Write Amplification
A guide to write amplification, the hidden performance penalty in analytical databases and lakehouses where a small logical update results in massive physical data being rewritten on disk.
The Hidden Cost of Updates
Data lakehouses are built on cloud object storage (like Amazon S3 or Azure Data Lake) using columnar file formats like Apache Parquet. A fundamental characteristic of object storage is that files are immutable; once written, they cannot be modified. You cannot simply open a 1GB Parquet file, change the value of a single cell from “A” to “B”, and save it.
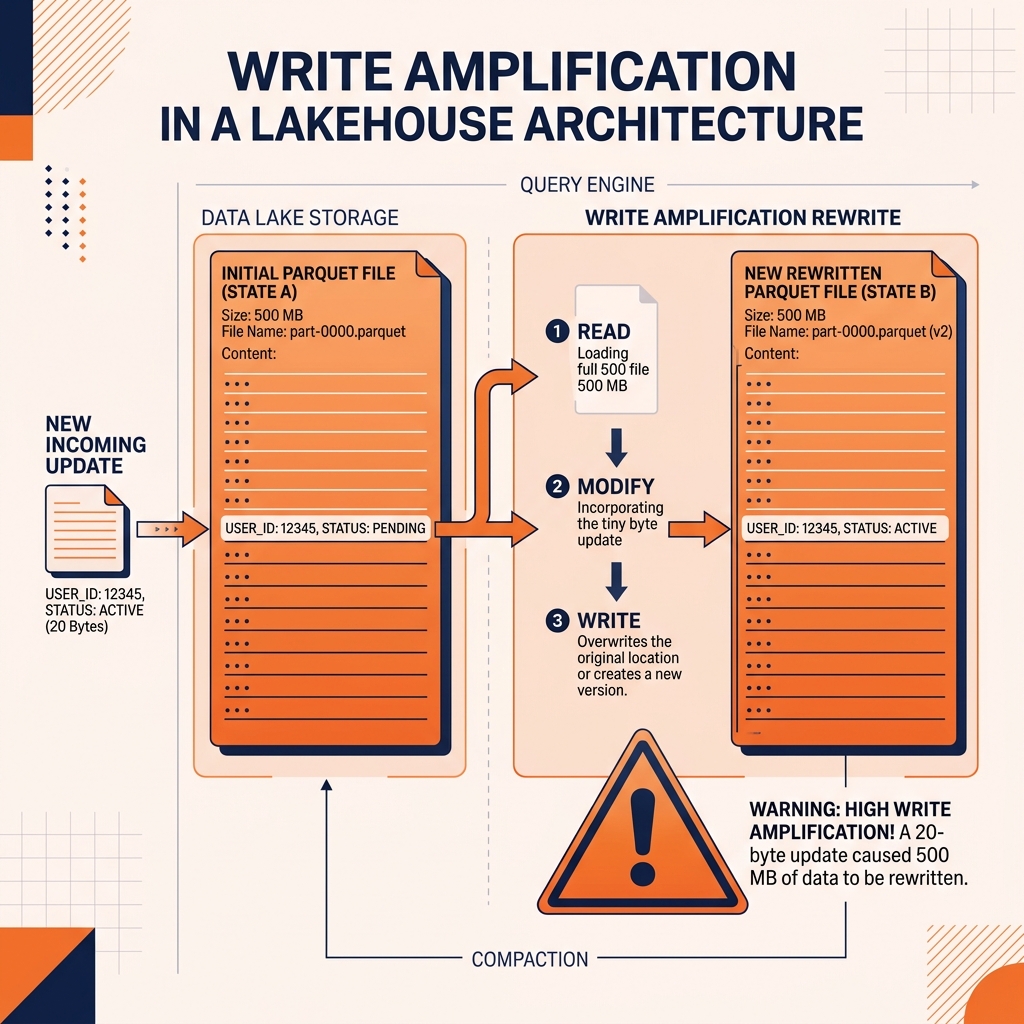
To update a single row, the entire file containing that row must be rewritten. This architectural reality creates a phenomenon known as Write Amplification.
Write amplification occurs when the amount of physical data written to the storage system is significantly larger than the logical amount of data being updated by the user. If an analyst runs a SQL command to UPDATE the email address of a single customer, and that customer’s record happens to reside inside a 500MB Parquet file, the query engine must download the entire 500MB file, update the single email address in memory, and upload a brand new 500MB Parquet file. A 20-byte logical update resulted in 500 Megabytes of physical write amplification.
The Copy-On-Write (COW) Penalty
The scenario described above is the default behavior of many data platforms, known as Copy-On-Write (COW). COW is excellent for read performance because the files are always perfectly contiguous and clean, meaning analytical engines like Dremio can scan them at maximum speed.
However, for workloads that require frequent updates (such as real-time Change Data Capture (CDC) streams or GDPR compliance deletions), the write amplification of COW becomes crippling. If a CDC stream updates 100 random rows across 100 different 500MB files every minute, the system is forced to rewrite 50 Gigabytes of data every minute just to apply a few kilobytes of updates, destroying pipeline performance and skyrocketing cloud compute costs.
Mitigating Amplification with Merge-On-Read (MOR)
Modern table formats like Apache Iceberg provide a solution to severe write amplification through the Merge-On-Read (MOR) strategy.
Instead of rewriting the massive data file when an update occurs, Iceberg writes a tiny “delete file” indicating which row was removed, and a new tiny data file containing the updated row. The massive original 500MB file is left untouched. This eliminates write amplification at ingestion time, allowing the CDC stream to process updates with millisecond latency.
The trade-off is shifted to the read side. When an analyst queries the table, the query engine must read the original massive file and manually reconcile it against the tiny delete files in memory before returning the result (hence, “Merge-On-Read”).
To prevent read performance from degrading over time, data engineers schedule background “Compaction” jobs during off-peak hours. Compaction takes the original files and the accumulated delete files and physically rewrites them into clean, new COW files, effectively paying the write amplification tax asynchronously when it won’t impact business operations.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.