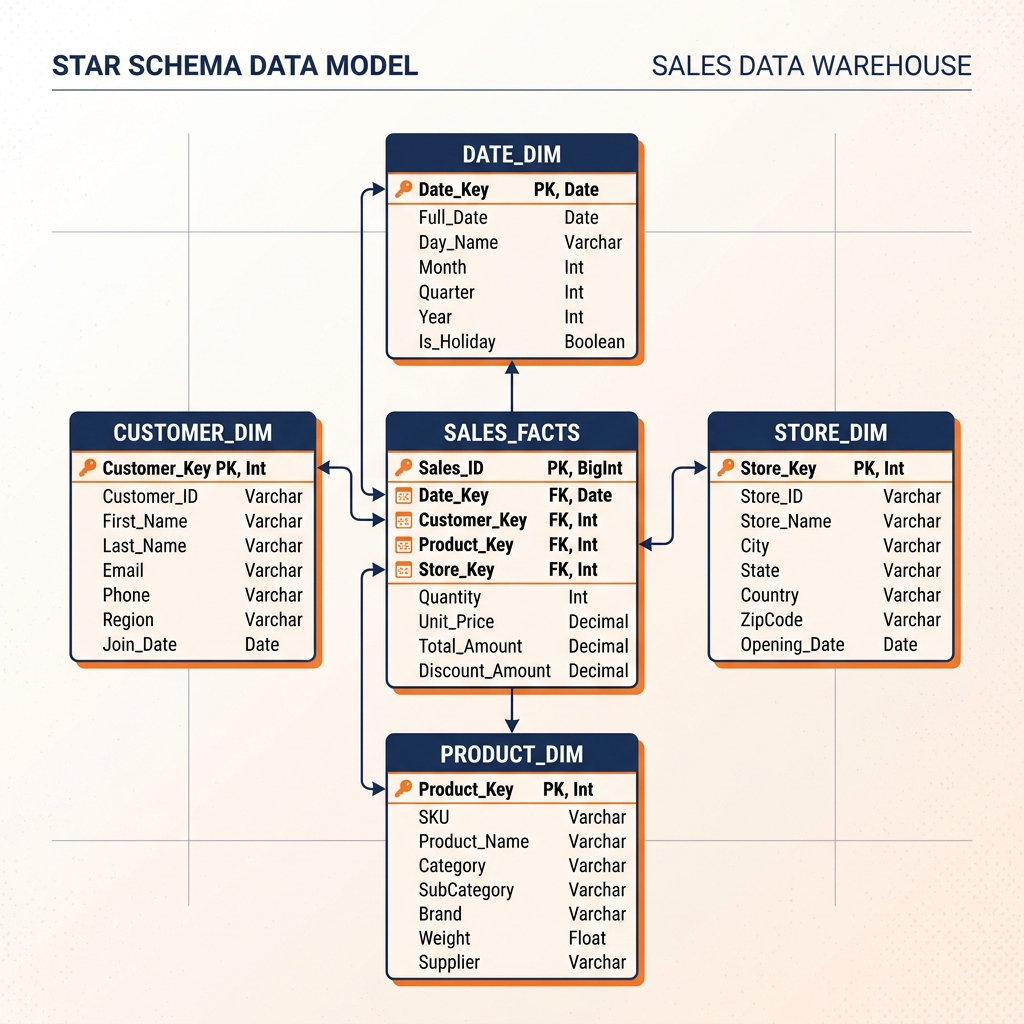
The Star Schema: The Dominant Analytical Model
For analytical workloads, the Star Schema is the most widely used and most well-studied data modeling paradigm. Originally formalized by Ralph Kimball in the 1990s and 2000s, the Star Schema provides a specific denormalization pattern optimized for the query patterns typical of business intelligence reporting.
A Star Schema organizes data around a central Fact table surrounded by multiple Dimension tables. The visual representation resembles a star, with the Fact table at the center and Dimension tables radiating outward, connected by foreign key relationships. This visual metaphor gives the pattern its name.
Fact Tables
The Fact table is the core of the Star Schema. It records the quantitative, measurable events that the business wants to analyze: individual sales transactions, web page views, support ticket submissions, or sensor readings. Each row in the Fact table represents a single measurable event.
Fact tables typically contain two types of columns. Foreign key columns link each event row to the appropriate Dimension table entries: date_key, customer_key, product_key, store_key. Measure columns contain the quantitative values being measured: sales_amount, quantity_sold, discount_applied, unit_cost. Fact tables tend to be extremely wide (many rows) but narrowly focused on keys and measures.
Dimension Tables
Dimension tables provide the descriptive context for the events recorded in the Fact table. A Date Dimension contains one row for every date the business might want to analyze, with columns for the day of week, week number, month name, quarter, fiscal period, and holiday flag. A Customer Dimension contains demographic attributes like customer name, city, state, age group, and customer segment classification. A Product Dimension contains product name, category, subcategory, brand, and product manager.
By joining the Fact table to its Dimension tables using the foreign key relationships, analysts can perform dimensional analysis: grouping transactions by product category, filtering by fiscal quarter, and segmenting by customer demographic group. Because the Dimension attributes are stored in separate tables and joined at query time rather than duplicated in every Fact row, the Star Schema achieves a significant reduction in storage overhead compared to a fully denormalized approach while maintaining excellent query performance.
Slowly Changing Dimensions and Historical Accuracy
One of the most practically challenging aspects of dimensional modeling is handling changes to Dimension attributes over time. A customer moves from New York to Chicago. A product is reclassified from the “Electronics” category to “Smart Home.” A salesperson is transferred from the Northeast region to the Southwest region. These changes create a data management problem: historical Fact table records reference the customer’s previous location, but the Dimension row now reflects their new location.
If the Dimension row is simply overwritten with the new attribute value, all historical sales transactions for that customer will retrospectively appear to have been made by a Chicago customer, even though they were made when the customer lived in New York. This retroactive modification of historical context is analytically catastrophic; it makes it impossible to accurately report how much revenue was generated in New York by New York customers during Q3 last year.
Slowly Changing Dimension (SCD) techniques provide standardized patterns for managing this historical tracking problem. The Type 1 SCD approach simply overwrites the Dimension row with the new attribute value, destroying historical context. This approach is appropriate when historical accuracy is not required for the changed attribute. The Type 2 SCD approach adds a new row to the Dimension table for each change, preserving the historical row and adding effective date columns (valid_from, valid_to) to indicate the period during which each version of the Dimension was active. Historical Fact records continue to point to the original Dimension key, while new Fact records point to the new Dimension key. This approach enables fully accurate historical reporting at the cost of additional Dimension table complexity.
Apache Iceberg’s MERGE INTO syntax provides native SQL support for implementing Type 2 SCD patterns in the lakehouse. When a customer’s address changes, the MERGE statement simultaneously updates the valid_to date on the existing dimension row and inserts the new dimension row with the updated address and a new valid_from date, in a single atomic operation that cannot produce a partially updated state.
Data Vault: Enterprise Scalability and Auditability
For organizations that require extremely high scalability, strict regulatory auditability, and the ability to integrate data from many heterogeneous source systems with minimal upfront modeling decisions, the Data Vault modeling pattern provides an alternative to Kimball-style dimensional modeling.
Data Vault was developed by Dan Linstedt and is built around three core entity types: Hubs, Links, and Satellites. This normalized, insert-only structure is specifically designed to handle the challenges of large-scale, multi-source enterprise data integration.
Hubs represent the core business entities (Customer, Product, Order) by storing only their unique business keys (the raw identifiers used by the source systems) alongside a hash key, a load timestamp, and a source system identifier. Hubs contain no descriptive attributes whatsoever.
Links represent the associations and relationships between Hubs. A Link table connecting the Customer Hub to the Order Hub contains the hash keys of both Hubs and records the fact that a specific customer placed a specific order.
Satellites store the descriptive attributes (context and history) of either a Hub or a Link. A Customer Satellite stores the customer’s name, address, email, and any other attributes, alongside effective date columns that track how these attributes changed over time. Because Satellites are insert-only (new rows are always added rather than existing rows being updated), the complete history of every attribute change is automatically preserved.
The Data Vault approach excels at ingesting data from dozens of heterogeneous source systems simultaneously, because each source can feed its own dedicated Satellites for the Hubs and Links it contributes to. The modeling is highly parallel and does not require the upfront agreement on a unified canonical schema that dimensional modeling demands. However, querying a Data Vault for business reporting requires constructing complex SQL queries that join Hubs, Links, and multiple Satellites, typically through intermediate reporting views or a business vault layer that maps the raw Data Vault structures back to business-friendly entities.
Data Modeling in the Lakehouse Era
The principles of data modeling remain fully relevant in the modern Apache Iceberg Lakehouse, but the technical implementation has evolved significantly. Iceberg provides the transactional foundation that makes the Medallion Architecture the practical implementation of data modeling best practices in the lakehouse context.
The Bronze layer contains raw, unmodeled data ingested directly from source systems. The Silver layer applies the logical modeling decisions: entities are cleansed, deduplicated, and organized into conformed Iceberg tables that implement the conceptual data model. The Gold layer implements the physical modeling decisions: Star Schema Fact and Dimension tables, Data Vault Hubs, Links, and Satellites, or custom business aggregates are materialized as optimized Iceberg Parquet files.
Dremio’s Semantic Layer sits above the physical Gold layer to handle the final presentation modeling. Virtual datasets define the exact joins, metric calculations, and column naming conventions that the BI tools and AI agents will use. Data Reflections manage the automatic physical optimization of these virtual views, ensuring that the complex join queries underlying the Star Schema return in milliseconds. This combination of physical Iceberg-backed dimensional models and logical Dremio Semantic Layer virtual datasets provides the most complete and powerful implementation of data modeling principles in the modern data engineering stack.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.