Retrieval-Augmented Generation (RAG)
A guide to Retrieval-Augmented Generation (RAG), the AI architecture that grounds Large Language Models in private enterprise data, preventing hallucinations and enabling domain-specific conversational analytics without model fine-tuning.
Grounding AI in Ground Truth
Large Language Models (LLMs) like GPT-4 or Claude are incredibly powerful reasoning engines, but they have two fatal flaws for enterprise use: they don’t know your company’s private data, and they confidently hallucinate answers when they lack specific knowledge.
If you ask an off-the-shelf LLM, “What is our company’s refund policy for Q3 enterprise contracts?”, it will either apologize and say it doesn’t know, or worse, invent a plausible-sounding policy based on its generalized training data.
To solve this, organizations initially tried fine-tuning LLMs on their private data. However, fine-tuning is extremely expensive, technically difficult, and doesn’t fully solve the hallucination problem (the model “memorizes” data but can’t easily cite its sources). Furthermore, fine-tuning doesn’t respect document-level access control-if the model is fine-tuned on the CEO’s private emails, it might accidentally regurgitate them to a junior employee.
Retrieval-Augmented Generation (RAG) is the architectural pattern that solves these problems by combining a search system (retrieval) with an LLM (generation).
How a RAG Pipeline Works
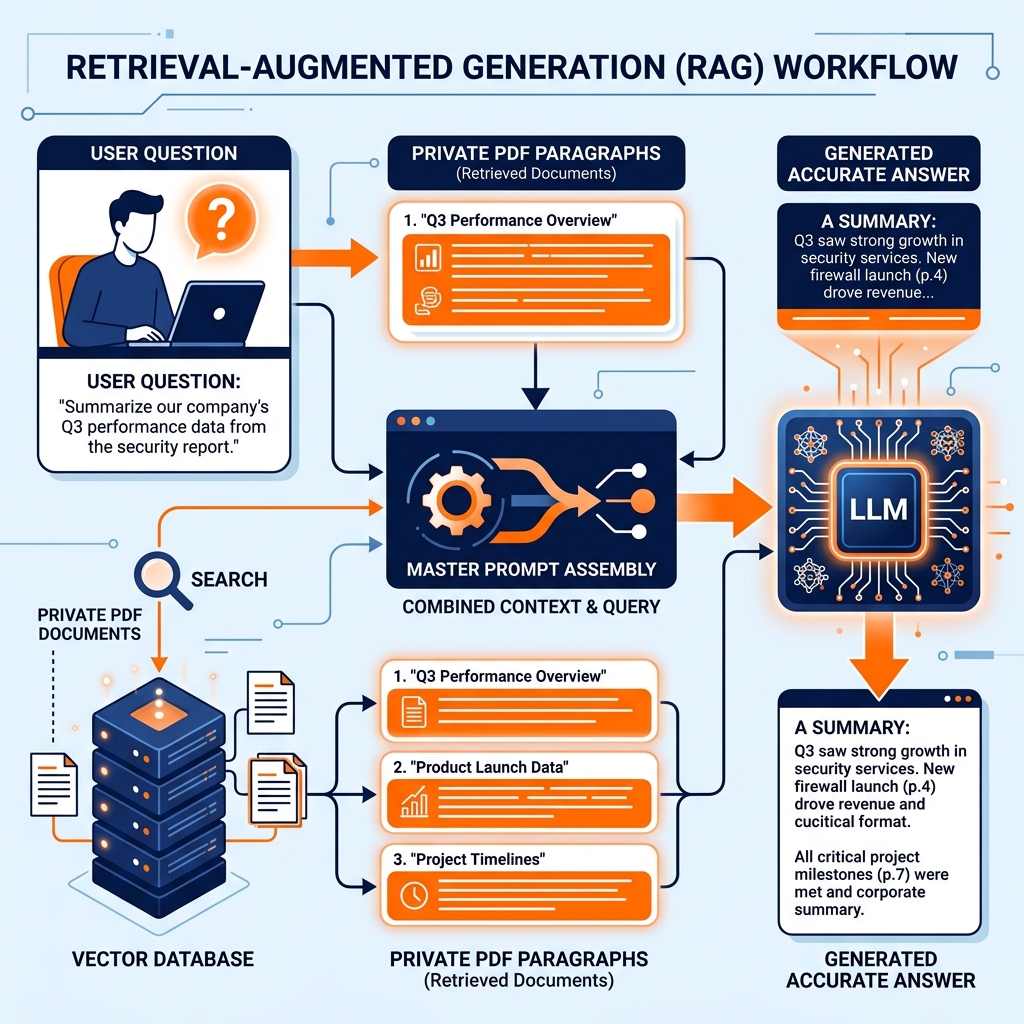
A RAG architecture separates the enterprise knowledge base from the LLM’s reasoning capabilities.
1. The Ingestion Phase: Enterprise documents (PDFs, Confluence pages, SQL schemas) are extracted, split into small chunks (e.g., 500 words each), and converted into vector embeddings using an ML model. These embeddings, along with the original text chunk and metadata (author, access permissions), are stored in a Vector Database.
2. The Retrieval Phase: When a user asks a question, the application converts the question into a vector. The Vector Database performs a semantic search to retrieve the “Top K” (e.g., the 5 most relevant) document chunks that match the meaning of the user’s question.
3. The Generation Phase: The application constructs a prompt that combines the user’s original question with the retrieved document chunks. The prompt tells the LLM: “Answer the user’s question using ONLY the following provided context. If the answer is not in the context, say ‘I don’t know’.” The LLM reads the provided enterprise context, synthesizes an answer, and returns it to the user, often citing the specific documents it used.
RAG and the Data Lakehouse
Historically, RAG was focused on unstructured text documents. The modern frontier is extending RAG to structured data - the data lakehouse.
In a “Text-to-SQL RAG” architecture, the vector database stores the schemas and business definitions of the lakehouse tables. When a user asks “What were sales in Europe last month?”, the retrieval system pulls the schema for the sales_fact table and the dim_region table. The LLM is prompted to write a SQL query based on those schemas. The application executes the generated SQL query against Dremio or Snowflake, retrieves the structured result (e.g., $4.2M), and passes that result back to the LLM to generate a natural language summary.
This convergence of GenAI and the data lakehouse is creating a new paradigm of “conversational analytics,” democratizing data access by allowing business users to interrogate petabytes of structured data using natural language, all grounded by the accuracy of the underlying Iceberg tables.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.