Apache Parquet
A comprehensive guide to Apache Parquet, the open-source columnar storage format that has become the foundational data file format for modern data lakehouses and analytical processing.
The Row-Oriented Storage Problem
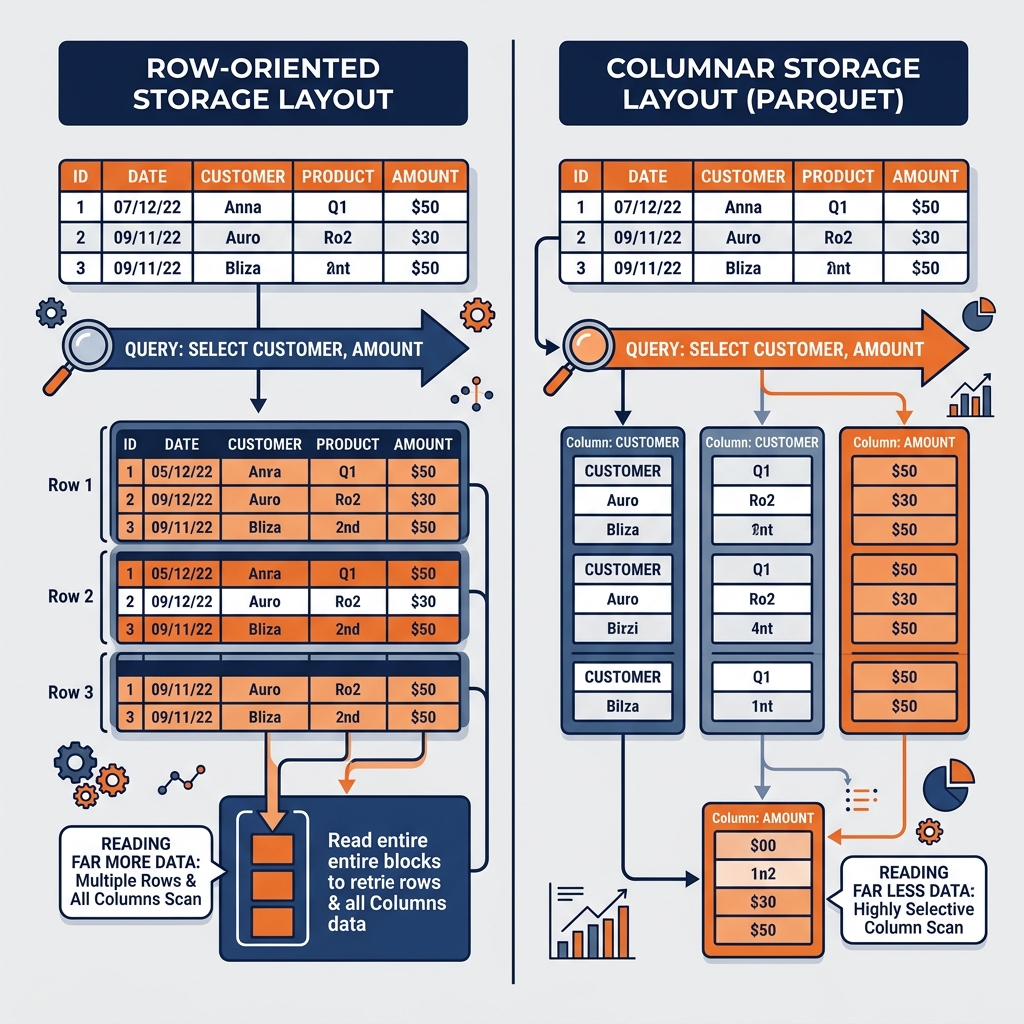
To understand why Apache Parquet became the dominant storage format for analytical computing, one must start with the fundamental limitations of row-oriented storage for analytical workloads. Traditional relational databases, and the flat file formats that grew alongside them (CSV, JSON Lines), store data in a row-oriented layout. In a row-oriented format, all the column values for a single record (row) are stored sequentially together on disk. The first row’s values are written, then the second row’s values, then the third, and so on.
Row-oriented storage excels at transactional, operational workloads. When an application needs to read, insert, or update a complete customer record (all columns for a single customer), row storage is ideal. The database reads the storage location of that row’s address and retrieves all column values in a single sequential read operation. The entire record is co-located on disk, making per-row access extremely efficient.
Analytical workloads, however, operate on the opposite access pattern. When a data analyst runs a query to compute total revenue by product category, the query engine needs to read the sales_amount and product_category columns across hundreds of millions of rows. It needs specific columns from every row, not all columns from specific rows. In a row-oriented storage format, retrieving only two columns from a table with fifty columns requires the query engine to read all fifty column values for every row and then discard forty-eight of them. The ratio of data read to data actually used can be as low as four percent, making row-oriented storage catastrophically inefficient for this pattern.
This inefficiency was acceptable in early data warehouses where total data volumes were manageable and dedicated proprietary hardware could compensate through brute force. As data volumes scaled to terabytes and petabytes in the cloud era, the I/O overhead of reading hundreds of unnecessary columns from billions of rows became an existential performance problem. The industry required a storage format purpose-built for the column-selective access patterns of analytical computation.
The Columnar Storage Model
Apache Parquet was designed around the columnar storage model, which organizes data by column rather than by row. In a columnar layout, all values for the sales_amount column are stored sequentially together, followed by all values for the product_category column, followed by all values for the customer_id column, and so on.
When a query engine needs only sales_amount and product_category, it reads precisely those two columns from storage and ignores the physical locations of all other columns entirely. On a table with fifty columns, this reduces the I/O volume by ninety-six percent compared to a row-oriented layout. This dramatic reduction in I/O is the primary reason columnar formats like Parquet deliver query performance improvements of ten to one hundred times compared to row-oriented formats for analytical workloads.
Column-Level Encoding and Compression
Beyond the I/O reduction benefit, the columnar layout enables highly efficient data compression. When similar values are stored together in a column, compression algorithms can achieve much higher compression ratios than when diverse values from different data types are interleaved as in a row-oriented layout.
Parquet supports multiple encoding schemes optimized for different data patterns. Run-Length Encoding (RLE) is highly effective for low-cardinality columns like status flags or category codes. When a column contains thousands of consecutive rows with the value “COMPLETED”, RLE can represent this as a single record (10000, "COMPLETED") rather than storing the string ten thousand times. Dictionary Encoding converts a column of repeated string values to a compact integer lookup: a country column containing “United States” hundreds of thousands of times stores the string once in a dictionary and replaces every occurrence with a small integer reference. Bit Packing reduces the storage overhead of integer columns by eliminating leading zero bits.
These encoding schemes are applied per-column before general compression algorithms (Snappy, Gzip, Zstandard, LZ4) are applied to the encoded column data. The combination of column-specific encoding and general compression typically reduces Parquet file sizes to fifteen to thirty percent of the equivalent CSV or JSON representation of the same data.
The Parquet File Structure
Understanding the internal structure of a Parquet file clarifies how the format achieves both high compression and efficient selective column reads. A Parquet file is organized into three hierarchical levels: the file, the row group, and the column chunk.
At the outermost level, the Parquet file contains a file-level footer written at the end of the file. This footer stores the file’s schema (column names, data types, and nesting structure) and a summary of all row groups contained in the file.
A Parquet file is divided horizontally into row groups. A row group is a contiguous set of rows (typically targeting 128MB to 512MB) stored together. The row group is the unit of parallel processing: different query engine workers can read different row groups simultaneously. Within each row group, the data for each column is stored as a contiguous column chunk. The column chunk contains all the encoded, compressed values for that column across all rows in the row group.
Within each column chunk, data is further subdivided into pages (typically 8KB). Each page carries its own header with column statistics (min value, max value, null count). These statistics are the foundation of Parquet’s predicate pushdown capability: a query engine can read a page header, determine that the minimum value of sales_amount on that page is 500 and the query requires sales_amount > 1000, and skip reading the entire page. This multi-level pruning (file-level, row-group-level, page-level) ensures that analytical queries read only the minimum possible data from storage.
Parquet, Apache Iceberg, and the Lakehouse
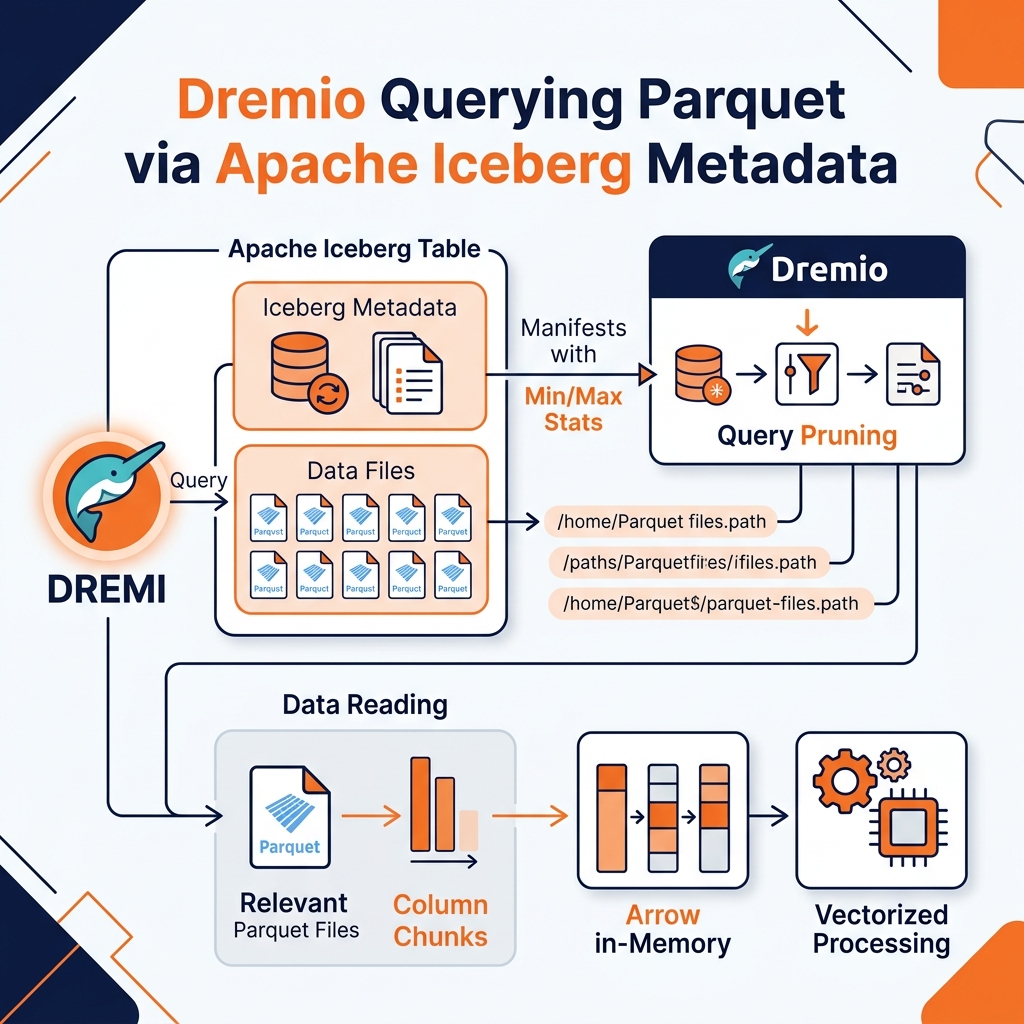
Apache Parquet is the default data file format for Apache Iceberg, the leading open table format for data lakehouses. The integration between these two technologies is what delivers the extraordinary query performance of the modern lakehouse.
Iceberg’s metadata layer (manifests, manifest lists, snapshot files) is stored separately from the Parquet data files. When a query engine (Spark, Dremio, Flink, Trino) needs to execute a query against an Iceberg table, it first reads the Iceberg metadata to determine which Parquet files belong to the current table snapshot. The metadata includes the column-level statistics (min/max/null count) that were captured when each Parquet file was written. The query engine applies predicate pushdown against these statistics to eliminate entire Parquet files before reading a single byte of actual data.
This two-level pruning, Iceberg metadata-level file elimination followed by Parquet page-level elimination, ensures that even queries over tables containing millions of Parquet files return results by reading only a small fraction of the physical data. This is the foundational mechanism that makes the open data lakehouse competitive in query performance with specialized analytical databases, while retaining the infinite scalability and low cost of commodity cloud object storage.
Dremio’s query engine is natively optimized for reading Parquet files via the Apache Arrow columnar memory format. When Dremio reads Parquet data from an Iceberg table, it decodes the columnar Parquet data directly into Arrow columnar memory buffers. Arrow’s vectorized processing capabilities allow Dremio’s execution engine to apply filter predicates and aggregation functions across multiple rows simultaneously using CPU SIMD instructions, delivering maximum throughput from each byte of data read from storage.
File Size and Compaction Best Practices
One of the most important operational considerations for Parquet-based lakehouses is managing file sizes. The performance characteristics of Parquet queries are significantly influenced by the number and size of the files in a table.
Very small files (the “small file problem”) are a common consequence of streaming ingestion pipelines that write Parquet files continuously in small micro-batches. A table containing millions of tiny 1MB files will perform far worse than a table containing thousands of 256MB files, because each file requires a separate object storage API call to open, and each API call carries fixed network overhead regardless of the file size. The overhead of managing millions of file opens can exceed the overhead of the actual data reading.
Apache Iceberg provides a native solution to the small file problem through table compaction operations. Iceberg’s rewrite_data_files procedure reads multiple small Parquet files, combines their contents, re-encodes and recompresses the data, and writes a smaller number of large, optimally sized Parquet files. The Iceberg metadata is atomically updated to reference the new compacted files, and the old small files are marked for deletion. Dremio can automatically trigger compaction as part of its Iceberg table management, ensuring that query performance remains consistently high without requiring manual intervention from the data engineering team.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.