Table Format Metadata
A comprehensive guide to table format metadata, the structured layers of snapshots, manifests, and statistics that open table formats like Apache Iceberg use to enable ACID transactions, time travel, and efficient query planning.
Why Object Storage Needs a Metadata Layer
Cloud object storage services such as Amazon S3, Google Cloud Storage, and Azure Data Lake Storage Gen2 provide extraordinarily scalable, durable, and cost-effective infrastructure for storing data files. However, they expose a key-value API that knows nothing about tables, rows, schemas, or data types. An S3 bucket is simply a flat namespace of objects identified by string keys. There is no concept of a transaction, no notion of schema enforcement, and no facility for coordinating concurrent writers.
When Apache Hadoop first brought distributed computing to commodity storage, it addressed this gap by delegating table metadata management to the Hive Metastore (HMS). The HMS was a relational database that tracked which partitions a Hive table had, where each partition’s files were stored, and what the table’s schema was. This partition-level metadata worked adequately for tables organized into coarse partitions (by year and month), but it scaled poorly to tables with millions of data files, and it provided no transactional protection against concurrent writes.
The modern open table formats, Apache Iceberg, Apache Hudi, and Delta Lake, were each designed to replace this inadequate metadata layer with a rich, self-describing, and transactionally consistent metadata architecture stored alongside the data files in object storage itself. Understanding table format metadata is understanding how these formats deliver database-grade guarantees on top of dumb object storage.
The Apache Iceberg Metadata Architecture
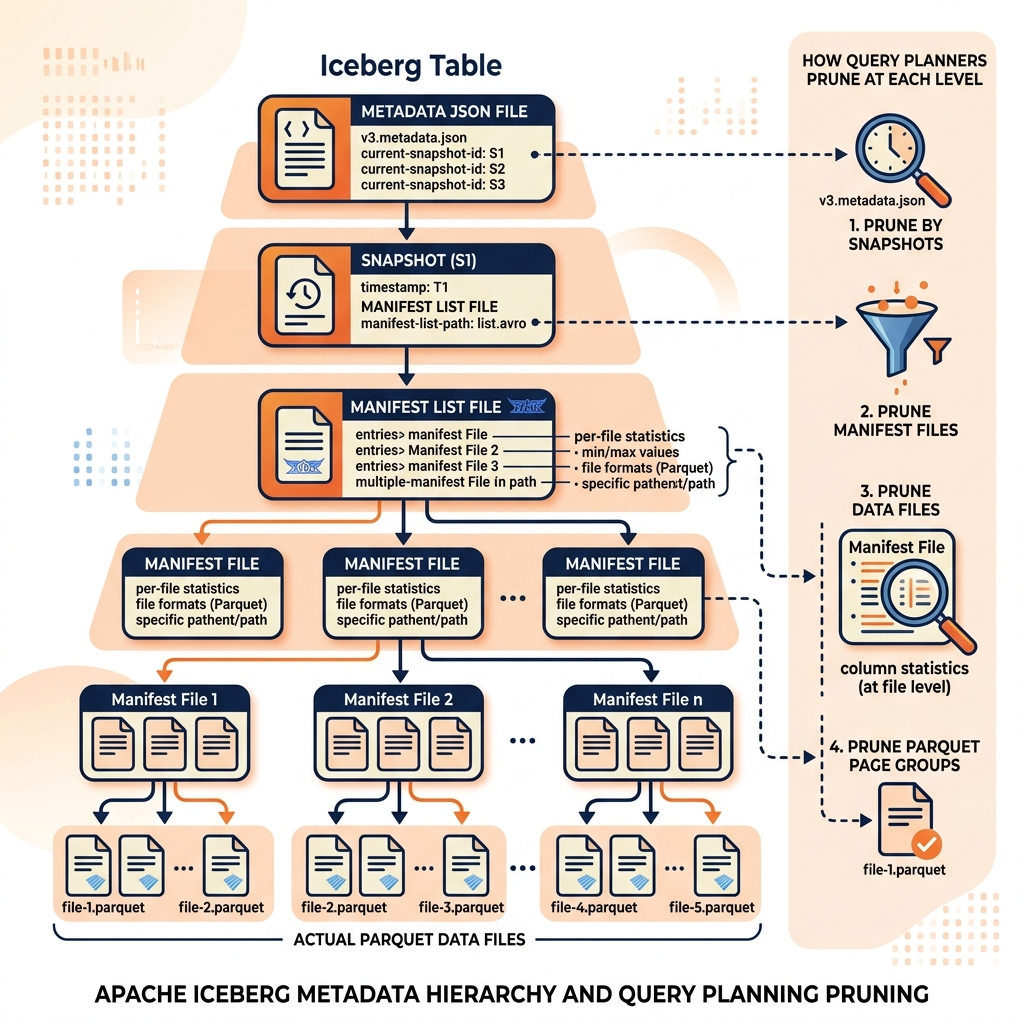
Apache Iceberg’s metadata architecture is the most formally specified and widely studied of the open table formats. It consists of four hierarchical layers, each serving a distinct purpose in the overall metadata system.
Snapshot Files
The Snapshot file is the top-level metadata artifact for each committed version of an Iceberg table. Each write operation that commits data changes to an Iceberg table produces a new Snapshot. The Snapshot contains a unique snapshot ID, a timestamp, a reference to the Manifest List file for this snapshot, and summary statistics (total record count, total file size).
The current table state is defined by the table’s most recent Snapshot. When an Iceberg reader opens a table, it reads the current metadata file, identifies the current Snapshot, and begins navigating down the metadata hierarchy to find the actual data files. Time Travel queries specify an older snapshot ID or timestamp, and the reader navigates from that historical Snapshot rather than the current one.
Manifest Lists
The Manifest List is a file that lists all of the Manifest files belonging to a specific Snapshot. A Snapshot for a large table might reference hundreds or thousands of Manifest files. Critically, the Manifest List does not merely list Manifest file paths; it also stores per-Manifest summary statistics: the minimum and maximum values of every partitioned column across all data files in that Manifest.
These per-Manifest statistics are the foundation of Iceberg’s first-level query pruning. When a query engine receives a predicate such as WHERE transaction_date >= '2024-01-01', it reads the Manifest List and immediately eliminates every Manifest whose transaction_date max value is less than January 1, 2024. Only the Manifests that could potentially contain matching rows are read further. In large tables partitioned by date, this pruning can eliminate 99% of the metadata layer before a single data file path is even read.
Manifest Files
Manifest files are the heart of Iceberg’s file-level metadata. Each Manifest file is an Avro file containing a list of data file entries. For each data file it tracks, the Manifest records the file path, the file format (Parquet, ORC, or Avro), the partition values for that file, the record count, the file size in bytes, and column-level statistics: the minimum value, maximum value, and null count for every column in the table.
These column-level statistics power Iceberg’s second-level query pruning, operating at the data file level. Within the Manifests that survived the Manifest List pruning, the query engine reads each data file entry and applies predicate pushdown against the per-file statistics. A data file whose customer_id maximum value is 50,000 is immediately skipped for a query filtering WHERE customer_id = 75,000. Only data files that could contain matching rows are actually read from object storage.
Data Files
At the base of the metadata hierarchy are the actual data files, typically stored as columnar Apache Parquet files. These are the files containing the raw row-and-column data that satisfies the analytical query. By the time the query engine reaches this level, the multi-level metadata pruning has already eliminated the vast majority of data files from consideration.
Metadata Management Operations
The metadata layer requires ongoing maintenance to remain performant as data volumes grow and write operations accumulate. Three key operations manage Iceberg table metadata health.
Snapshot Expiration: Each write creates a new Snapshot, and older Snapshots are retained for Time Travel. Retaining every Snapshot indefinitely would cause the Manifest List and Manifest files for ancient Snapshots to accumulate, consuming storage and slowing down metadata reads. The expire_snapshots procedure deletes Snapshots older than a retention threshold, removing the associated orphaned metadata files and data files that are no longer referenced by any retained Snapshot.
Manifest Rewriting: As tables grow through many small writes, the number of Manifest files per Snapshot grows. The metadata read path becomes slower because more Manifest files must be read to enumerate all data files. The rewrite_manifests procedure consolidates many small Manifest files into fewer large Manifest files, improving metadata read performance without changing any of the underlying data.
Data File Compaction: The rewrite_data_files procedure addresses the small file problem by reading multiple small Parquet files, combining their contents, and writing a smaller number of larger, optimally sized Parquet files. It updates the Manifest files atomically to reference the new compacted files.
Dremio’s Use of Iceberg Metadata
Dremio reads Apache Iceberg metadata as the foundation of its query planning process. When a Dremio query references an Iceberg table, Dremio’s query planner reads the current Snapshot and Manifest List, applies partition pruning and column statistics pruning against the Manifest entries, and passes only the paths of the relevant data files to its distributed scan operators. Dremio’s Data Reflections are also managed as Iceberg tables, meaning that Reflection maintenance operations (refresh, expiration) use the same Iceberg metadata machinery as any other lakehouse table.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.