Delta Lake
A comprehensive guide to Delta Lake, the open-source storage layer from Databricks that brings ACID transactions, scalable metadata handling, and data versioning to Apache Spark and the data lakehouse.
The Databricks Origin: Bringing Reliability to Spark
Delta Lake emerged from the practical challenges Databricks engineers encountered deploying Apache Spark at enterprise scale. While Spark’s distributed processing capabilities were transformative, the underlying storage layer presented serious reliability problems for production data pipelines. Spark reads and writes data as plain Parquet or CSV files on object storage, with no inherent transactional protection between the compute layer and the file system.
This lack of atomicity created multiple classes of production failures. When a Spark job writing a large dataset to S3 failed midway through, it left partially written files visible to downstream readers. Queries reading the table during a write would encounter an inconsistent mix of old and new data files. Failed jobs required manual cleanup of partial files before they could be safely retried. These partial-write failures were a constant source of data quality incidents in production Spark pipelines.
Furthermore, Spark’s default behavior was to overwrite entire partitions when updating data. Updating a single record in a partition containing one billion rows required rewriting the entire partition, creating enormous write amplification for tables that received frequent small updates. There was no practical mechanism for selective row-level updates or deletes short of rewriting entire partitions.
Databricks engineers built Delta Lake internally to solve these problems and open-sourced it in 2019 through the Linux Foundation. Delta Lake adds a transaction log layer on top of Parquet files stored in object storage, providing ACID transactions, MERGE INTO semantics for row-level upserts, schema enforcement, and time travel capabilities to any Spark-compatible data pipeline.
The Delta Log: Foundation of ACID Guarantees
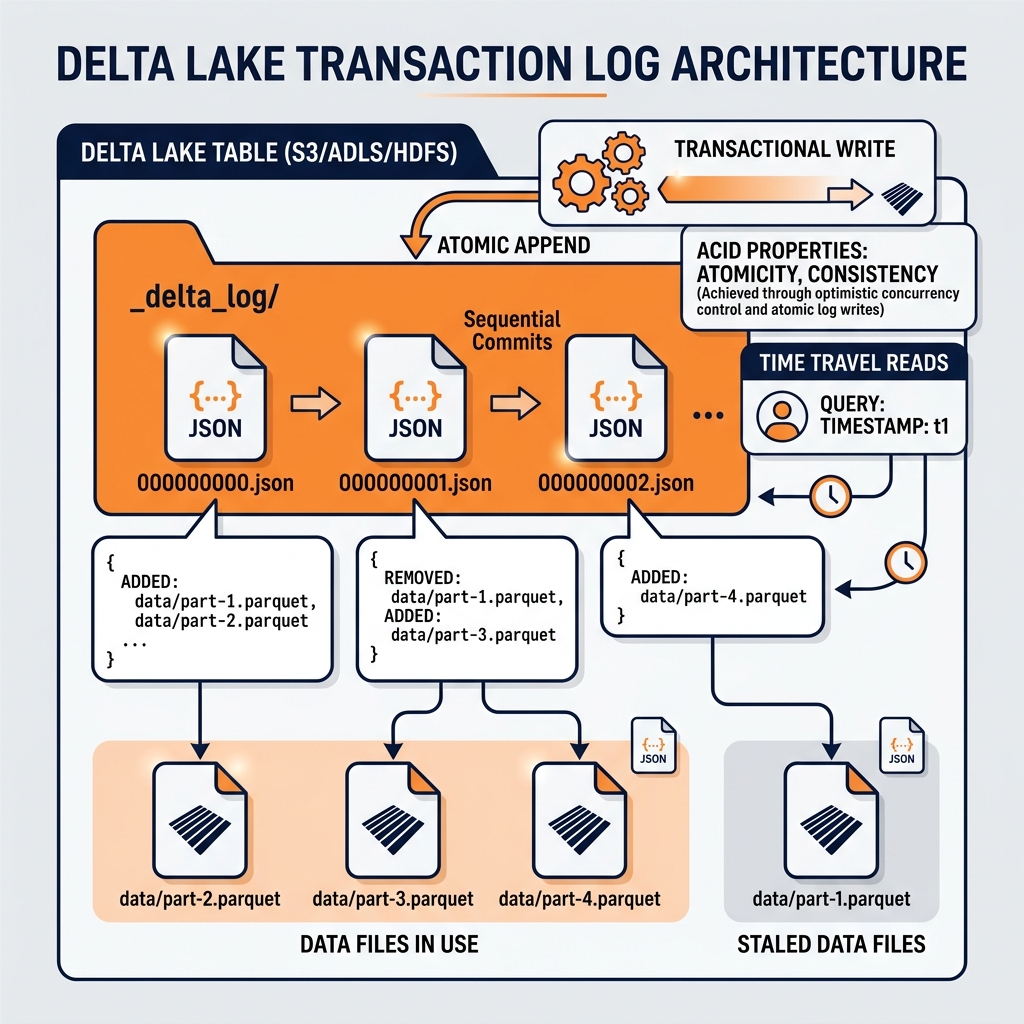
The architectural foundation of Delta Lake is the Delta transaction log, a directory named _delta_log stored alongside the data Parquet files in the table’s storage location. The transaction log is an ordered sequence of JSON files, each representing a single committed transaction. Each JSON file contains an ordered list of actions that describe exactly what changed in that transaction: which Parquet files were added, which were removed, and what the resulting table statistics are.
Atomicity Through Append-Only Log
The Delta log provides atomicity through its append-only structure. A transaction is not considered committed until its JSON log entry is successfully written to object storage. If a Spark write job fails before completing the log entry, no partial state is ever visible to readers; the incomplete Parquet data files that were written before the failure are invisible because no log entry references them. The table’s state as seen by readers is exactly the set of Parquet files referenced by the most recent committed log entry.
When a failed job is retried, it begins fresh, writing new Parquet files and completing a new log entry. The orphaned files from the failed attempt are eventually cleaned up by the Delta vacuum operation.
Isolation Through Optimistic Concurrency Control
Delta Lake implements Optimistic Concurrency Control (OCC) to manage concurrent writers. When two Spark jobs attempt to write to the same Delta table simultaneously, each reads the current state of the transaction log, makes its changes, and attempts to append its new log entry. If both jobs write their log entries simultaneously, one will succeed and the other will detect a conflict (because the log has already advanced to a new version) and will automatically retry its transaction, re-reading the updated log and resolving any conflicts.
This OCC mechanism allows multiple simultaneous writers to a Delta table without requiring distributed locking, which would introduce serious throughput bottlenecks at scale.
MERGE INTO: Row-Level Upserts
The MERGE INTO SQL command is the feature most central to Delta Lake’s adoption for data integration workloads. Standard Spark writing operations could only append data or overwrite entire partitions. MERGE INTO enables row-level conditional write semantics: when a matched key exists in the target table, update or delete it; when no match exists, insert the new record.
This capability is essential for implementing Change Data Capture pipelines. When a Debezium CDC event stream delivers INSERT, UPDATE, and DELETE events from an operational database, the downstream pipeline uses MERGE INTO to apply these changes atomically to the Delta table. The result is a Delta table that continuously mirrors the exact current state of the source operational database.
Delta Lake’s MERGE INTO also supports non-trivial conditional logic: WHEN MATCHED AND source.event_type = 'DELETE' THEN DELETE, WHEN MATCHED AND source.status = 'UPDATED' THEN UPDATE SET *, and WHEN NOT MATCHED THEN INSERT *. This expressive conditional syntax allows complex CDC reconciliation and Type-2 Slowly Changing Dimension (SCD) patterns to be expressed in a single atomic SQL statement rather than multiple separate operations.
Delta Live Tables and Streaming
Delta Live Tables (DLT) is Databricks’ managed pipeline framework built on top of Delta Lake. It provides a declarative Python or SQL API for defining streaming data transformation pipelines where engineers specify the transformation logic and DLT manages the execution, monitoring, error recovery, and data quality enforcement automatically.
In a DLT pipeline, engineers define streaming tables using @dlt.table decorators and specify input data sources as streaming reads from Kafka, Kinesis, or raw Delta tables. DLT automatically handles incremental processing (reading only new data since the last pipeline run), schema enforcement (validating incoming data against declared schemas), and data quality quarantine (routing records that fail quality expectations to separate quarantine tables for review).
This managed approach significantly reduces the operational burden of building reliable streaming pipelines, automating the error handling and retry logic that engineers would otherwise have to build manually in raw Spark Structured Streaming code.
Delta Lake Versus Apache Iceberg
As the open table format landscape matured, Delta Lake and Apache Iceberg emerged as the two most widely deployed formats in enterprise environments. A critical architectural comparison between them reveals important trade-offs.
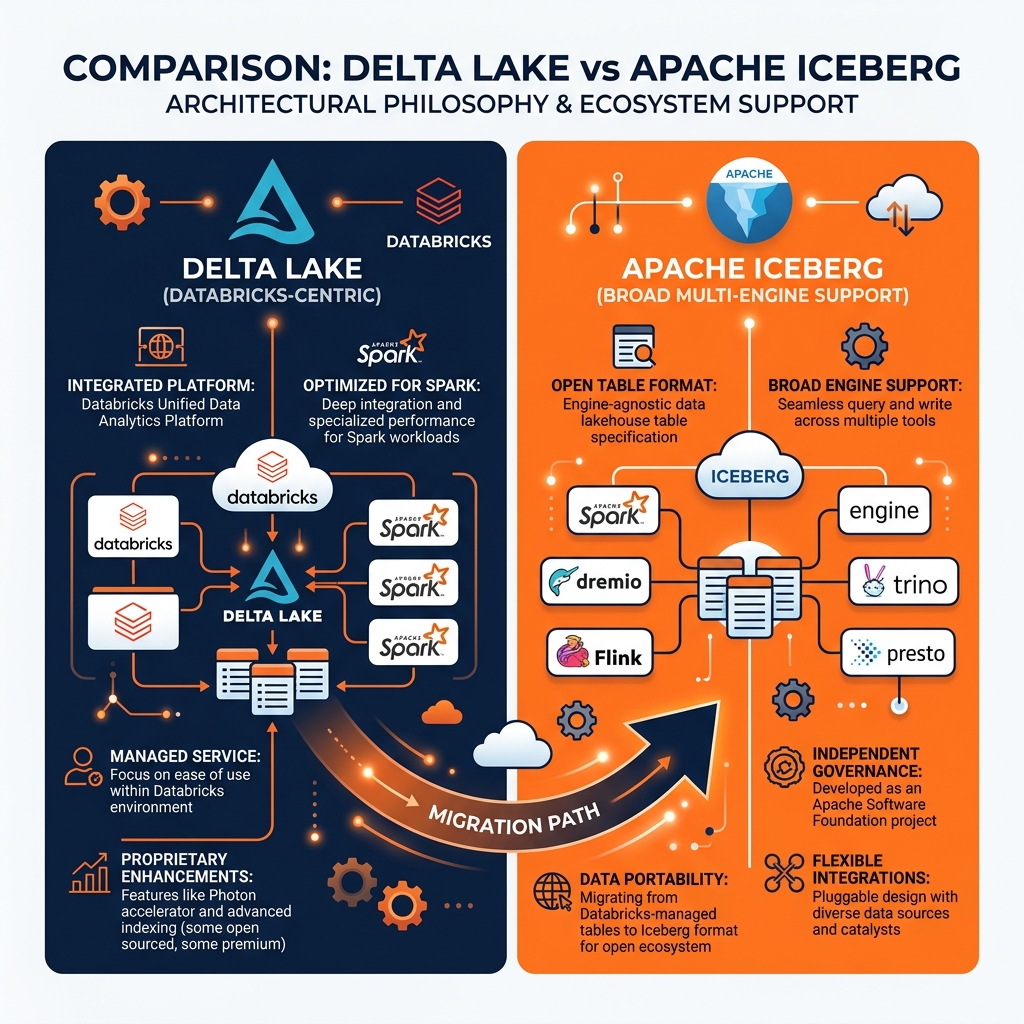
Catalog Integration: Apache Iceberg was designed from the start to be catalog-agnostic, with a formal Catalog API that allows any catalog implementation (Hive Metastore, AWS Glue, Apache Polaris, Project Nessie) to manage Iceberg table metadata. Delta Lake’s native catalog is the Databricks Unity Catalog, and while Delta tables can be registered in the Hive Metastore, the broader catalog ecosystem support is less extensive than Iceberg’s.
Engine Interoperability: Iceberg is natively supported by Apache Spark, Apache Flink, Dremio, Trino, StarRocks, ClickHouse, and dozens of other engines. Delta Lake has the widest native support in Spark (particularly in Databricks), with growing but still narrower support in other engines.
Metadata Scalability: Iceberg’s manifest-based metadata architecture scales more efficiently to tables with millions of data files than Delta Lake’s single transaction log directory. For very large tables, Iceberg’s manifest pruning is faster than Delta Lake’s log replay and checkpoint mechanism.
Open Standards: Iceberg is a fully open specification governed by the Apache Software Foundation, with no single corporate controller. Delta Lake is managed primarily by Databricks, though the core format specification is open source.
For most new lakehouse implementations starting fresh, Apache Iceberg provides superior engine interoperability and ecosystem neutrality. For organizations already invested in the Databricks ecosystem using Delta Live Tables and Unity Catalog, Delta Lake remains a strong, well-supported choice. The industry has seen significant activity around Delta Lake to Iceberg migration as enterprises seek to broaden their engine optionality beyond Spark and Databricks.
Delta Lake with Dremio
Dremio provides native read support for Delta Lake tables, allowing organizations with existing Delta Lake investments to query their Delta tables through Dremio’s Semantic Layer without migrating the data. Dremio reads the Delta transaction log to identify the current snapshot of the table and reads the relevant Parquet data files directly from object storage.
For organizations considering migrations from Delta Lake to Apache Iceberg, Dremio recommends using Apache Spark to execute the conversion. The migration process reads the Delta table using the Delta Lake connector, writes the output to a new Iceberg table using the Iceberg connector, and verifies the row counts and sample data match before switching downstream consumers to the new Iceberg table. The zero-downtime migration approach runs the two tables in parallel during the validation period, ensuring business continuity throughout the transition.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.