AWS Glue Data Catalog
A guide to AWS Glue Data Catalog, the fully managed, serverless metadata repository that serves as the central catalog for AWS analytics services and provides an HMS-compatible API for Apache Iceberg and Hive-compatible tables.
Managed Metadata on AWS
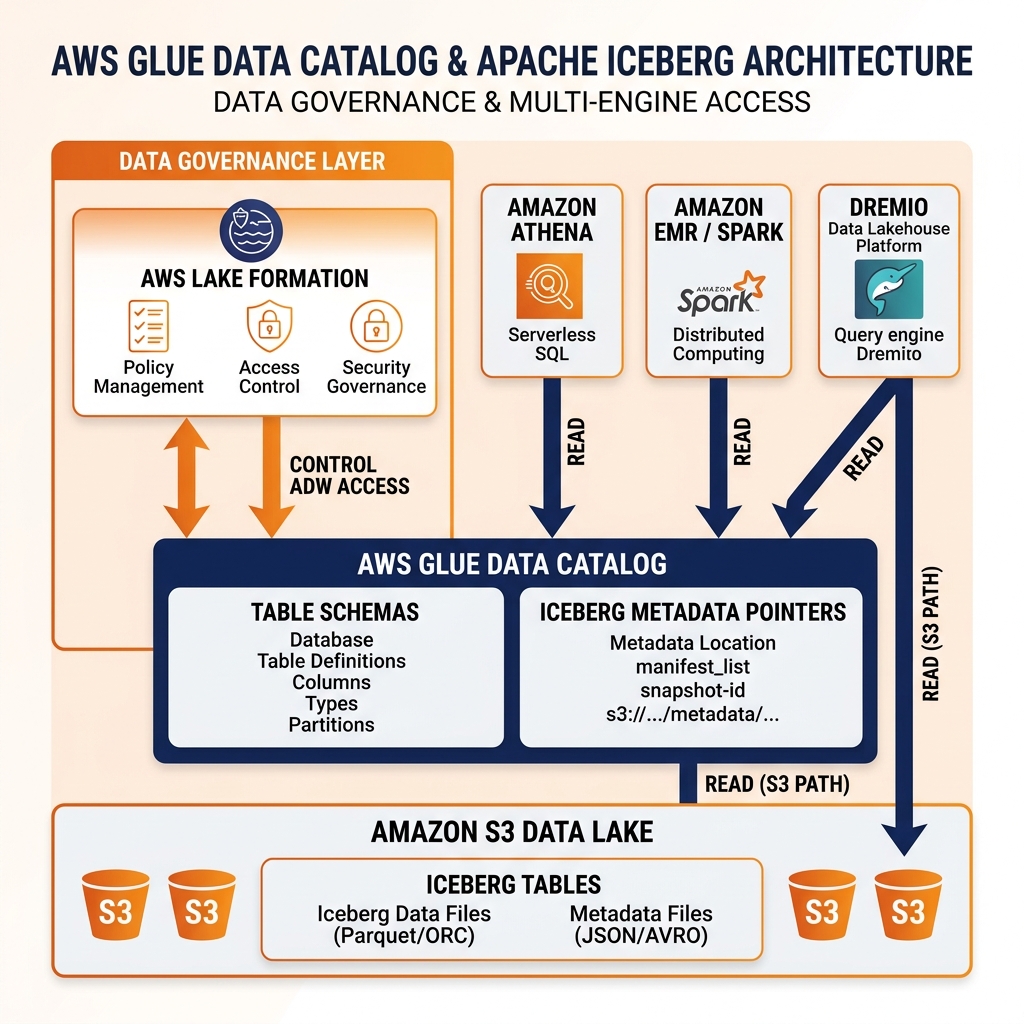
AWS Glue Data Catalog is Amazon Web Services’ fully managed, serverless metadata repository. Unlike the Hive Metastore (HMS), which requires deploying and operating a relational database and HiveServer2 process, the Glue Data Catalog is a cloud-native service that requires zero infrastructure management. Databases, tables, and partitions are stored in Glue and accessed through the Glue API or through the HMS-compatible Thrift API that Glue exposes for backward compatibility with tools built against HMS.
The Glue Data Catalog serves as the default metadata catalog for most AWS analytics services. AWS Athena queries tables registered in Glue without any additional configuration. AWS EMR (managed Hadoop/Spark clusters) uses Glue as its Hive Metastore by default when configured for Glue integration. AWS Lake Formation uses Glue as the underlying metadata repository while adding its own governance and access control layer on top.
For AWS-native data lakehouse implementations, Glue provides a convenient, low-friction catalog option that eliminates the operational overhead of managing HMS while maintaining broad compatibility with the Hadoop and Spark ecosystems.
Glue as an Iceberg Catalog
AWS Glue supports Apache Iceberg tables natively through the Iceberg format in the Glue catalog. When an Iceberg table is created in Glue, Glue stores the table’s metadata in its catalog and tracks the current Iceberg metadata file location, analogous to the HMS Iceberg catalog approach. Query engines (Spark on EMR, Athena, Dremio) can discover and read Iceberg tables registered in Glue through the standard Iceberg Glue catalog connector.
Glue’s Iceberg catalog integration supports Iceberg’s atomic table operations. Glue uses optimistic concurrency control to manage concurrent writes to the same Iceberg table, using Glue’s conditional update semantics to ensure that only one writer can advance the current metadata pointer at a time, preventing concurrent write corruption.
AWS Athena v3 provides native Iceberg table support through Glue, allowing analysts to run Iceberg DML (INSERT, MERGE, DELETE, UPDATE) statements through Athena’s serverless SQL interface against Iceberg tables stored in S3 and registered in Glue. This Athena+Glue+Iceberg+S3 combination represents the most accessible entry point for AWS organizations building their first Iceberg-based lakehouse.
AWS Lake Formation and Glue
AWS Lake Formation sits above Glue as an additional governance and access control layer. Lake Formation implements column-level and row-level security policies for tables registered in Glue, enforcing these policies for queries executed through Athena and EMR. When a user queries an Athena table governed by Lake Formation, Lake Formation intercepts the query, applies the applicable access policies, and returns only the columns and rows the user is authorized to see.
Lake Formation’s access control model is coarser than Apache Polaris’s RBAC with credential vending. Lake Formation operates at the query execution layer (filtering results) rather than at the storage layer (controlling which storage credentials are vended), which means that users with direct S3 access can potentially bypass Lake Formation policies by querying the Parquet files directly. Polaris’s credential vending model prevents this bypass because engines receive only the scoped credentials that Polaris authorizes.
Dremio and AWS Glue
Dremio integrates natively with AWS Glue Data Catalog as a metadata source. When Glue is configured as a Dremio source, Dremio reads table metadata (schema, partition information, Iceberg metadata file locations) from Glue and uses that metadata to plan and execute queries against the corresponding data files in S3. Dremio’s Semantic Layer and Data Reflections operate on top of Glue-registered tables exactly as they do on Polaris-managed tables, providing governed query access and performance acceleration regardless of the underlying catalog.
Organizations using Glue as their primary AWS catalog can use Dremio as the unified query and governance layer, accessing both Glue-managed Iceberg tables and other data sources (operational databases, Kafka streams, other object storage locations) through a single SQL interface with consistent governance policies.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.