Data Mesh
A comprehensive guide to Data Mesh, a decentralized socio-technical paradigm that shifts data ownership from centralized engineering bottlenecks to distributed business domains.
The Monolithic Bottleneck
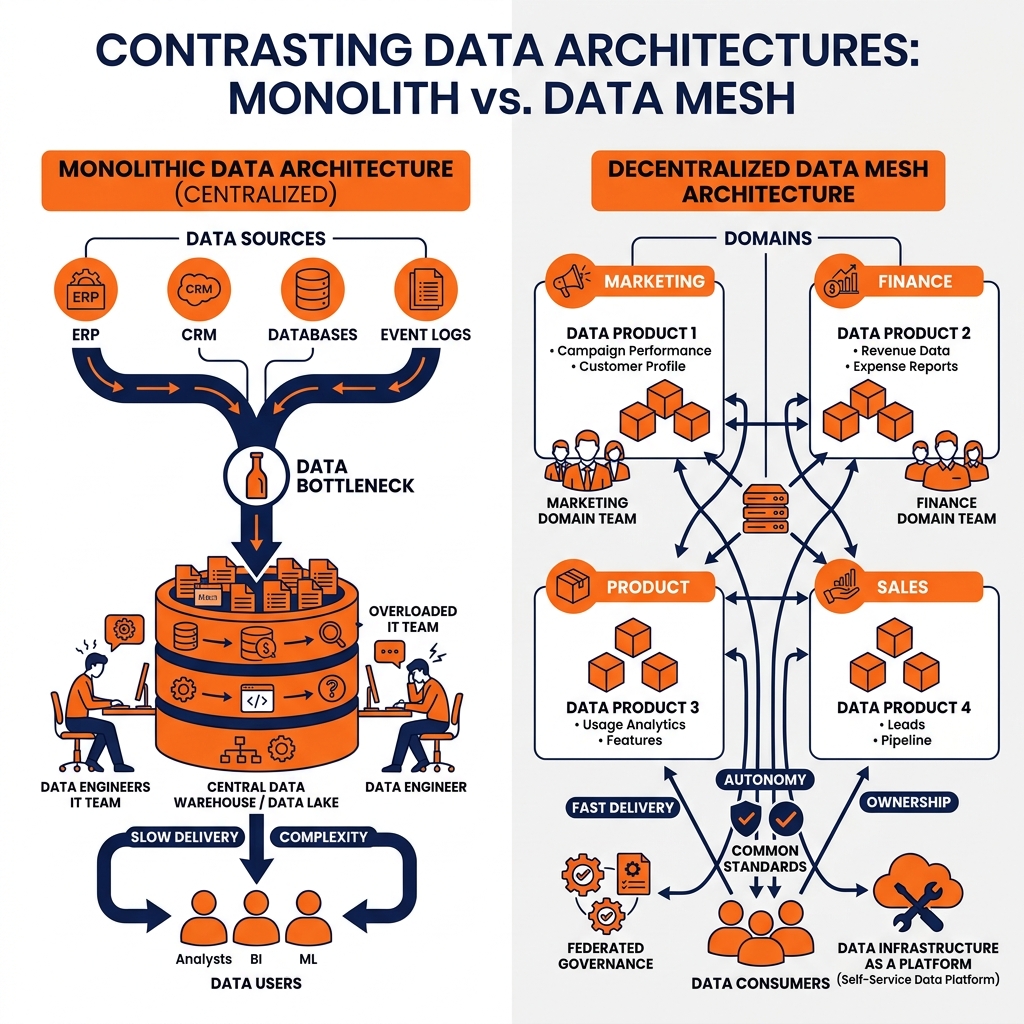
For decades, the data engineering industry operated under a singular, unquestioned assumption: all enterprise data must be centralized. The prevailing architecture-whether it was an on-premises enterprise data warehouse or a cloud-based data lake-dictated that data from every corner of the organization must be extracted, transformed, and loaded into a massive, monolithic repository managed by a single, highly specialized data engineering team.
In the early stages of a company’s growth, this centralized model functions adequately. A small team of data engineers can interface with the marketing team, the finance team, and the logistics team to build their requisite pipelines and dashboards. However, as the enterprise scales, this monolithic architecture inevitably triggers a profound organizational crisis.
The centralized data team becomes a catastrophic bottleneck. The engineers managing the central warehouse are completely divorced from the business context of the data they are ingesting. They do not understand the nuanced logic of how the logistics team calculates “shipping delay,” nor do they understand the marketing team’s definition of “campaign attribution.” When a source system changes a column name, the central pipeline breaks, and the central data team has no idea how to fix the underlying business logic without scheduling a series of meetings with the domain experts.
Consequently, the backlog of the centralized data team grows exponentially. Business units wait months for simple pipeline modifications or new data sources to be integrated. Business analysts, frustrated by the lack of agility, often resort to extracting massive CSV dumps from the warehouse and building “shadow IT” dashboards on their local laptops. The goal of the central data warehouse was to provide a single source of truth and agile business intelligence, but at scale, it reliably produces the exact opposite: gridlock, miscommunication, and untrustworthy data. The failure of this centralized paradigm necessitated a radical rethinking of how organizations manage analytical data, leading directly to the creation of the Data Mesh.
Domain-Oriented Decentralization
Data Mesh is not a technology, a specific software product, or a cloud vendor; it is a socio-technical paradigm shift. Introduced by Zhamak Dehghani, Data Mesh proposes that analytical data management should mirror the successful architectural patterns of modern software engineering, specifically microservices and Domain-Driven Design (DDD).
The foundational pillar of the Data Mesh is domain-oriented decentralization. Instead of forcing all data to flow into a central, monolithic team, data ownership is decentralized and pushed back to the specific business domains that actually generate and understand the data.
In a Data Mesh, the Marketing department is no longer just a “source” of data that throws raw logs over the wall to a central engineering team. The Marketing department becomes a fully autonomous data domain. They are entirely responsible for ingesting their own marketing telemetry, cleansing it, applying their specific business logic, and maintaining the quality of that data. If the definition of a “marketing lead” changes, the Marketing domain updates their own pipelines immediately, without waiting in a centralized IT queue.
This decentralization aligns architectural ownership with business reality. The people who understand the data best are the ones responsible for its lifecycle. A decentralized domain team typically consists of domain experts, software engineers, and dedicated data engineers embedded directly within the business unit. By eliminating the central bottleneck, organizations can scale their analytical capabilities horizontally; they can onboard ten new business domains simultaneously because each domain is autonomous and does not compete for the resources of a single central team.
If business domains are autonomously producing data, there must be a mechanism to ensure that the rest of the enterprise can actually use it. If the Logistics domain cleanses their shipping data but keeps it hidden on a private server, the enterprise gains no value. To solve this, Data Mesh introduces its second core pillar: treating Data as a Product.
Applying Product Thinking to Data
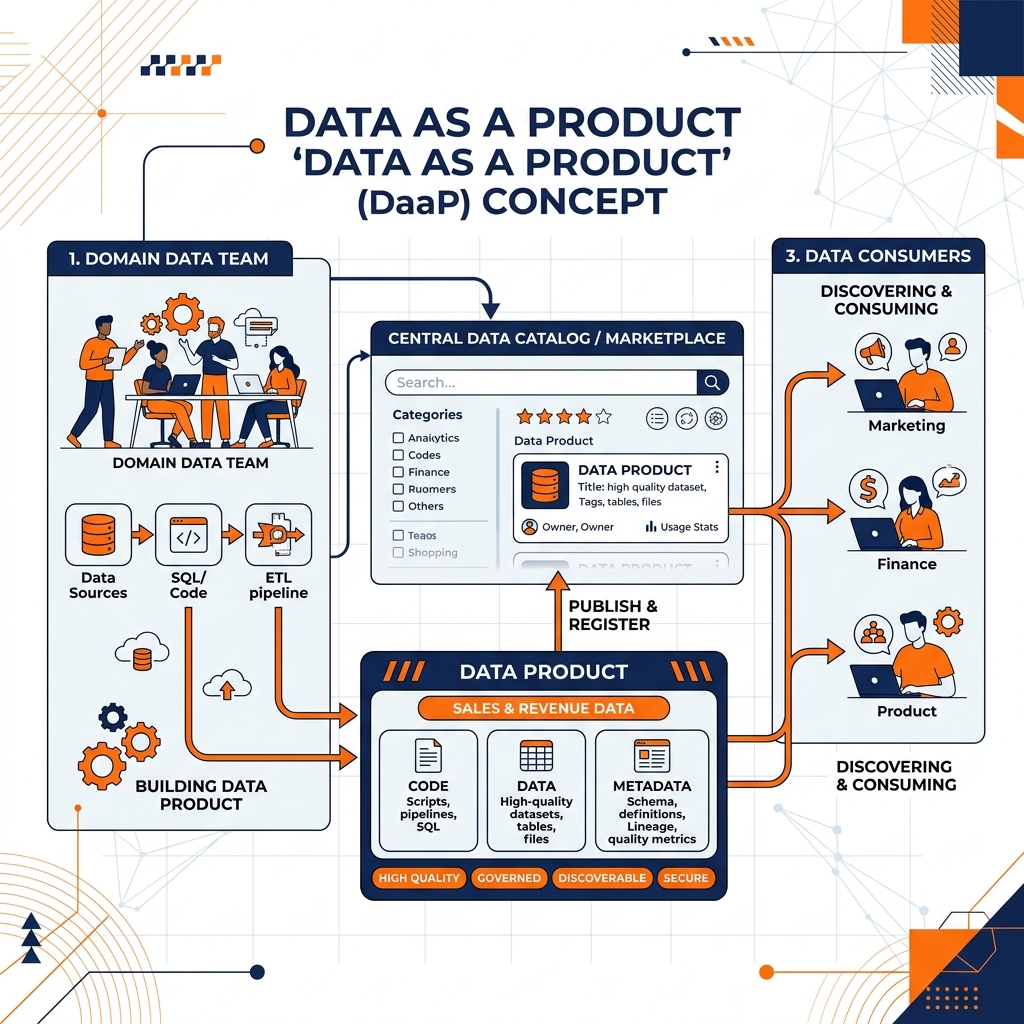
Historically, data was treated as a passive byproduct of software applications. Application developers built microservices to process e-commerce transactions, and the resulting database logs were viewed as exhaust fumes. Data Mesh demands that analytical data be elevated to the status of a first-class product, managed with the same rigor, empathy, and operational standards as any customer-facing software application.
When the Marketing domain publishes a dataset containing “Campaign Performance,” that dataset is a Data Product. The Marketing domain is the product owner, and other domains (like Finance or Executive Leadership) are their customers.
To be considered a true Data Product on the mesh, the dataset must meet strict usability standards. It must be discoverable via a central catalog. It must be addressable, meaning it has a stable, permanent location (like an S3 URI or a specific database endpoint) that will not break without notice. It must be trustworthy and adhere to published Service Level Agreements (SLAs) regarding uptime, freshness, and data quality. Most importantly, it must be self-describing; the Data Product must include comprehensive metadata, data dictionaries, and sample queries so that a data scientist in another department can understand and use the data without having to schedule a meeting with the Marketing team.
The Anatomy of a Data Product
A Data Product in a mesh architecture is not merely a table or a Parquet file. It is a logical architectural quantum that encapsulates three things: the code (the data pipelines, transformation SQL, and access APIs), the data and its metadata, and the underlying infrastructure required to run it. By packaging the code, data, and infrastructure into a single deployable unit, domain teams maintain absolute control over the quality and delivery of their product, guaranteeing that downstream consumers always receive pristine, business-ready intelligence.
Self-Serve Data Infrastructure
A critical question arises when implementing a Data Mesh: if every business domain is expected to build, host, and maintain their own complex Data Products, won’t they be crushed by the burden of managing distributed infrastructure? A Marketing team does not want to spend their time configuring Apache Kafka clusters, debugging Kubernetes networking, or provisioning Amazon S3 buckets.
To prevent domain teams from drowning in infrastructure complexity, the Data Mesh architecture relies on its third pillar: a Self-Serve Data Infrastructure Platform.
The Role of the Platform Team
In a Data Mesh, the centralized data engineering team does not disappear; they transform. Instead of writing ETL pipelines to process business data, the central team becomes a Platform Engineering team. Their sole mandate is to build and maintain a highly automated, self-serve platform that completely abstracts the underlying technical infrastructure.
This platform provides paved paths for the domain teams. If the Finance domain wants to create a new Data Product, they do not write Terraform scripts from scratch. They log into a developer portal, click a button, and the Self-Serve Infrastructure platform automatically provisions a secure S3 bucket, an Apache Iceberg namespace, a Dremio workspace, and an automated CI/CD pipeline integrated with GitHub.
The platform provides declarative interfaces for data ingestion, data quality testing, and identity management. By heavily automating the operational boilerplate, the Platform team enables domain experts to focus entirely on what they do best: writing SQL, defining business logic, and curating high-quality Data Products. The Self-Serve Infrastructure ensures that the decentralization of the Data Mesh does not result in a fragmented, unmanageable technological landscape.
Federated Computational Governance
Decentralizing data ownership across dozens of autonomous business domains introduces severe risks regarding compliance, security, and interoperability. If every domain defines their own security standards and data formats, the organization will descend into anarchy. An AI agent attempting to query data across the mesh would be blocked by a dozen different authentication protocols.
Data Mesh addresses this through its fourth pillar: Federated Computational Governance.
Federation and Standardization
Governance in a Data Mesh is federated. It is managed by a centralized governance council composed of representatives from the domain teams, the security team, and the platform team. This council does not dictate business logic; instead, they agree upon universal, global standards that every Data Product must adhere to.
These standards include interoperability rules (e.g., “All Data Products must be exposed as Apache Iceberg tables or via standard SQL endpoints”), security protocols (e.g., “All PII must be encrypted at rest and masked during query execution”), and identification standards (e.g., “Every customer record must use the global uuid format”).
Computational Enforcement
Crucially, this governance is not enforced through manual audits, PDF checklists, or bureaucratic review boards. It is computational. The global rules defined by the federated council are encoded directly into the Self-Serve Data Infrastructure Platform.
When a domain attempts to deploy a new Data Product, the CI/CD pipeline automatically executes a suite of governance checks. If the Finance domain attempts to publish a table containing credit card numbers without applying the mandatory hashing function defined by the governance council, the deployment pipeline automatically fails and blocks the release. Furthermore, access control is managed computationally through centralized catalogs like Apache Polaris. When a user requests access to a cross-domain dataset, the authorization is resolved dynamically against the global RBAC policies. This computational approach ensures that the Data Mesh remains secure, compliant, and interoperable without slowing down the autonomous delivery speed of the domain teams.
While Data Mesh is a socio-technical paradigm, it requires a highly specific technical architecture to function efficiently. Attempting to build a Data Mesh by stitching together proprietary data warehouses from different cloud vendors creates massive data silos and unacceptable network egress costs. The open Data Lakehouse provides the ideal technological foundation for a Data Mesh.
Apache Iceberg as the Open Standard
In a true Data Mesh, interoperability is paramount. If the Logistics domain builds their Data Product using a proprietary, closed database format, the Marketing domain will struggle to query it. Standardizing on Apache Iceberg as the universal table format solves this interoperability challenge.
Every domain across the organization stores their Data Products as Iceberg tables on cost-effective cloud object storage (like Amazon S3 or Azure Data Lake Storage). Because Iceberg is an open standard, it prevents vendor lock-in and guarantees that any compute engine can read the data. The Logistics domain can use Apache Flink to write streaming updates to their Iceberg tables, while the Data Science domain can use Apache Spark to train models on those exact same tables simultaneously, all governed by the ACID guarantees of the Iceberg metadata.
Dremio for Semantic Federation
While Iceberg provides the physical interoperability, organizations require a unified semantic layer to query across the distributed mesh. Dremio acts as the critical federation engine that brings the Data Mesh to life for end-users.
Because the Data Products are physically decentralized across different domain buckets, business analysts need a single pane of glass to write cross-domain queries. Dremio connects directly to the various Iceberg catalogs (such as Apache Polaris or AWS Glue) managed by the different domains.
An analyst can log into Dremio and write a single SQL query that seamlessly joins a Campaign_Performance Data Product (owned by Marketing) with a Q3_Revenue Data Product (owned by Finance). The analyst does not need to know where the files are physically stored or how to extract them. Dremio handles the federated execution, pushing the processing down to the respective domain data and returning the unified result. Furthermore, Dremio’s Data Reflections can transparently accelerate these cross-domain joins, delivering sub-second BI performance across the entire distributed architecture. By combining the organizational agility of the Data Mesh, the open standards of Apache Iceberg, and the federated semantic power of Dremio, enterprises achieve unparalleled analytical scale and flexibility.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.