Copy-on-Write (CoW)
A guide to the Copy-on-Write storage strategy in Apache Iceberg and Apache Hudi, where write operations rewrite entire data files to produce clean, merged snapshots optimized for read-heavy analytical workloads.
Designing for Read Performance
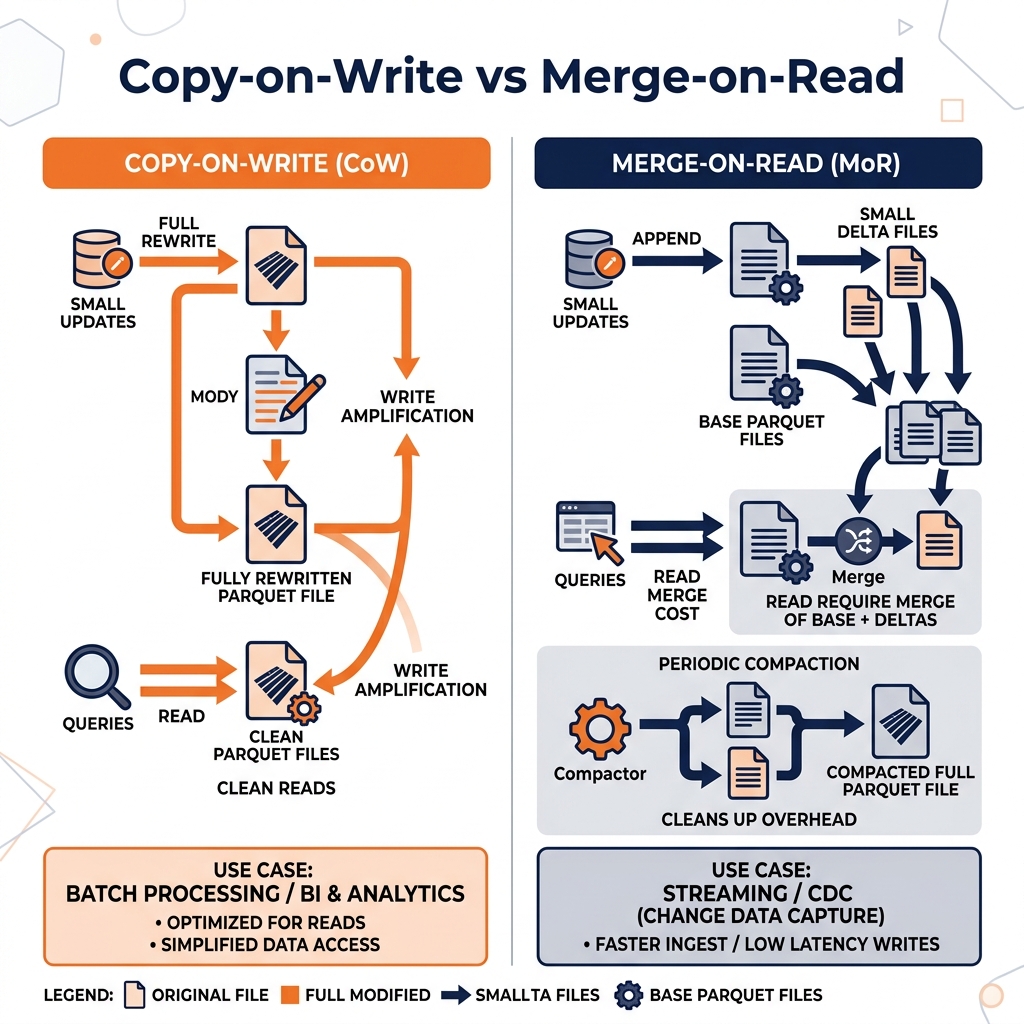
When an open table format processes a write operation that updates existing records, it faces a fundamental choice: update the data in place (modifying the existing file), write a separate delta record alongside the original file, or rewrite the original file entirely with the updates incorporated. Each strategy represents a different trade-off between write throughput and read performance.
Copy-on-Write (CoW) is the strategy that prioritizes read performance above all else. In CoW mode, any write operation that touches records in an existing data file triggers a full rewrite of that file. The old file is read entirely into memory, the updates are applied, and a new file is written to object storage containing the fully merged, current state of all records. The old file is then marked as obsolete and eventually cleaned up during maintenance operations.
The result of CoW writes is a storage layout where every data file contains exactly the current, fully merged state of the records it holds. No delta logs, no pending merges, no reconciliation required at read time. A query engine reading a CoW table reads the data files and gets the current truth directly, with no additional processing overhead beyond the standard Parquet scan.
Why CoW Tables Read Fast
The read performance advantage of CoW is structural. In a Merge-on-Read (MoR) table, a query engine must perform a merge operation at read time, combining base Parquet files with delta log files to reconstruct the current state of updated records. This merge adds computation cost to every read, proportional to the volume of pending deltas. For read-heavy BI workloads where hundreds of dashboards query the same tables many times per hour, this per-read merge cost accumulates significantly.
In a CoW table, there are no delta logs to merge. Every file is a complete, current snapshot of its records. Query engines read directly and return results with zero merge overhead. For workloads dominated by reads (analytics, BI, reporting), CoW delivers maximum read throughput and minimum query latency.
CoW tables also produce simpler, more predictable storage layouts that are easier to inspect, debug, and validate. Data engineers auditing a CoW table can examine any data file and know they are seeing the current state of those records without needing to understand the delta log reconciliation logic.
The Write Cost of CoW
The trade-off for CoW’s excellent read performance is high write amplification. Write amplification is the ratio of data written to storage relative to the actual volume of changed data. In a table with 1GB Parquet files, updating 100 records spread across ten different files requires reading all ten 1GB files (10GB of I/O) and writing ten new 1GB files (10GB of writes) to apply just 100 record changes. The write amplification factor is enormous relative to the actual data changed.
This write amplification is manageable for workloads with infrequent, large batch updates (daily or weekly ETL jobs that process large partitions). It becomes a serious problem for high-frequency small updates, such as CDC streams delivering individual record changes every few seconds. In those scenarios, CoW’s constant file rewriting creates excessive I/O and storage churn.
For streaming ingestion workloads with frequent small writes, Merge-on-Read is typically a better storage strategy choice. CoW’s write overhead is acceptable for batch-dominated pipelines where writes are infrequent and reads are extremely frequent.
CoW in Apache Iceberg
Apache Iceberg implements CoW as its default write behavior for INSERT OVERWRITE and MERGE INTO operations. When a MERGE INTO statement is executed against an Iceberg table in CoW mode, Iceberg identifies all data files containing records that match the MERGE condition, rewrites those files with the updates applied, and commits the new file set as a new snapshot. Files that were not touched by the MERGE are referenced unchanged from the new snapshot.
Iceberg also supports configuring write behavior at the table level through table properties. The write.delete.mode, write.update.mode, and write.merge.mode properties can each be set to either copy-on-write or merge-on-read independently, providing fine-grained control over the write strategy for each DML operation type.
Dremio uses CoW semantics for its Data Reflection maintenance operations, always producing clean, fully merged Reflection files that deliver optimal read performance for governed analytical queries through the Semantic Layer.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.