Snowflake Schema
A guide to the snowflake schema, a dimensional modeling technique where dimension tables are normalized into multiple related tables, trading query simplicity for storage efficiency and data integrity.
Normalization in the Data Warehouse
In data warehousing and dimensional modeling, the Star Schema is the gold standard for analytical performance and simplicity. In a star schema, dimension tables are highly denormalized: all attributes related to a product (brand, category, department) are stored in a single, wide dim_product table, even if it results in redundant data (the word “Electronics” repeated a million times for a million different products).
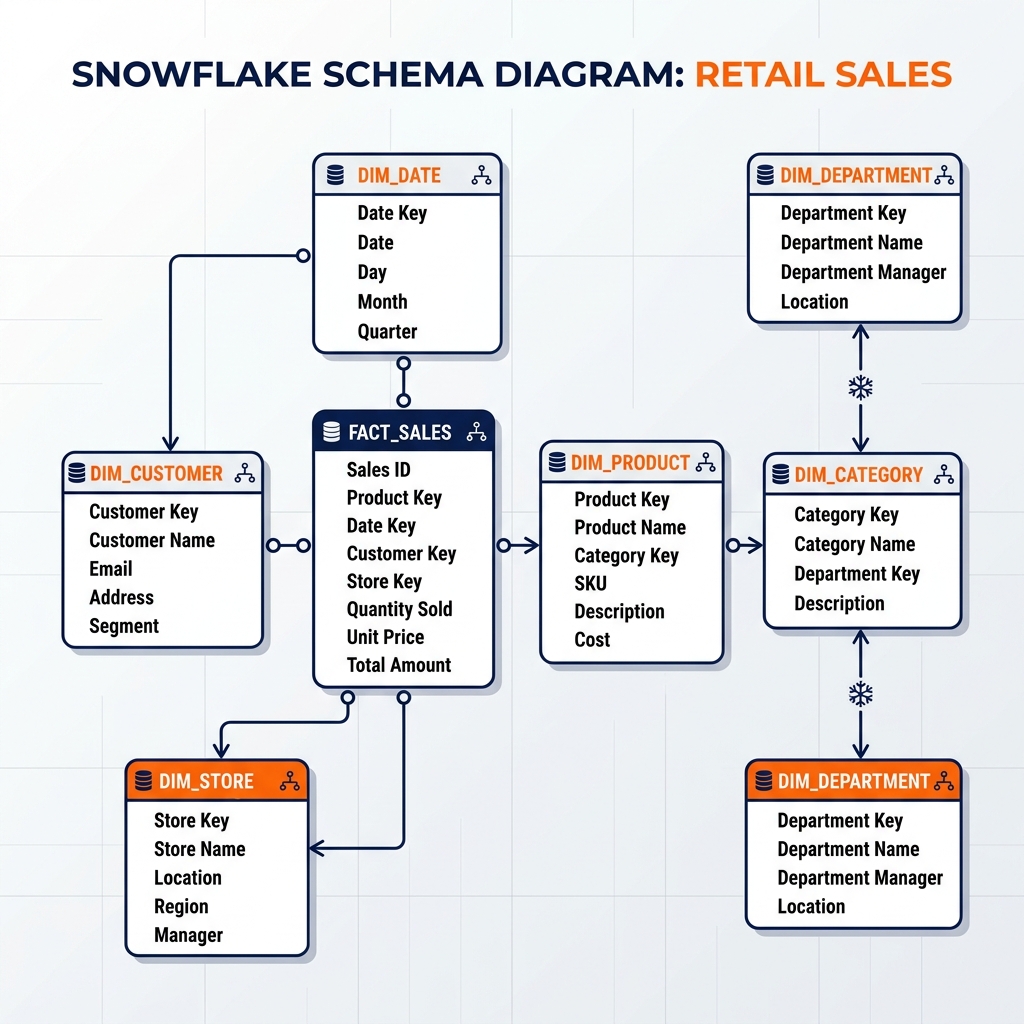
The Snowflake Schema is an alternative architectural pattern where the dimension tables are normalized. Instead of a single wide dim_product table, the schema branches out: a dim_product table joins to a dim_category table, which joins to a dim_department table. Visually, the ERD (Entity-Relationship Diagram) resembles a snowflake, with the central fact table branching out into multiple layers of dimension tables.
Why Use a Snowflake Schema?
Storage Efficiency: The primary historical motivation for snowflaking was saving disk space. Storing the string “Home Appliances” once in a dim_department table (referenced by an integer ID) uses significantly less space than repeating it a million times in a denormalized product table.
Data Integrity and Maintenance: Updating a department name is easier in a snowflake schema. You update a single row in the dim_department table. In a star schema, you must run an UPDATE statement that modifies a million rows in the dim_product table, which is computationally expensive in an analytical database.
Hierarchical Data Modeling: Snowflake schemas naturally represent hierarchical relationships (City -> State -> Country) which can make certain types of complex ETL processing cleaner to manage in the pipeline logic.
The Lakehouse Reality: Favoring Star Schemas
While the Snowflake schema has theoretical benefits, modern data architecture generally discourages its use in favor of heavily denormalized Star Schemas.
The Death of Storage Costs: Storage efficiency is no longer a valid motivation for snowflaking. Cloud object storage (S3/ADLS) is incredibly cheap. More importantly, columnar storage formats like Apache Parquet (used by Iceberg) use dictionary encoding. Parquet already stores repeating strings like “Home Appliances” only once in a dictionary and references them via tiny integers under the hood. Parquet provides the storage efficiency of a snowflake schema automatically, even when the logical table is a wide, denormalized star schema.
Join Complexity: Analytical query engines hate JOIN operations. A query in a snowflake schema might require five or six joins just to connect the fact table to the relevant dimensional attribute. This destroys query performance and makes the SQL incredibly difficult for business analysts to write and understand.
In a modern Iceberg lakehouse accessed via Dremio, data engineers should strive to deliver highly denormalized Star Schemas to the presentation layer. If data arrives from source systems in a normalized (snowflake) structure, the dbt transformation pipeline should join and flatten those tables in the Silver layer, producing wide, user-friendly dim_* tables in the Gold layer that minimize query-time joins and maximize self-service usability.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.