Merge-on-Read (MoR)
A guide to the Merge-on-Read storage strategy in Apache Iceberg and Apache Hudi, where write operations append delta records for low write latency, with merging deferred to read time or compaction.
Designing for Write Throughput
Merge-on-Read (MoR) is the storage strategy that prioritizes write throughput over read-time simplicity. Rather than rewriting entire data files when records are updated or deleted, MoR writes only the changed records as small delta files alongside the original base files. The base Parquet files are left untouched. The merge operation that produces the current view of the data is deferred to read time (or to a separate compaction job), allowing writes to complete with minimal I/O overhead.
The fundamental distinction from Copy-on-Write (CoW) is the direction of the trade-off. CoW writes are expensive (full file rewrites) but reads are cheap (clean, merged files). MoR writes are cheap (append-only delta records) but reads are more expensive (merge base files with delta at query time). Choosing between CoW and MoR depends on the write frequency and read volume characteristics of the specific workload.
How MoR Writes Work
In MoR mode, when a MERGE INTO or UPDATE statement is executed against an Iceberg table, the changed records are written to small delete files (recording the positions or keys of deleted/updated records) and small insert files (recording the new versions of updated records). The original base Parquet files containing the old versions of those records are not touched.
The metadata layer records the association between base files and their delta files. A query reading an MoR table must consult this metadata to find all delta files associated with each base file and apply the merge operation to produce the current record state. This merge is performed by the query engine at read time, reading both the base file and any associated delta files and producing a merged result set.
This approach dramatically reduces write I/O. Updating 100 records in a 1GB Parquet file requires writing only a small delete file (recording 100 row positions) and a small insert file (recording 100 updated record versions), not a full rewrite of the 1GB file. The write amplification factor is close to 1:1 rather than the enormous ratios associated with CoW.
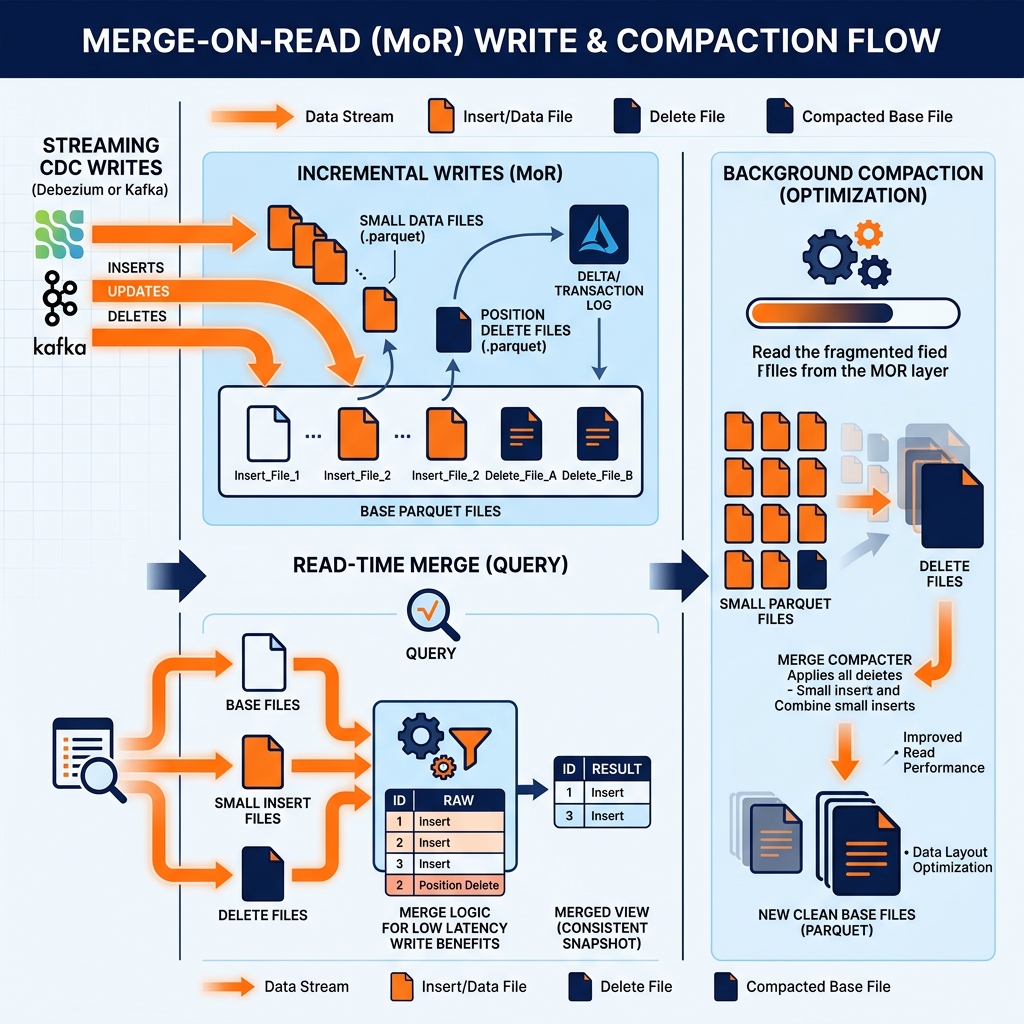
The Read Cost of MoR
The deferred merge cost at read time is MoR’s primary trade-off. For workloads with many recent updates and many pending delta files, each query must perform increasing amounts of merge work. A table that has accumulated 1,000 delta files since the last compaction requires the query engine to read and merge those 1,000 files in addition to the base files for every query, adding latency proportional to the delta file accumulation.
This growing read overhead is managed through compaction: a periodic background process that reads the base files and their associated delta files, merges them into new, clean base files, and discards the old base and delta files. After compaction, the table returns to the clean-read performance of a CoW table for the compacted data. The compaction process is itself an expensive operation (reading all the affected data and rewriting it), similar to a CoW write, but it runs in the background and only periodically rather than on every write.
The balance between write frequency, compaction frequency, and read performance requirements determines the optimal MoR configuration for a given workload. High-frequency streaming ingestion workloads typically configure compaction to run every few hours on a dedicated Spark or Flink job, keeping the delta file accumulation bounded and read performance acceptable.
MoR in Apache Iceberg
Iceberg supports MoR through its position delete files and equality delete files. Position delete files record the specific row positions within a base file that have been logically deleted. Equality delete files record the key values of records that should be treated as deleted, allowing the query engine to filter them out without knowing their physical positions. UPDATE operations in MoR mode write both a position or equality delete file (for the old version) and a new data file (for the new version).
Iceberg table properties write.delete.mode = merge-on-read, write.update.mode = merge-on-read, and write.merge.mode = merge-on-read enable MoR for specific DML operation types. Dremio supports reading MoR Iceberg tables, applying the delta merge logic automatically during query planning so that analysts always see the current merged state of the data through the Semantic Layer.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.