Query Federation
A guide to query federation in data engineering, the architecture pattern that enables a single SQL query to join and aggregate data from multiple heterogeneous data sources without moving the data into a central system first.
Query Without Moving Data
The traditional approach to integrating data from multiple source systems into a unified analytical view is to move all the data into a central data warehouse. Extract data from the operational database into the warehouse. Extract data from the SaaS platform into the warehouse. Extract data from the partner data feed into the warehouse. Once all the data is in the warehouse, analysts can join and aggregate it freely.
This data movement approach has fundamental problems. It is expensive: every byte of data must be extracted, transferred, stored again in the warehouse, and kept synchronized as source data changes. It is slow: pipelines introduce latency between when data changes in the source and when the changed data is available in the warehouse, ranging from minutes for near-real-time pipelines to hours or days for batch pipelines. It creates redundancy: the same data exists in both the source system and the warehouse, requiring synchronization and creating potential inconsistency. And it may be prohibited: data sovereignty regulations, contractual data sharing restrictions, or security policies may prohibit moving certain data outside its source system.
Query federation is the alternative architecture: rather than moving data to a central system, move the query to where the data already lives. A federated query engine sends query fragments (sub-queries) to each source system, retrieves the intermediate results, and assembles the final joined and aggregated result set, all without copying any source data into a central repository.
How Federated Query Execution Works
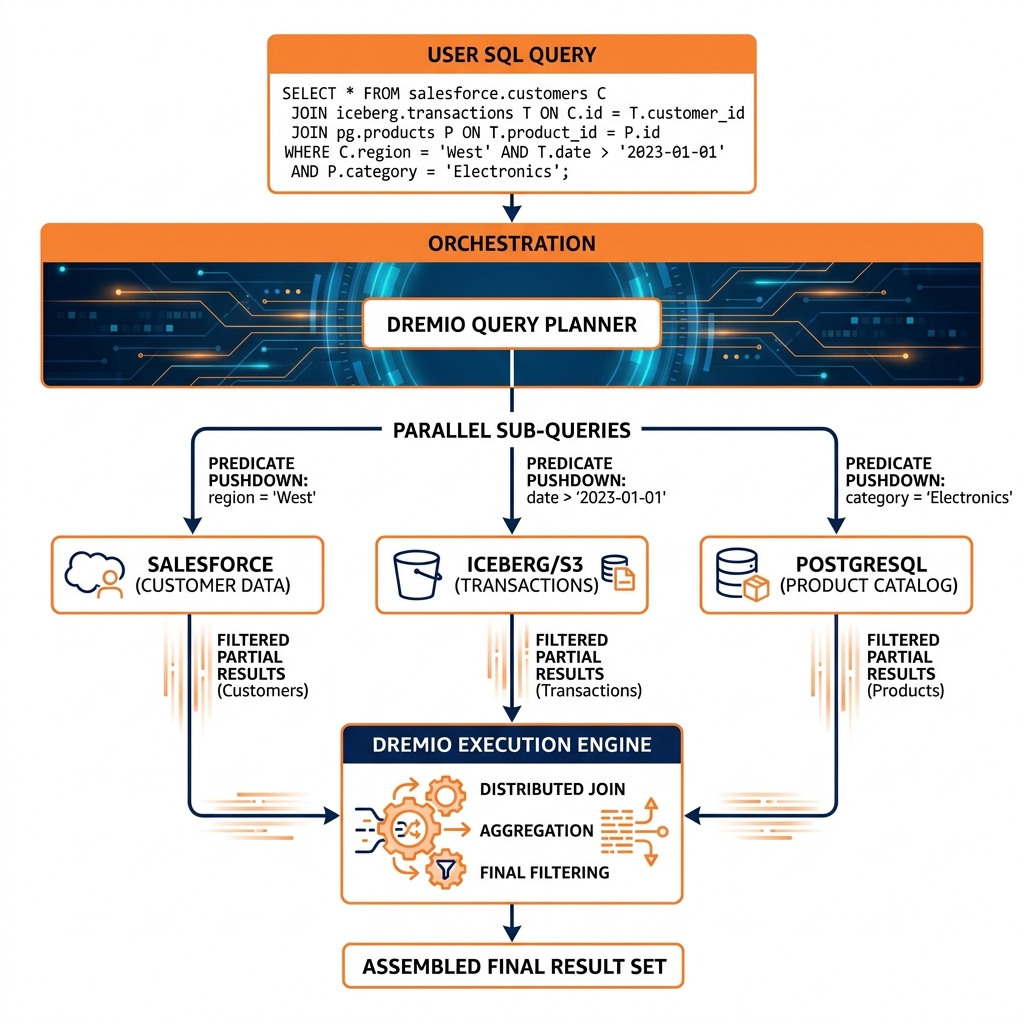
A federated query engine like Dremio or Trino maintains connectors for each supported data source. When a federated SQL query references tables from multiple sources, the query planner analyzes the query and decomposes it into source-specific sub-queries that each source system can execute natively.
For a query joining a customer table (in Salesforce, via the Salesforce connector) with a transaction table (in an Iceberg lakehouse) and a product catalog (in PostgreSQL), the federated planner generates: a SQL fragment pushed to Salesforce to retrieve the relevant customer fields with applicable filters; a Parquet/Iceberg scan for the transaction data with partition pruning applied; and a SQL fragment pushed to PostgreSQL for the product catalog data. The results of these three parallel sub-queries are streamed back to the federated engine, which performs the final join, aggregation, and projection to produce the query result.
The key performance optimization in federated query execution is predicate pushdown: filters, projections, and aggregations that can be expressed in each source system’s native query language are pushed down to be executed by that source, returning only the relevant data to the federated engine. If only customers from the ‘Enterprise’ segment are needed, the WHERE segment = 'Enterprise' filter is pushed to Salesforce, returning only enterprise customers rather than all customers.
Dremio’s Federation Architecture
Dremio is one of the most capable federated query platforms in the data engineering ecosystem. Dremio supports native connectors for hundreds of data sources: Apache Iceberg catalogs (Polaris, Nessie, HMS, Glue), object storage files (Parquet, ORC, Avro, CSV, JSON), relational databases (PostgreSQL, MySQL, Oracle, SQL Server, Redshift, Snowflake, BigQuery), NoSQL systems (MongoDB, Elasticsearch), SaaS platforms (Salesforce, HubSpot), and more.
Unlike generic federated query engines that treat all source data as opaque, Dremio’s connectors include source-specific optimization logic: pushing SQL predicates down to relational sources in their native SQL dialect, applying partition pruning for Iceberg sources, using pushdown aggregations to reduce data transfer from high-cardinality sources, and applying Dremio’s Data Reflections (pre-computed materializations) to accelerate repeated federated query patterns.
Dremio’s Semantic Layer adds governance to federation: Virtual Datasets that join data from multiple sources are governed by Dremio’s RBAC and column masking policies, ensuring that federated access to sensitive data across source systems is subject to the same governance controls as access to managed Iceberg tables.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.