Data Products
A guide to data products, the foundational concept of the Data Mesh architecture that treats data as a product with defined owners, SLAs, discoverability, and quality standards rather than as a pipeline output.
From Pipeline Outputs to Data Products
In traditional centralized data architectures, data is a byproduct of pipelines. The data engineering team builds ETL jobs that extract data from source systems, transform it, and load it into tables in the data warehouse. These tables are consumed by analysts and BI tools. When the tables have quality issues, are late, or have confusing semantics, analysts must trace the problem back through the pipeline to the source, often involving the data engineering team in debugging sessions. The data’s quality, freshness, and semantic clarity are not governed by a defined owner; they are emergent properties of a pipeline that no one is fully accountable for.
Data products represent a fundamental philosophical shift. A data product is a discrete, independently deployable data asset that is designed, built, maintained, and owned by a specific domain team (the product team) and served to consumers with defined quality guarantees. The word “product” is intentional: just as a software product has an owner, a roadmap, SLAs, documentation, and versioned releases, a data product has all of these properties applied to a data asset.
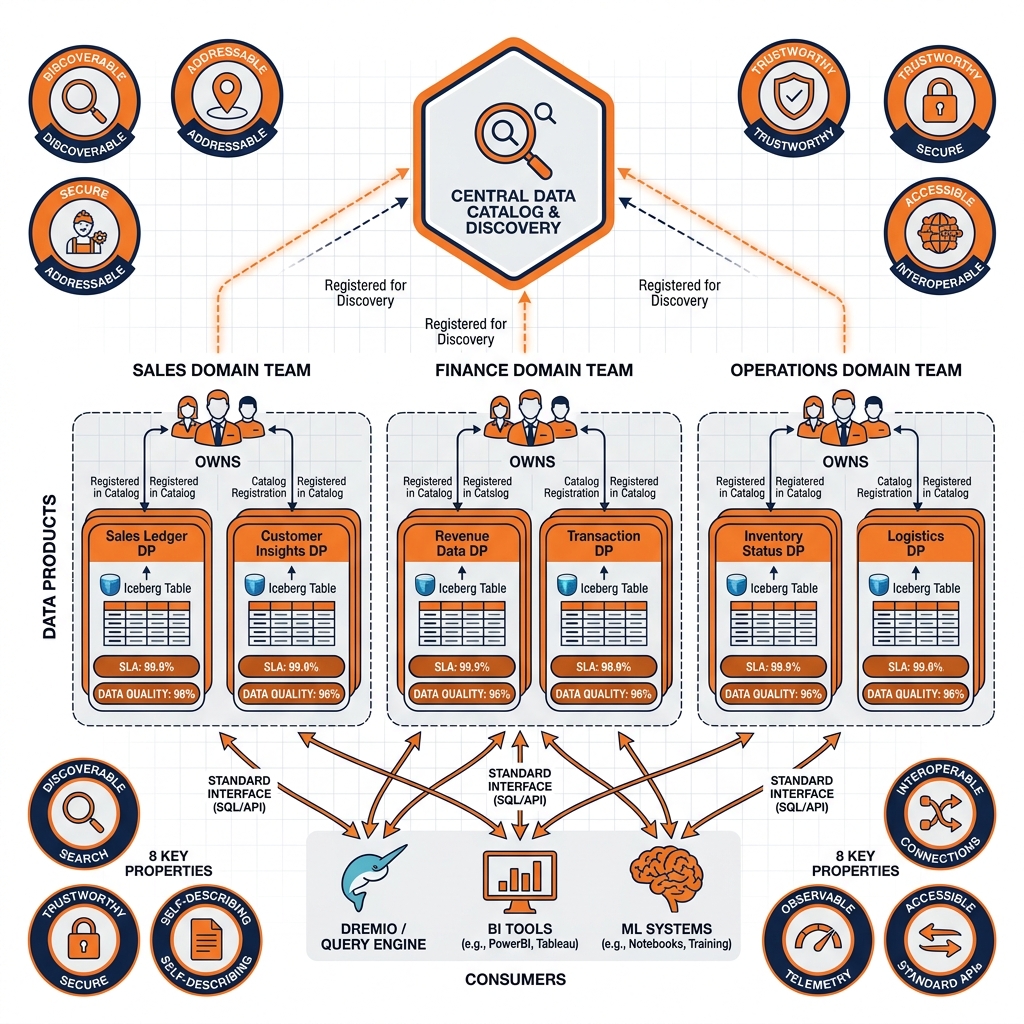
The Data Mesh framework, introduced by Zhamak Dehghani, defines data products as the primary deliverable of domain teams in a decentralized data architecture. Instead of a central data engineering team building all pipelines and tables, each domain team (Sales, Marketing, Finance, Operations) owns its own data products: the Customer 360 data product is owned and maintained by the Customer team, the Revenue Analytics data product is owned by the Finance team, and so on.
Properties of a Data Product
Zhamak Dehghani’s Data Mesh framework defines eight properties that distinguish a data product from a pipeline output.
Discoverable: The data product is registered in a central data catalog with sufficient metadata (description, schema, owner, tags, lineage) that potential consumers can find it through search without assistance.
Addressable: The data product has a stable, permanent address that consumers can use to access it. The address does not change when the underlying implementation is updated. In a lakehouse context, the Iceberg table path and catalog registration serve as the data product’s stable address.
Understandable: Consumers can understand the data product’s semantics without needing to consult the owning team. Column definitions, business glossary terms, and sample queries are documented alongside the schema.
Trustworthy: The data product publishes and maintains SLAs for data freshness (updated daily by 7 AM), quality (less than 0.1% null rate on key columns), and schema stability (30-day advance notice for breaking schema changes). Historical SLA adherence is visible to consumers.
Accessible: The data product is accessible through standard interfaces without special setup. Consumers can query it through SQL (via Dremio), access it through its Iceberg REST Catalog registration, or retrieve it through Arrow Flight.
Interoperable: The data product uses standard formats and protocols (Apache Iceberg, Parquet, Arrow Flight) so that any compliant engine can consume it.
Valuable: The data product provides genuine analytical value, not just raw pipeline output. It includes appropriate aggregations, joins, and transformations that make it immediately useful for consumers without further transformation.
Secure: The data product enforces access control, ensuring only authorized consumers can access it.
Data Products in the Iceberg Lakehouse
Apache Iceberg’s table format is the natural implementation substrate for data products in a lakehouse architecture. An Iceberg table with a catalog registration, schema documentation in the catalog, row-level security policies, and published freshness metrics represents a data product that meets the Discoverable, Addressable, Understandable, Accessible, Interoperable, and Secure properties.
Dremio’s Semantic Layer extends the data product concept to include Virtual Datasets. A Dremio Virtual Dataset built on top of an Iceberg table can serve as a higher-level data product that adds business logic transformations, column aliases with business-friendly names, pre-computed metrics, and row-level security policies, providing consumers with a richer analytical interface than the raw Iceberg table.
Data product ownership is implemented through catalog RBAC: only the owning domain team has write access to the data product’s Iceberg table and Virtual Dataset definitions in Dremio, ensuring that only the accountable team can modify the product. Consumers have read access granted through the catalog’s role hierarchy.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.