Hive Metastore (HMS)
A guide to the Hive Metastore, the foundational metadata catalog of the Hadoop ecosystem that tracks table schemas, partitions, and storage locations, and its evolving role in modern Iceberg lakehouses.
The Original Enterprise Data Catalog
The Hive Metastore (HMS) is one of the most widely deployed metadata systems in enterprise data engineering, not because organizations consciously chose it as their metadata strategy, but because it was bundled with Apache Hive and became the de facto metadata layer for the entire Hadoop ecosystem. Every major Hadoop distribution (Cloudera CDH, Hortonworks HDP) deployed HMS as part of its standard stack, and the ecosystem of tools (Spark, Presto, Impala) built HMS integration as a first-class concern because it was the only catalog game in town.
HMS is a relational database (typically MySQL or PostgreSQL) that stores metadata about Hive-compatible tables, databases, partitions, columns, storage formats, and SerDe (serialization/deserialization) configurations. When a Hive query references a table, it first contacts the HMS to retrieve the table’s location (HDFS path), schema, and partition information, then uses that metadata to plan and execute the query.
The HMS schema has remained largely stable since its introduction in the early Hadoop era, which is both its greatest strength (broad ecosystem compatibility) and its greatest weakness (limited extensibility for modern table format requirements). The original HMS was designed around Hive’s partition-directory model, where each partition maps to a specific directory path in HDFS. This partition-directory coupling is fundamentally incompatible with modern open table formats like Apache Iceberg, which manage file-level metadata through their own metadata layers independent of the directory structure.
HMS as an Iceberg Catalog
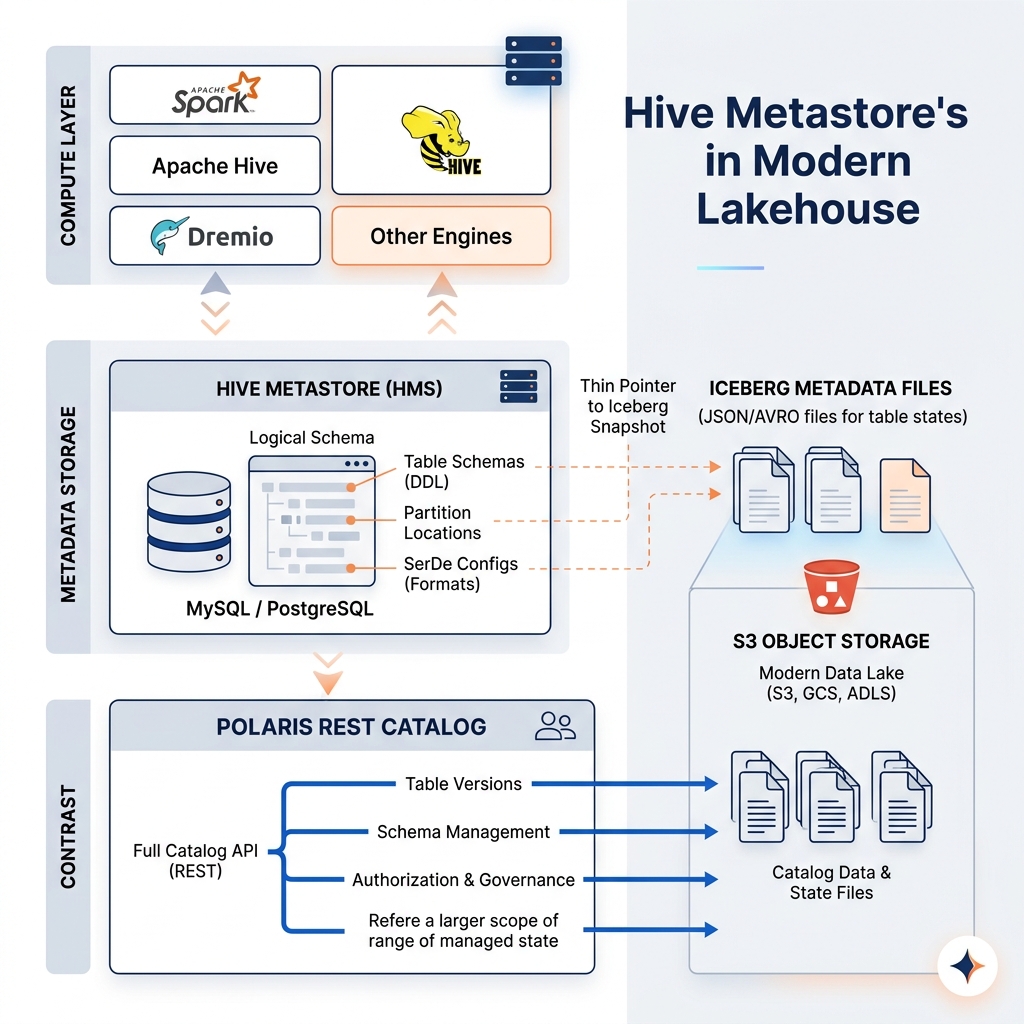
Despite its architectural age, HMS remains a viable catalog for Apache Iceberg tables through the Iceberg Hive catalog implementation. Rather than storing Iceberg’s rich metadata in the HMS tables (which were not designed for it), the Iceberg Hive catalog stores only the path to the current Iceberg metadata file for each table in an HMS table property. The full Iceberg metadata (snapshots, manifests, file statistics) is stored in the Iceberg metadata files on object storage as usual.
This “thin catalog” approach allows Iceberg tables to be registered in HMS and discovered by HMS-compatible query engines (Spark, Flink, Hive, Dremio) while maintaining the full Iceberg metadata on object storage. The HMS becomes a discovery mechanism (telling engines where to find the Iceberg metadata file) rather than the metadata system itself.
The limitation of using HMS as an Iceberg catalog is atomic multi-table operations. HMS does not support multi-object atomic updates, meaning operations that need to atomically update the metadata of multiple tables simultaneously (such as a two-table swap or a transactional multi-table write) cannot be expressed as a single atomic HMS transaction. Modern Iceberg-native catalogs like Apache Polaris and Project Nessie provide proper multi-table atomicity that HMS cannot.
HMS in the Modern Lakehouse
Many enterprises have invested heavily in HMS-based infrastructure: established partition schemes, mature backup procedures, tooling built around HMS APIs, and years of operational experience. For these organizations, migrating away from HMS entirely is a significant undertaking that requires careful planning and staged execution.
AWS Glue Data Catalog provides an HMS-compatible API surface, allowing organizations to use Glue as a managed, serverless drop-in replacement for a self-hosted HMS. This migration path preserves compatibility with all existing HMS-dependent tools while eliminating the operational burden of managing the HMS relational database and HiveServer2 processes.
For organizations building new lakehouse implementations, Apache Polaris or Project Nessie provide a more appropriate foundation than HMS. Both offer proper Iceberg REST Catalog semantics, multi-table atomicity, RBAC-based access control, and credential vending that HMS cannot provide. Dremio supports connecting to HMS as a metadata source, reading Iceberg tables registered in HMS through the Hive catalog path while applying Dremio’s own governance and performance optimization layer on top.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.