Data Sharing
A guide to open data sharing in the lakehouse ecosystem, the patterns and protocols that enable organizations to share Iceberg tables with external partners without data movement, duplication, or proprietary format lock-in.
Sharing Data Without Moving It
Enterprise data collaboration historically required physically copying data to share it. A financial institution sharing transaction data with a risk analytics partner would extract a dataset, encrypt it, and transfer it via SFTP. The partner would ingest it into their own warehouse, creating a stale copy that diverged from the source the moment it was transferred. Updates required another full extraction and transfer cycle. Data governance was impossible to maintain across the copy boundary.
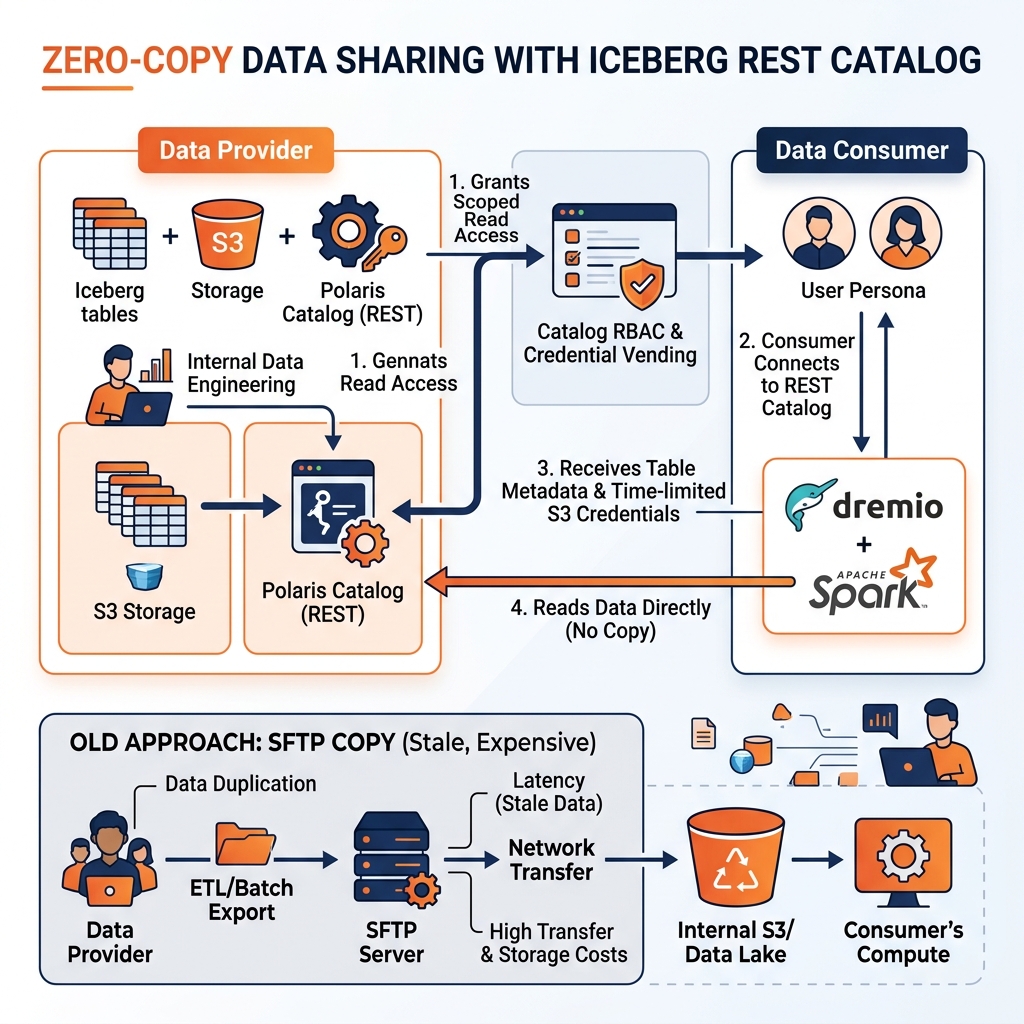
The modern data sharing paradigm leverages the separation of storage and compute in the lakehouse architecture to enable direct data access without physical data movement. If both the data provider and the data consumer use cloud object storage (S3, ADLS, GCS) and the Iceberg table format, the provider can grant the consumer scoped read access to the Iceberg metadata and data files in the provider’s object storage. The consumer queries the data directly from the provider’s storage using their own compute engine, accessing the live current version of the data without any copy or transfer.
This direct-access sharing model, sometimes called zero-copy data sharing, provides several advantages over copy-based sharing. Data is always current: the consumer sees the same version of the data as the provider’s internal users, updated in real time as new snapshots are committed. No storage duplication costs are incurred. Data governance policies (access control, usage auditing) remain under the provider’s control. When sharing is revoked, the consumer immediately loses access to all data, including historical copies.
Iceberg REST Catalog Data Sharing
The Apache Iceberg REST Catalog specification enables a standardized data sharing protocol. A data provider configures their Iceberg catalog (Polaris, AWS Glue, or a custom implementation) to expose specific tables through a REST Catalog endpoint accessible to external consumers. The provider configures RBAC policies that grant the consumer’s identity read access to the shared tables and configures credential vending to provide the consumer with scoped, time-limited S3 credentials for the specific S3 prefixes containing the shared table’s data files.
The consumer configures their compute engine (Spark, Dremio, Trino, DuckDB) to connect to the provider’s REST Catalog endpoint using the provided credentials. From the consumer’s perspective, the shared tables appear as native catalog entries they can query with SQL. No proprietary sharing protocol, no data movement, no format conversion.
Delta Sharing
Delta Sharing (developed by Databricks and donated to the Linux Foundation) is a protocol for sharing Delta Lake and Parquet data across organizations. The Delta Sharing protocol defines a REST API for discovering shared datasets and retrieving pre-signed URLs to access the underlying Parquet files for a specific snapshot. Clients (Delta Sharing clients for Python, Spark, Pandas) retrieve the pre-signed URLs and read the Parquet data directly.
Delta Sharing differs from Iceberg REST Catalog sharing in that it is a read-only, snapshot-based protocol without full ACID catalog semantics. Iceberg REST Catalog sharing provides richer semantics (time travel, schema evolution history, full ACID read consistency) but requires the consumer to have an Iceberg-compatible engine. Delta Sharing provides broader client compatibility (Python clients, Pandas, Power BI) but with simpler snapshot-based semantics.
For organizations building on Dremio and the Iceberg ecosystem, Iceberg REST Catalog-based sharing through Apache Polaris is the architecturally consistent choice, providing governed data sharing with full Iceberg semantics and Dremio’s native credential vending integration.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.