Apache Hudi
A comprehensive guide to Apache Hudi, the open-source data lakehouse storage format from Uber that pioneered incremental data processing and upsert capabilities for streaming workloads on object storage.
The Uber Origin: Born From Streaming Necessity
Apache Hudi (Hadoop Upserts Deletes and Incrementals) was created at Uber in 2016 to solve a specific, pressing production problem that the existing Hadoop ecosystem could not address. Uber’s data infrastructure processed hundreds of billions of events daily, ranging from trip records and driver location pings to payment transactions and customer support tickets. These events needed to flow from operational databases and real-time event streams into Hadoop-based data warehouses for analytical processing by the data science and operations teams.
The fundamental challenge was managing late-arriving data and corrections. In any large-scale distributed system, data does not always arrive in perfect chronological order. A trip record might be finalized and committed to the operational database several minutes after the trip itself concluded, due to network delays and retry mechanisms in the mobile applications. If the data pipeline was a simple append-only system that wrote new Parquet files each day, there was no practical way to correct or update previously written records when the late-arriving data arrived.
Furthermore, Uber’s regulatory and compliance requirements mandated the ability to delete specific user records from the data lake to honor right-to-deletion requests under privacy regulations. In a traditional append-only Hadoop data lake, performing deletions required full partition rewrites, which was prohibitively expensive at Uber’s scale.
Hudi was engineered to provide upsert (update or insert) and delete semantics directly on top of HDFS and later cloud object storage, enabling Uber to build efficient streaming ingestion pipelines that could handle late data, correct historical records, and process deletion requests without requiring full partition rewrites. The project was open-sourced in 2019 and donated to the Apache Software Foundation, eventually graduating to a top-level Apache project.
Core Table Types: Copy-on-Write and Merge-on-Read
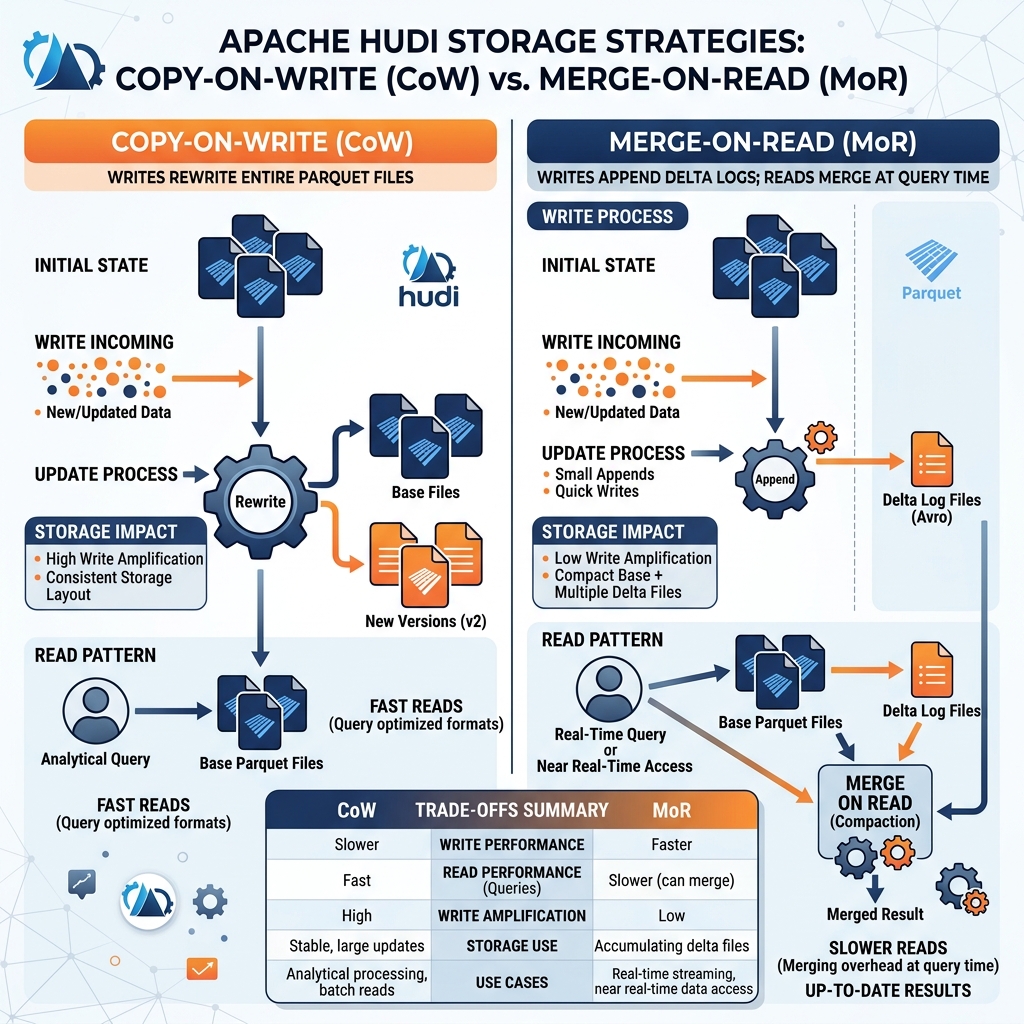
The most distinctive architectural feature of Apache Hudi is its support for two fundamentally different storage strategies for handling writes: Copy-on-Write (CoW) and Merge-on-Read (MoR). The choice between these two strategies reflects different trade-offs between write latency, read performance, and operational complexity.
Copy-on-Write Tables
In a Copy-on-Write Hudi table, every write operation that updates an existing record rewrites the entire Parquet file containing that record. When an upsert operation arrives with updates to one thousand records spread across ten Parquet files, Hudi rewrites all ten files, incorporating the updates, and marks the old versions as obsolete. The new snapshot of the table consists entirely of complete, fully merged Parquet files.
The advantage of CoW is that read performance is excellent. Because the data files always contain the current, fully merged state of every record, any query engine that reads the table sees a clean, consistent dataset without needing to apply any merge logic at read time. The query simply reads the Parquet files.
The disadvantage of CoW is high write amplification. Rewriting entire Parquet files for updates that touch only a small percentage of rows in each file is computationally expensive and slow. For workloads with frequent updates to scattered records, CoW tables become write bottlenecks.
Merge-on-Read Tables
In a Merge-on-Read Hudi table, incoming writes are handled differently: updates are written as small delta log files stored alongside the base Parquet files rather than rewriting the base files themselves. An incoming upsert writes only the changed records to a compact Avro-formatted delta log file. The base Parquet files are not modified.
Writes to MoR tables are much faster than CoW writes because they write only the changed records rather than entire files. This makes MoR ideal for high-frequency streaming ingestion where low write latency is critical.
The trade-off is that reads require a merge operation. When a query engine reads a MoR table, it must merge the base Parquet files with the delta log files to produce the current state. This merge operation adds read latency compared to a clean CoW table read. Hudi mitigates this through a background compaction process that periodically merges the delta logs back into the base files, reducing the read-time merge burden.
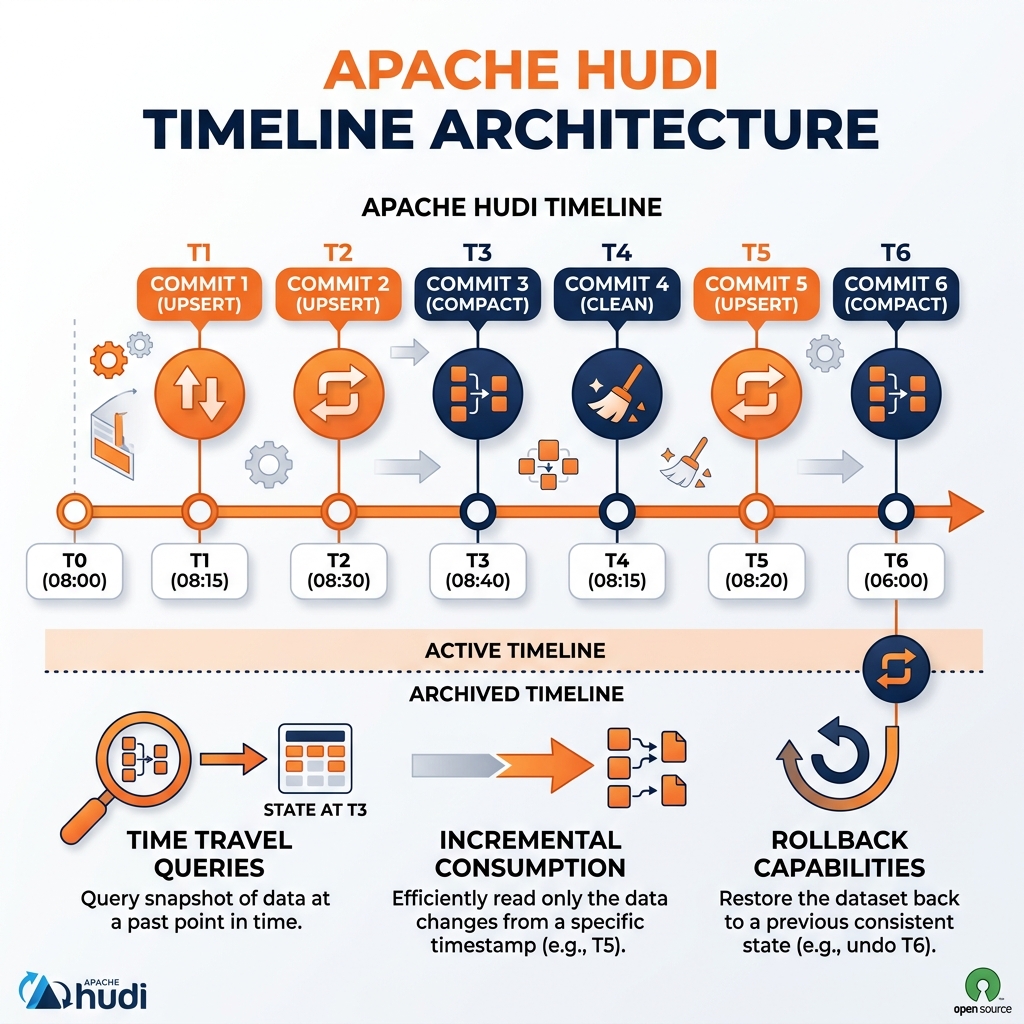
The Hudi Timeline: MVCC and Atomicity
Hudi implements a transaction log called the Hudi Timeline that tracks every action taken on a table. The Timeline is stored as a sequence of files in a .hoodie metadata directory alongside the data files. Every write, compaction, clean, rollback, and save-point action is recorded as a timestamped entry in the Timeline.
This Timeline serves multiple critical purposes. It provides Multi-Version Concurrency Control (MVCC): each snapshot of the table is identified by its Timeline timestamp, and multiple readers can query different consistent versions of the table simultaneously. It enables Time Travel queries by allowing query engines to read the table as of any historical snapshot timestamp recorded in the Timeline. It provides atomicity guarantees: a write transaction either fully commits (the Timeline entry is marked as completed) or is automatically rolled back (incomplete entries are detected and cleaned on restart), preventing partial writes from becoming visible.
The Timeline also powers Hudi’s most distinctive capability: incremental queries. Rather than querying the full current state of the table, consumers can query only the records that changed since a specific Timeline timestamp. This incremental consumption model enables highly efficient downstream pipeline propagation, allowing a job to process only the new or changed records since its last run rather than reprocessing the entire table on every cycle.
Hudi’s Position in the Open Table Format Landscape
Apache Hudi occupies a distinct position in the open table format ecosystem alongside Apache Iceberg and Delta Lake. All three formats were developed within the 2016-2019 timeframe to solve the fundamental problem of reliable, updatable, ACID-compliant data management on object storage at scale. Each format reflects the priorities and constraints of its originating organization.
Hudi’s origins at Uber are evident in its strong native support for streaming ingestion, incremental processing, and the MoR storage strategy optimized for high-frequency writes. Hudi includes built-in facilities for index management (maintaining a record-level index that allows Hudi to quickly locate which data file a specific record key resides in, enabling efficient targeted upserts), and it integrates tightly with Apache Spark and Apache Flink for streaming pipeline construction.
Apache Iceberg, developed at Netflix and later at Apple and Airbnb, reflects a strong emphasis on schema evolution, partition evolution, ACID correctness, and interoperability across compute engines. Iceberg’s hidden partitioning and catalog API have made it the most broadly interoperable format, now supported natively by AWS Glue, Apache Polaris, Project Nessie, and every major compute engine.
Delta Lake, originating at Databricks, emphasizes tight integration with the Databricks platform and Apache Spark, with a strong focus on MERGE INTO operations and Delta Live Tables as a managed streaming ETL framework.
The industry has broadly converged on Apache Iceberg as the default open table format for new lakehouse implementations due to its superior engine interoperability and catalog standardization, but Hudi remains valuable and widely deployed in organizations with existing Hudi-based pipelines and strong streaming ingestion requirements.
Hudi with Dremio and the Modern Stack
Dremio supports reading Apache Hudi tables directly, allowing organizations with existing Hudi-based lakehouses to leverage Dremio’s Semantic Layer and query acceleration capabilities without migrating their data to a different format. Dremio reads Hudi Copy-on-Write tables natively through their Parquet data files and supports the Hudi metadata table for efficient file listing.
For new lakehouse implementations, Dremio recommends Apache Iceberg as the primary table format due to its broader ecosystem interoperability and the superior ACID semantics of its catalog-based snapshot management. Organizations migrating from Hudi to Iceberg can use Apache Spark to read existing Hudi tables and write the output as Iceberg tables, completing the migration without reprocessing the underlying raw data.
The broader lesson of Hudi’s evolution is that the open table format space has matured dramatically. The fundamental capabilities that Hudi pioneered, including upserts, incremental processing, and MVCC on object storage, are now table stakes in any serious open table format. The ongoing differentiation between Hudi, Iceberg, and Delta Lake increasingly centers on ecosystem breadth, catalog standardization, and specific streaming performance characteristics rather than fundamental capability gaps.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.