Row-Level Security
A guide to row-level security (RLS) in data lakehouses, the access control mechanism that automatically filters query results to return only the rows a querying user is authorized to see based on their identity attributes.
Invisible Filters for Sensitive Data
Column masking protects sensitive column values by replacing them with masked representations. But some access control requirements go further: certain users should not be able to see certain rows at all, not even in masked form. A regional sales manager should see only the sales records for their own region. A clinical researcher should see only patient records for the clinical trial they are enrolled in. A franchise owner should see only transactions from their own store locations.
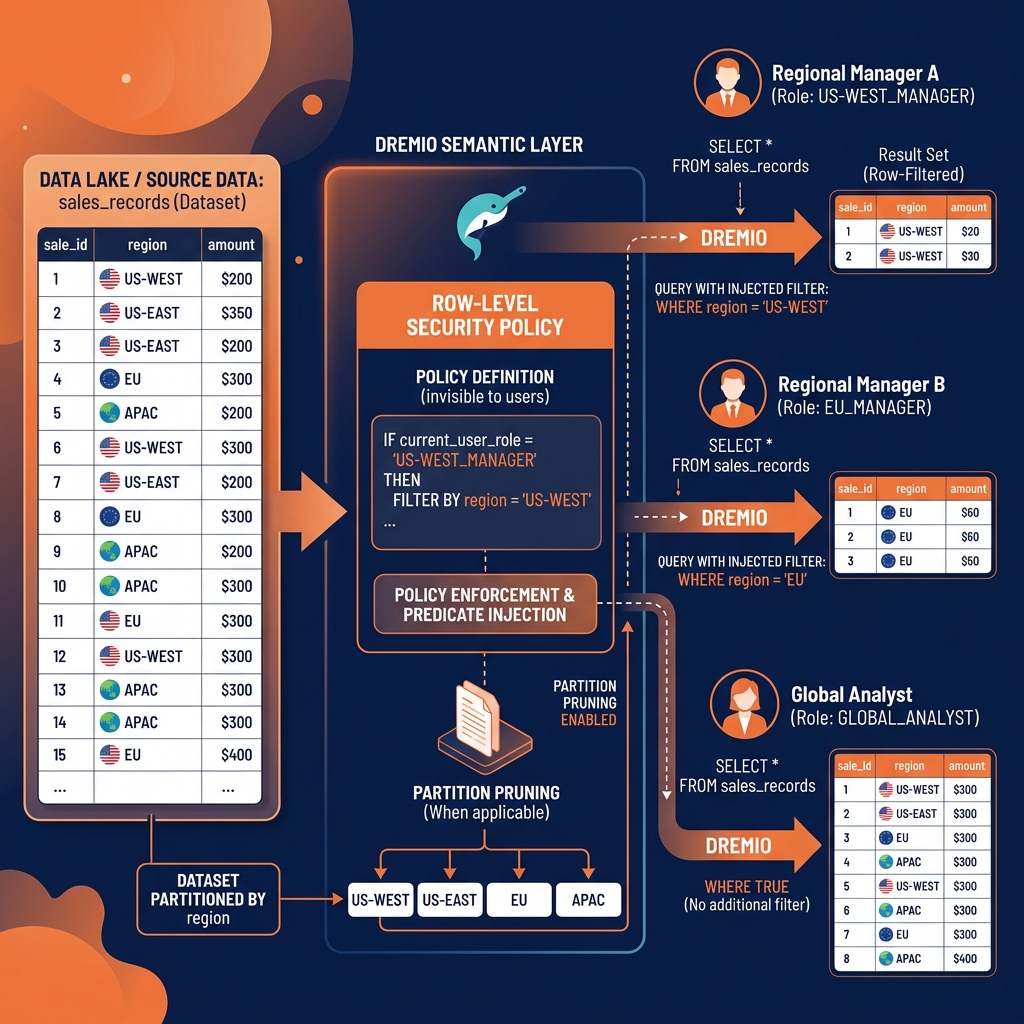
Row-level security (RLS) implements these requirements by automatically injecting a filter predicate into every query against a governed table or view, limiting the result set to only the rows the querying user is authorized to see. The filter is invisible to the user: they write SELECT * FROM sales_records and receive only the records for their authorized region, with no awareness that a row-level filter was applied.
Without row-level security, supporting multi-tenant access patterns requires creating separate tables or views per tenant, which multiplies schema management complexity, storage costs, and pipeline maintenance burden. With row-level security, a single table serves all tenants, with the RLS policy ensuring each tenant’s queries are automatically scoped to their authorized data.
RLS Implementation Models
Row-level security can be implemented at two architectural levels: at the storage layer (within the query engine that reads the data files) or at the semantic layer (within a governed access layer above the raw data).
Storage-layer RLS: Apache Iceberg supports row-level security through its row filter expressions, which can be pushed down to the file scanning level. However, Iceberg itself does not manage user identity; a higher-level system must enforce which row filter applies to which user’s query.
Semantic layer RLS: Dremio’s Semantic Layer implements row-level security through Virtual Datasets with row access policies. A row access policy is a SQL expression that references the current user’s identity (retrieved through CURRENT_USER) or their role memberships to define which rows are visible. For a multi-region sales table, the RLS policy might be: WHERE region IN (SELECT allowed_regions FROM user_region_mapping WHERE user = CURRENT_USER).
This policy is evaluated at query time, injected into every query against the Virtual Dataset, and pushed down to the Iceberg scan where possible. The end result is that each user’s query returns only the rows their identity is authorized to see.
RLS and Performance
A common concern with row-level security is query performance: if every query must evaluate a row-filter subquery, will this significantly increase query latency? The answer depends on the RLS implementation and how well the row filter aligns with the table’s physical organization.
For RLS policies that match partition boundaries (a user is restricted to rows where region = 'US-WEST' and the table is partitioned by region), the row filter maps directly to partition pruning, and only the relevant partition’s files are read. RLS does not add overhead in this case; it is effectively implemented as partition pruning.
For RLS policies that do not match partition boundaries (a user is restricted to a set of customer IDs that are scattered across all partitions), the query must scan all partition files and apply the filter within each file. Bloom filters on the restricting column, if available, can help skip row groups that contain no matching values, partially mitigating the performance cost.
Dremio’s Data Reflections (pre-computed materializations) can be configured to apply RLS policies at reflection refresh time, materializing per-user or per-role subsets of data for ultra-fast query performance, though this involves trade-offs in reflection storage requirements.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.