Schema-on-Read
A guide to schema-on-read, the foundational big data paradigm where raw data is stored exactly as it arrives without enforcement, and the structure is only applied later when a query is actually executed.
Storing First, Structuring Later
For the first forty years of the data industry, Schema-on-Write was the absolute law. In a relational database (like PostgreSQL or an Oracle Data Warehouse), you must explicitly define the structure of a table (e.g., Column 1 is an Integer, Column 2 is a String of max 50 characters) before you can insert a single byte of data.
When data arrives, the database enforces that schema. If the incoming data does not perfectly match the predefined structure, the database rejects it. This guarantees data quality but creates a massive bottleneck: data engineers must spend months designing schemas and building rigid ETL pipelines before the business can store any new data.
With the explosion of big data (social media logs, messy JSON, IoT sensors), this rigid approach failed. Enter Schema-on-Read.
How Schema-on-Read Works
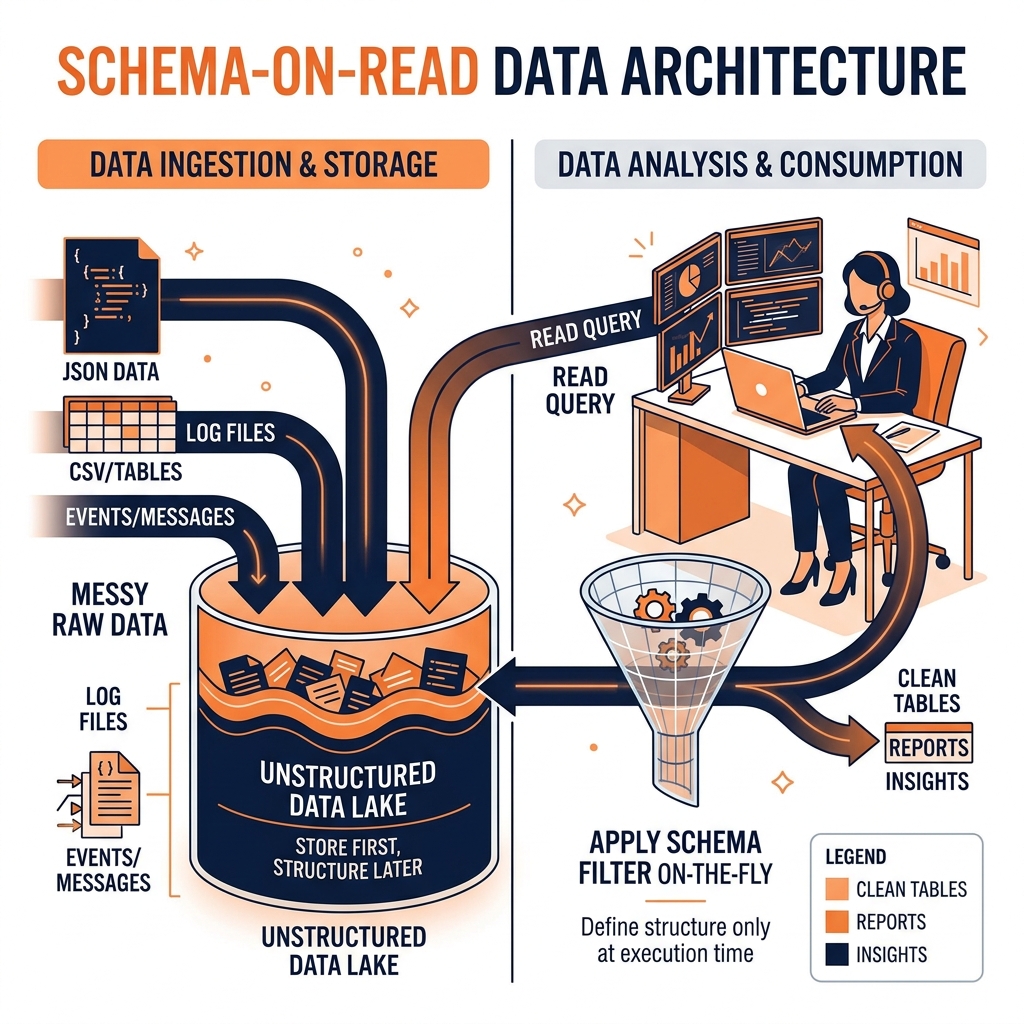
Schema-on-read is the architectural philosophy that created the Data Lake. The rule is simple: Just dump the data.
When millions of complex, nested JSON files stream in from a mobile app, the data lake (e.g., an S3 bucket) does not check or enforce a schema. It simply stores the raw files exactly as they are. This allows organizations to ingest petabytes of unstructured data instantly, without any upfront engineering effort.
The structure (the schema) is only applied later, at the exact moment a data analyst or data scientist executes a query (a “Read”).
When an analyst writes a Spark or Presto query against the raw JSON files, they define the schema in the query itself (e.g., telling the engine to treat the user_age field as an integer). If the JSON file contains extra fields the analyst doesn’t care about, the query engine simply ignores them.
The Chaos and the Cure
Schema-on-read provided ultimate flexibility, but it quickly turned Data Lakes into “Data Swamps.” Because nothing was enforced on write, the S3 buckets filled up with corrupted data, missing fields, and broken JSON files. When analysts tried to run a query (applying the schema on read), the query would crash because the underlying raw data was a chaotic mess.
The modern Data Lakehouse (using Apache Iceberg) is the cure. It brings the best of both worlds. It uses the cheap, scalable object storage of a Data Lake, but it re-introduces the strict ACID guarantees and Schema-on-Write enforcement of a traditional data warehouse. Today, raw data lands in a Bronze zone (schema-on-read), but it is quickly validated, cleaned, and written into strict Iceberg tables (schema-on-write) for reliable, high-performance analytics.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.