Schema Evolution
A guide to schema evolution, the critical capability of modern data platforms to safely alter the structure of a database table (adding, dropping, or renaming columns) without breaking existing data or pipelines.
Adapting to Change
Data is not static; it constantly evolves to reflect the changing reality of a business. When a company launches a new product, they might start collecting a new metric (like shipping_weight). If a privacy law passes, they might suddenly need to delete a column containing user phone numbers.
In traditional relational databases, changing the structure of a massive table (a process known as an ALTER TABLE statement) was historically a terrifying, blocking operation. To add a single column to a 10-terabyte table, the database often had to lock the entire table, physically rewrite every single row on the hard drive to include the new empty column, and keep the application offline for hours.
Schema evolution is the modern architectural solution to this problem. It allows data engineers to seamlessly and safely alter the structure (the schema) of massive datasets instantaneously, without rewriting historical files and without taking the system offline.
Safe vs. Unsafe Evolution
Schema changes generally fall into two categories:
Safe (Backward Compatible) Changes:
Adding a new optional column. Old data doesn’t have it, but queries won’t break; they just return NULL for the old rows.
Unsafe (Breaking) Changes:
Renaming a column, dropping a column, or changing the data type (e.g., from INTEGER to STRING). If an old downstream dashboard expects a column named revenue_usd and you rename it to sales_dollars, the dashboard will crash instantly.
Schema Evolution in the Lakehouse (Iceberg)
Managing schema evolution in a data lake composed of raw Parquet files on S3 was historically impossible. If you added a column, you broke the downstream Spark jobs.
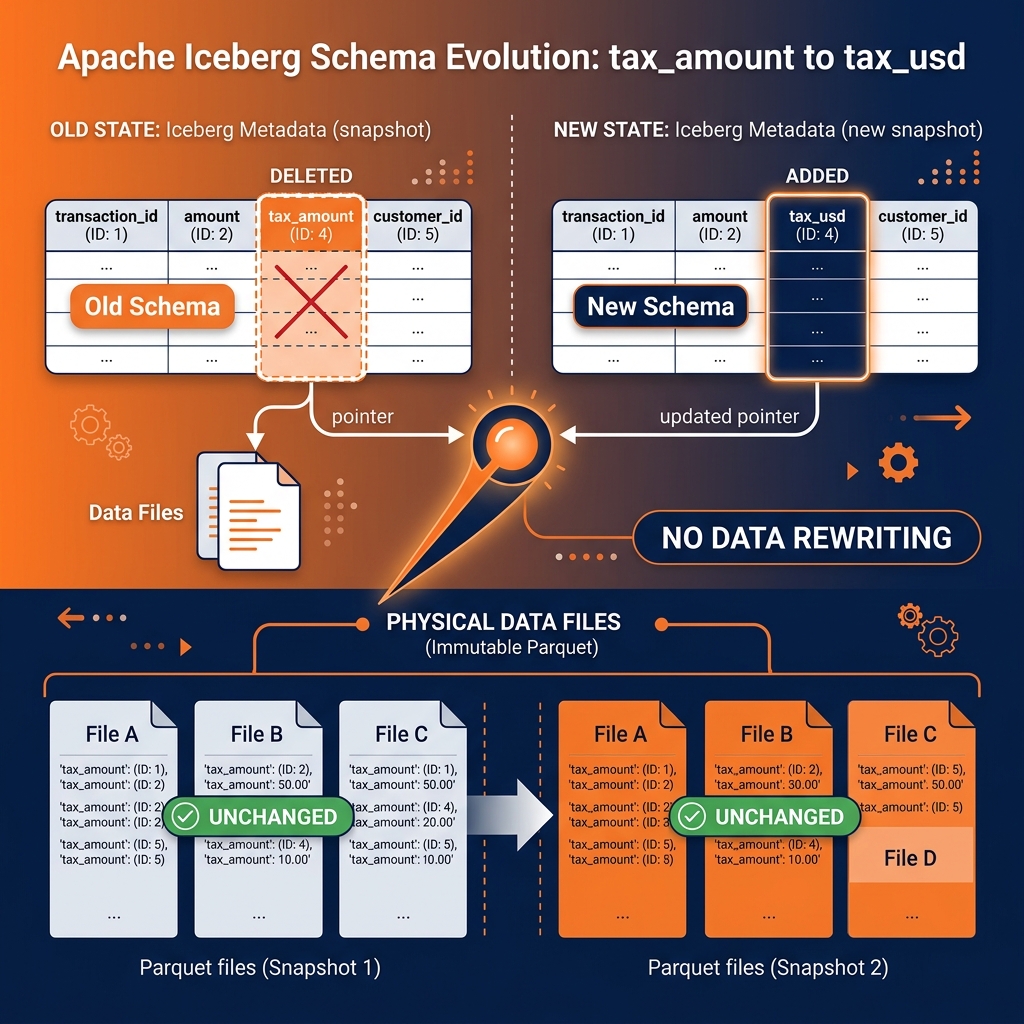
Apache Iceberg solved this by introducing First-Class Schema Evolution. Iceberg does not track columns by their names; it tracks them by immutable internal IDs.
If you have a column named tax_amount (Internal ID: 4), and you rename it to tax_usd, Iceberg simply updates its metadata file to say, “ID 4 is now called tax_usd.” It does not touch the terabytes of historical Parquet files on S3.
When a query engine like Dremio reads the old Parquet files, it looks at ID 4 and projects it as tax_usd. You can drop columns, rename them, or even add a new column, drop it, and add a completely different column with the same name later-Iceberg handles it all perfectly through metadata pointers without ever risking data corruption or requiring a full rewrite of the historical data.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.